This is the full developer documentation for Queuert
# Queuert
> Durable, typed job chains that commit with your database transactions. A job-chain library that lives in your database — chains compose like Promises, but persist. No Redis required, no separate server.

## See it in action
[Section titled “See it in action”](#see-it-in-action)
Define a typed job chain. Each step’s input, output, and continuation are inferred — wrong-shape continuations are compile errors.
```ts
const jobTypes = defineJobTypes<{
"provision-account": {
entry: true;
input: { userId: number };
continueWith: { typeName: "send-welcome-email" };
};
"send-welcome-email": {
input: { userId: number; accountId: string };
continueWith: { typeName: "sync-to-crm" };
};
"sync-to-crm": {
input: { userId: number; accountId: string };
};
}>();
```
Start the chain *inside* your DB transaction. If the transaction rolls back, the chain is never created.
```ts
const client = await createClient({ stateAdapter, jobTypes });
await withTransactionHooks(async (transactionHooks) =>
db.transaction(async (tx) => {
const user = await tx.users.create({ name: "Alice", email: "alice@example.com" });
await client.startChain({
tx,
transactionHooks,
typeName: "provision-account",
input: { userId: user.id },
// ↑ wrong shape here is a compile error
});
}),
);
```
Each handler continues with the next step. The compiler enforces that `continueWith` matches the declared next type’s input.
```ts
const worker = await createInProcessWorker({
client,
processors: createProcessors({
client,
jobTypes,
processors: {
"provision-account": {
attemptHandler: async ({ job, complete }) => {
const accountId = await provisionAccount(job.input.userId);
return complete(async ({ continueWith }) =>
continueWith({
typeName: "send-welcome-email",
input: { userId: job.input.userId, accountId },
// ↑ missing accountId would be a compile error
}),
);
},
},
// ...handlers for "send-welcome-email" and "sync-to-crm"
},
}),
});
const stop = await worker.start();
```
## Why Queuert
[Section titled “Why Queuert”](#why-queuert)
Transactional, both ends
Enqueue commits inside your DB transaction; handler completion and next-step `continueWith` commit in the same transaction as your domain writes. For DB-bound work, no outbox and no idempotency-key ritual — both halves are structural.
Typed job chains
Inputs, outputs, continuations, and blockers infer end-to-end via `defineJobTypes`. Refactoring is compiler-checked.
Lives in your database
Postgres or SQLite. No Redis required, no workflow server, no separate persistence tier to operate.
Sub-second wakeup
`LISTEN/NOTIFY` (or Redis pub/sub, or NATS) wakes workers when a row commits — not on a polling timer.
Fan-in via blockers
“Wait for these N independent chains to finish, then run X” is a typed primitive — not glue code.
Schedule for later
Delay a chain to a specific time or duration. Schedule retries with backoff. Future work, no extra infrastructure.
Deduplication
Pass a deduplication key on enqueue. Identical keys collapse to a single chain — at-most-once, by construction.
Lean and battle-tested
Zero runtime dependencies in every package — driver libraries are `peerDependencies` you already own. 4,000+ tests across adapters and a shared conformance suite every state and notify adapter must pass.
MIT licensed
No vendor lock-in. No enterprise tier. Own your stack.
## Integrations
[Section titled “Integrations”](#integrations)
Databases
PostgreSQL · SQLite · in-process · any database via custom adapters
ORMs
Kysely · Drizzle · Prisma · any ORM via custom adapters
Drivers
pg · postgres.js · node:sqlite · better-sqlite3 · any driver via custom adapters
Notifications
Redis · PostgreSQL LISTEN/NOTIFY · NATS · in-process · any broker via custom adapters
Validation
Zod · ArkType · Valibot · TypeBox · any schema library via custom adapters
Observability
OpenTelemetry · Embeddable web UI dashboard
## Already using something else?
[Section titled “Already using something else?”](#already-using-something-else)
[vs. pg-boss ](/queuert/comparison/pg-boss/)A Postgres job queue. Different category — different shape of tool.
[vs. BullMQ ](/queuert/comparison/bullmq/)A Redis job queue. Different storage tier, different category.
[vs. Temporal ](/queuert/comparison/temporal/)A distributed workflow platform. Different category — both can model multi-step durable work.
[vs. Inngest ](/queuert/comparison/inngest/)An event-driven workflow platform. Different category, different trigger model.
## Get started
[Section titled “Get started”](#get-started)
[Introduction ](/queuert/getting-started/introduction/)What Queuert is and why it exists.
[Installation ](/queuert/getting-started/installation/)Add Queuert to your project in minutes.
[Guides ](/queuert/guides/chain-patterns/)Patterns for chains, scheduling, error handling, and more.
[Examples ](/queuert/examples/)Runnable examples for every integration and pattern.
[Comparison ](/queuert/comparison/)How Queuert relates to pg-boss, BullMQ, Temporal, and Inngest.
[Benchmarks ](/queuert/benchmarks/)Throughput and latency numbers across databases and drivers.
[Reference ](/queuert/reference/queuert/client/)Complete API reference for every module and adapter.
# Adapter Architecture
> State, notify, and observability adapter design.
## Overview
[Section titled “Overview”](#overview)
This document describes the design philosophy behind Queuert’s adapter system, including factory patterns, context management, and notification optimization.
## Provider vs Adapter
[Section titled “Provider vs Adapter”](#provider-vs-adapter)
Queuert uses a two-layer abstraction for external integrations:
* **Provider** — a minimal interface that users implement to wrap their chosen database or messaging client. It contains only low-level operations (`executeSql`, `withTransaction`, `publish`/`subscribe`). Each driver library (pg, better-sqlite3, ioredis, etc.) gets its own provider implementation.
* **Adapter** — a high-level interface that Queuert builds from a provider via a `create*` factory function. Adapters contain the full domain logic (job lifecycle, state transitions, notification semantics) and are what `createClient` and `createInProcessWorker` consume.
The factory transforms a provider into an adapter:
```plaintext
PgStateProvider → createPgStateAdapter() → StateAdapter
SqliteStateProvider → createSqliteStateAdapter() → StateAdapter
PgNotifyProvider → createPgNotifyAdapter() → NotifyAdapter
RedisNotifyProvider → createRedisNotifyAdapter() → NotifyAdapter
createNatsNotifyAdapter() → NotifyAdapter
```
This separation keeps driver-specific code isolated in the provider while the adapter layer remains database-agnostic. Users only implement the provider; they never implement the adapter interface directly.
## Conformance
[Section titled “Conformance”](#conformance)
Because each `create*` factory produces an adapter with the same contract regardless of the provider underneath, Queuert ships a **conformance suite** that validates any provider-built adapter against that contract.
The suite is exposed as a framework-agnostic runner under the `queuert/conformance` subpath. Users wire it into a single `test()` block from their framework of choice; internal Queuert specs go through the same case list via a thin vitest binding so there’s no drift between end-user validation and internal coverage.
See the [Conformance reference](/queuert/reference/queuert/conformance/) for the API and the [Custom Adapters](/queuert/advanced/custom-adapters/) guide for a walkthrough.
## Async Factory Pattern
[Section titled “Async Factory Pattern”](#async-factory-pattern)
Public-facing adapter factories that may perform I/O are async for consistency. In-process and internal-only factories remain sync since they have no I/O.
### Rationale
[Section titled “Rationale”](#rationale)
1. **Consistency**: All public factories follow the same async pattern, reducing cognitive load
2. **Future-proofing**: Factories can add initialization I/O without breaking API
3. **Explicit async**: Callers know to `await` and handle potential errors
## StateAdapter Design
[Section titled “StateAdapter Design”](#stateadapter-design)
### Atomic Operations Principle
[Section titled “Atomic Operations Principle”](#atomic-operations-principle)
All StateAdapter methods must complete in a **single database round-trip**, where the database engine supports it. This is a core design principle:
* **O(1) round trips**: Each method—regardless of how many jobs it affects—executes exactly one database operation
* **O(n) is incorrect**: If an adapter implementation requires multiple round trips proportional to input size, the implementation is wrong
* **Batch operations**: Methods accepting arrays (e.g., `deleteChains`, `addJobBlockers`) must use batch SQL (multi-row INSERT, UPDATE with IN clause, CTEs) rather than loops
This principle ensures predictable performance and proper atomicity. Use batch SQL (multi-row INSERT, UPDATE with IN/ANY clause, CTEs) rather than loops.
**SQLite exception**: SQLite does not support writeable CTEs with RETURNING in the same way as PostgreSQL. Operations like `addJobBlockers` and `deleteChains` use multiple sequential queries within a single transaction instead of a single CTE. This is safe under SQLite’s exclusive transaction locking model (which serializes all writes), but results in more round-trips per operation. This is an accepted trade-off for SQLite support.
### Context Architecture
[Section titled “Context Architecture”](#context-architecture)
The `StateAdapter` type accepts two generic parameters: `TTxContext` (transaction context containing database client/session info) and `TJobId` (the job ID type for input parameters).
The context is named `TTxContext` (transaction context) because it’s exclusively used within transactions. When you call `withTransaction`, the callback receives a context that represents an active transaction.
### StateProvider Interface
[Section titled “StateProvider Interface”](#stateprovider-interface)
Users create a `StateProvider` implementation to integrate with their database client. The concrete interfaces live in `@queuert/postgres` and `@queuert/sqlite`; the shape below is an illustrative reduction — see the TSDoc on `PgStateProvider` and `SqliteStateProvider` for the authoritative signatures (including `paramTypes`/`columnTypes` annotations required by the typed-SQL layer).
```typescript
interface PgStateProvider {
// Manages connection and transaction - called for transactional operations
withTransaction: (fn: (txCtx: TTxContext) => Promise) => Promise;
// Execute SQL - when txCtx is provided uses it, when omitted manages own connection
executeSql: (options: {
txCtx?: TTxContext;
sql: string;
params?: unknown[];
paramTypes: Record;
columnTypes: Record;
}) => Promise;
// Optional — only define when the provider owns resources beyond the caller-supplied client/pool
close?: () => Promise;
}
```
### Optional txCtx Semantics
[Section titled “Optional txCtx Semantics”](#optional-txctx-semantics)
All `StateAdapter` operation methods accept an optional `txCtx` parameter:
* **With txCtx**: Uses the provided transaction connection (must come from a `withTransaction` callback)
* **Without txCtx**: Acquires its own connection from the pool, executes, and releases
This enables transactional operations, standalone operations, and DDL operations (like `CREATE INDEX CONCURRENTLY`) that cannot run inside transactions.
### NotifyProvider Interface
[Section titled “NotifyProvider Interface”](#notifyprovider-interface)
NotifyProvider implementations manage connections internally - no context parameters:
```typescript
interface PgNotifyProvider {
publish: (channel: string, message: string) => Promise;
subscribe: (
channel: string,
onMessage: (message: string) => void,
) => Promise<() => Promise>;
// Optional — only define when the provider owns resources (e.g. a dedicated LISTEN client)
close?: () => Promise;
}
```
The provider maintains a dedicated connection for subscriptions and acquires/releases connections for publish operations automatically.
### Reaper Support
[Section titled “Reaper Support”](#reaper-support)
The `reapExpiredJobLease` method supports an `ignoredJobIds` parameter to prevent race conditions when a worker runs with multiple concurrent slots (`concurrency > 1`). Without it, a worker could reap its own in-progress job if the lease expires before renewal, causing corrupted state. Custom adapter implementations must filter out these job IDs when selecting expired leases.
### Internal Type Design
[Section titled “Internal Type Design”](#internal-type-design)
`StateJob` is a non-generic type with `string` for all ID fields. The `StateAdapter` methods accept `TJobId` for input parameters but return plain `StateJob`. This simplifies internal code while allowing adapters to expose typed IDs to consumers via type helpers like `GetStateAdapterJobId`.
## NotifyAdapter Design
[Section titled “NotifyAdapter Design”](#notifyadapter-design)
### Broadcast Semantics
[Section titled “Broadcast Semantics”](#broadcast-semantics)
All notifications use broadcast (pub/sub) semantics with three notify/listen pairs: job scheduling, chain completion, and ownership loss. See the `NotifyAdapter` type TSDoc for method details.
### Wake-Hint Methods
[Section titled “Wake-Hint Methods”](#wake-hint-methods)
To prevent thundering herd when many workers are idle, the publisher attaches a per-typeName budget that gates how many listeners actually wake. Hints are an opt-in pair of methods on `NotifyAdapter`, both keyed by `typeName`:

* `provideWakeHint(typeName, count)` — publisher adds `count` to the budget. Composes additively across concurrent publishers (two `provideWakeHint(t, 3)` calls yield a budget of 6).
* `consumeWakeHint(typeName)` — listener atomically claims one slot. Returns `true` if a slot was claimed, or if no budget is currently tracked (graceful degradation). Returns `false` only when an explicit budget was set and is now exhausted.
Flow when scheduling N jobs of `typeName`:
1. Publisher calls `provideWakeHint(typeName, N)` followed by `notifyJobScheduled(typeName)`.
2. Each receiving worker calls `consumeWakeHint(typeName)`. The first N return `true` (worker queries the database); subsequent calls return `false` (worker skips).
3. When the hint key never existed or the TTL expired, `consumeWakeHint` falls back to `true` so listeners don’t silently miss wakeups.
Adapters that don’t support hints implement the pair as no-ops (`provideWakeHint: async () => {}`, `consumeWakeHint: async () => true`) — no parameter lies, no thundering-herd protection, but everything else still works.
Implementation varies by adapter:
* **Redis**: Lua scripts. `PROVIDE_WAKE_HINT_SCRIPT` reads the current value and writes `current + count` with a 60s TTL refresh; `CONSUME_WAKE_HINT_SCRIPT` performs the atomic decrement with graceful-degradation on missing keys.
* **NATS with JetStream KV**: revision-based CAS retry loops for both add and decrement.
* **PostgreSQL / NATS without KV**: hint methods are no-ops; every listener wakes and the database (FOR UPDATE SKIP LOCKED in `acquireJob`) handles contention.
* **In-process**: synchronous counter operations on a `Map`.
Atomicity note: `provideWakeHint` and `notifyJobScheduled` are two separate calls. If `notifyJobScheduled` fails after `provideWakeHint` succeeds, the budget is consumed by the *next* notification for that typeName (slight over-wake on the next batch, harmless). If `provideWakeHint` fails, the publish doesn’t happen (the buffered helper short-circuits on the first throw).
### Callback Pattern
[Section titled “Callback Pattern”](#callback-pattern)
All `listen*` methods accept a callback and return a dispose function. Subscription is active when the promise resolves, and the callback is called synchronously when notifications arrive (no race condition).
## Lifecycle and Teardown
[Section titled “Lifecycle and Teardown”](#lifecycle-and-teardown)
Both `StateAdapter` and `NotifyAdapter` expose `close(): Promise`. The contract:
* **Idempotent** — calling `close()` a second time is a no-op.
* **Cascades into the provider when defined** — `adapter.close()` invokes `provider.close?.()`. Provider `close` is optional, so pass-through providers (postgres.js state, `pg.Pool` state, `better-sqlite3`/`node:sqlite` state, postgres.js notify, user-owned redis clients) simply omit it. Only providers that own resources beyond the caller-supplied client/pool (e.g. the `pg.Pool` notify provider with its dedicated LISTEN client) need to implement it.
* **Force-tears shared listeners** — `NotifyAdapter.close()` tears down the pg/redis/nats shared-listener multiplex regardless of remaining callbacks, waits for any in-flight `subscribe` to complete, then releases the provider’s dedicated LISTEN/subscribe client.
* **Post-close behavior** — after close, `notify*`/`listen*`/`publish`/`subscribe` reject. Previously returned unsubscribe functions are safe to call (no-op).
Recommended teardown order:
```ts
await stopWorker(); // 1. Stop polling, drain in-flight jobs
await notifyAdapter.close(); // 2. Unsubscribe listeners, release LISTEN client
await stateAdapter.close(); // 3. Release state-provider resources (if any)
await pool.end(); // 4. Finally, close caller-owned clients/pools
```
## ObservabilityAdapter Design
[Section titled “ObservabilityAdapter Design”](#observabilityadapter-design)
The `ObservabilityAdapter` provides two observability mechanisms:
1. **Metrics**: Methods accept primitive data types (not domain objects) for decoupling and stability. Counters, histograms, and gauges track worker lifecycle, job events, and durations.
2. **Tracing**: `startJobSpan` and `startAttemptSpan` methods return handles for managing span lifecycle. Spans follow OpenTelemetry messaging conventions with PRODUCER spans for job creation and CONSUMER spans for processing.
When no adapter is provided, a noop implementation is used automatically, making observability opt-in. See [OTEL Tracing](../otel-tracing/) for span hierarchy and [OTEL Metrics](../otel-metrics/) for available metrics. See [OTEL Internals](../otel-internals/) for adapter architecture and trace context propagation.
### Transactional Buffering
[Section titled “Transactional Buffering”](#transactional-buffering)
Observability events emitted inside database transactions are buffered and only flushed after the transaction commits. If the transaction rolls back, buffered events are discarded — no misleading metrics or spans leak out. Buffering uses `TransactionHooks` — the same mechanism that flushes notify events on commit.
**Buffered** — events that represent write claims inside transactions:
* **Creation**: `chainCreated`, `jobCreated`, `jobBlocked`, and PRODUCER span ends from `createStateJobs`
* **Completion**: `jobCompleted`, `jobDuration`, `completeJobSpan` (workerless), `chainCompleted`, `chainDuration`, `completeBlockerSpan`, `jobUnblocked` from `finishJob`
* **Worker complete**: `jobAttemptCompleted` and continuation PRODUCER span ends from the complete transaction in `job-process`
* **Error handling**: `jobAttemptFailed` from the error-handling transaction in `job-process`
**Not buffered** — events that either need immediate context or occur outside transactions:
* **Span starts**: Need trace context immediately for DB writes that store trace IDs
* **Events outside transactions**: `jobAttemptStarted`, `jobAttemptDuration`, `jobAttemptLeaseRenewed`, attempt span ends (these occur outside the guarded transaction)
* **Read-only observations**: `refetchJobLocked` events observe state without making write claims
### Self-Cleaning
[Section titled “Self-Cleaning”](#self-cleaning)
Both `createStateJobs` and `finishJob` use `TransactionHooks` savepoints (via `withSavepoint`) to automatically roll back buffered observability events on throw, ensuring partial events from a failed operation don’t accumulate in the buffer. The `checkpoint` callback on each hook definition captures the buffer position, and the savepoint restores it on rollback.
## See Also
[Section titled “See Also”](#see-also)
* [OTEL Metrics](../otel-metrics/) — Counters, histograms, and gauges
* [OTEL Tracing](../otel-tracing/) — Span hierarchy and messaging conventions
* [OTEL Internals](../otel-internals/) — Adapter architecture, W3C context propagation, and transactional buffering
* [Client API](/queuert/reference/queuert/client/) — Mutation and query methods
* [In-Process Worker](../in-process-worker/) — Worker lifecycle and lease management
# Chain Model
> Promise-like chain model, identity, and execution patterns.
## Overview
[Section titled “Overview”](#overview)
This document describes Queuert’s unified job model and the Promise-inspired chain abstraction.
## Core Concepts
[Section titled “Core Concepts”](#core-concepts)
### Job
[Section titled “Job”](#job)
A **Job** is an individual unit of work with a lifecycle:
```plaintext
blocked/pending → running → completed
```
Each job:
* Belongs to a **Job Type** that defines its input/output schema
* Contains typed input data and (when completed) output data
* Can `continueWith` to create a linked follow-up job
* Can depend on **blockers** (other chains that must complete first)
### Chain
[Section titled “Chain”](#chain)
A **Chain** is a series of linked jobs where each job can continue to the next—just like a JavaScript Promise chain.
```plaintext
Job A → Job B → Job C → (completed)
```
The chain completes when its final job completes without continuing.
## The Promise Analogy
[Section titled “The Promise Analogy”](#the-promise-analogy)
The design mirrors JavaScript Promises:
```javascript
// JavaScript: A Promise chain IS the first promise
const chain = fetch(url) // chain === this promise
.then(processResponse) // continuation
.then(formatResult); // continuation
// Queuert: A Chain IS its first job
const chain = startChain(...) // chain.id === firstJob.id
.continueWith(processStep) // continuation
.continueWith(formatStep); // continuation
```
The fundamental insight: **the first job IS the chain**. Chains work like Promises but persist across process restarts and distribute across workers.
## Identity Model
[Section titled “Identity Model”](#identity-model)
For the first job in a chain: `job.id === job.chainId`
This isn’t redundant—it’s a meaningful signal that identifies the chain starter. Continuation jobs have `job.id !== job.chainId` but share the same `chainId` as all other jobs in the chain.

## Unified Model Benefits
[Section titled “Unified Model Benefits”](#unified-model-benefits)
Having the first job BE the chain (rather than a separate entity) provides:
### Simplicity
[Section titled “Simplicity”](#simplicity)
* One table, one type, one set of operations
* No separate `chain` table to manage
* No joins, no synchronization issues
### Flexibility
[Section titled “Flexibility”](#flexibility)
The first job can be:
* A lightweight “alias” that immediately continues to real work
* A full job that processes and completes the chain in one step
* Anything in between
### Performance
[Section titled “Performance”](#performance)
* `chainTypeName` denormalized on every job for O(1) filtering
* No subqueries needed to find chains by type
* Efficient at scale (millions of jobs)
## Execution Patterns
[Section titled “Execution Patterns”](#execution-patterns)
Chains support various patterns via `continueWith`:
### Linear
[Section titled “Linear”](#linear)
```plaintext
A → B → C → done
```
### Branched
[Section titled “Branched”](#branched)
```plaintext
A → B1 (if condition)
→ B2 (else)
```
### Loop
[Section titled “Loop”](#loop)
```plaintext
A → A → A → done
```
### Go-to (jump back)
[Section titled “Go-to (jump back)”](#go-to-jump-back)
```plaintext
A → B → A → B → done
```
## Blockers: Chain Dependencies
[Section titled “Blockers: Chain Dependencies”](#blockers-chain-dependencies)
Chains can depend on other chains to complete before starting:
```plaintext
┌──────────────┐
│ Blocker A │───┐
└──────────────┘ │
├──→ Main Chain (blocked until A and B complete)
┌──────────────┐ │
│ Blocker B │───┘
└──────────────┘
```
Blockers are declared at the type level and provided via the `blockers` array when creating a chain. The main job starts as `blocked` and transitions to `pending` when all blockers complete.
## Consistent Terminology
[Section titled “Consistent Terminology”](#consistent-terminology)
Parallel entities use consistent lifecycle terminology to reduce cognitive load:
* Job: `blocked`/`pending` → `running` → `completed`
* Chain: `blocked`/`pending` → `running` → `completed` (reflects status of current job in chain)
Avoid asymmetric naming (e.g., `started`/`finished` vs `created`/`completed`) even if individual terms seem natural. Consistency across the API produces fewer questions and faster comprehension.
## Summary
[Section titled “Summary”](#summary)
The Chain model:
1. **Mirrors Promises**: Familiar mental model for JavaScript developers
2. **Unified identity**: The first job IS the chain—no separate entity
3. **Single table**: Jobs and chains share storage; `chainId` links them
4. **Flexible patterns**: Linear, branched, looped, or jumping execution
5. **Distributed**: Unlike Promises, chains persist and distribute across workers
# Custom Adapters
> Write your own state, notify, or validation adapter for any database client, message broker, or schema library and validate it with Queuert's conformance suite.
Queuert’s adapter system is designed to be extended. You can implement the `StateAdapter` or `NotifyAdapter` interface from scratch for your own backend — a different database engine, message broker, or anything else. You can also write a **validation adapter** wrapping any schema library (Zod, Valibot, ArkType, TypeBox, or your own). The conformance suite validates that your implementation behaves correctly. It’s the same suite Queuert uses internally, exposed as a framework-agnostic runner you embed in a single `test()` block.
## Custom NotifyAdapter
[Section titled “Custom NotifyAdapter”](#custom-notifyadapter)
Implement the `NotifyAdapter` type exported from `queuert`. The interface has three notification channels (job scheduled, chain completed, ownership lost), each with a publish and a subscribe method, plus a `provideWakeHint`/`consumeWakeHint` pair that gates how many listeners actually wake on a job-scheduled notification (no-op for adapters without a counter primitive — see [Adapter Architecture](/queuert/advanced/adapters/#wake-hint-methods)) and a `close()` for releasing internal resources:
```ts
import { runNotifyAdapterConformance } from "queuert/conformance";
import { test } from "vitest";
import { createMyNotifyAdapter } from "./my-notify-adapter.js";
test("custom notify adapter passes conformance", async () => {
await runNotifyAdapterConformance(async () => {
const notifyAdapter = createMyNotifyAdapter();
return {
notifyAdapter,
dispose: async () => {
/* teardown */
},
};
});
}, 60_000);
```
See the [Notify adapter examples](/queuert/examples/#notify-adapters) for end-to-end integrations across Redis, NATS, and PostgreSQL.
## Custom StateAdapter
[Section titled “Custom StateAdapter”](#custom-stateadapter)
Implement the `StateAdapter` type exported from `queuert`. This is a larger interface covering job creation, status transitions, leasing, querying, and migrations. See the [Adapter Architecture](/queuert/advanced/adapters/) doc for the full contract and the [Conformance reference](/queuert/reference/queuert/conformance/) for what the suite tests.
```ts
import { runStateAdapterConformance } from "queuert/conformance";
import { test } from "vitest";
import { createMyStateAdapter } from "./my-state-adapter.js";
test("custom state adapter passes conformance", async () => {
await runStateAdapterConformance(async () => {
const stateAdapter = createMyStateAdapter();
return {
stateAdapter,
reset: async () => {
/* truncate tables */
},
dispose: async () => {
/* teardown */
},
};
});
}, 300_000);
```
See the [State adapter examples](/queuert/examples/#state-adapters) for end-to-end integrations across PostgreSQL and SQLite.
## Custom validation adapter
[Section titled “Custom validation adapter”](#custom-validation-adapter)
Validation adapters are thin wrappers around schema libraries that produce a `JobTypes` registry. The conformance suite checks that:
* The adapter’s six runtime methods (`getTypeNames`, `validateEntry`, `parseInput`, `parseOutput`, `validateContinueWith`, `validateBlockers`) behave correctly.
* Schema validation failures are wrapped in `JobTypeValidationError` with the right `code`, `typeName`, `cause`, and `details`.
* The schema-to-shape inference (`z.infer`, `Static<>`, `T["infer"]`, `v.InferOutput`, etc.) threads through to the phantom job type definitions correctly.
The last point is enforced **at compile time**: each builder in the fixture has a precise return type, so an inference bug in your adapter trips a TypeScript error at the call site of `runValidationAdapterConformance` — before the runtime suite even executes.
```ts
import { runValidationAdapterConformance } from "queuert/conformance";
import { test } from "vitest";
import { createMyJobTypes } from "./my-validation-adapter.js";
test("custom validation adapter passes conformance", async () => {
await runValidationAdapterConformance(async () => ({
basic: {
buildEntry: () =>
createMyJobTypes({
main: {
entry: true,
input: schema({ id: "string" }),
output: schema({ ok: "boolean" }),
},
}),
buildNonEntry: () => createMyJobTypes(/* ... */),
buildContinuationOnly: () => createMyJobTypes(/* ... */),
},
continuations: {
buildNominal: () => createMyJobTypes(/* ... */),
buildStructural: () => createMyJobTypes(/* ... */),
},
blockers: {
buildNominal: () => createMyJobTypes(/* ... */),
buildStructural: () => createMyJobTypes(/* ... */),
},
external: {
buildWithExternalSlice: () => createMyJobTypes(/* ... */),
},
}));
});
```
The exact phantom shape each builder must produce is encoded in the [`ValidationConformanceFixture`](https://github.com/kvet/queuert/blob/main/packages/core/src/conformance/validation-adapter-cases.ts) type.
See the [Validation adapter examples](/queuert/examples/#validation) for end-to-end integrations across Zod, Valibot, ArkType, and TypeBox.
## Running under other test frameworks
[Section titled “Running under other test frameworks”](#running-under-other-test-frameworks)
The runner is framework-agnostic — it throws on failure. Any framework that reports a thrown error as a test failure will work.
### bun test
[Section titled “bun test”](#bun-test)
```ts
import { test } from "bun:test";
import { runStateAdapterConformance } from "queuert/conformance";
test(
"custom state adapter passes conformance",
async () => {
await runStateAdapterConformance(async () => /* … */);
},
{ timeout: 300_000 },
);
```
### node:test
[Section titled “node:test”](#nodetest)
```ts
import test from "node:test";
import { runStateAdapterConformance } from "queuert/conformance";
test(
"custom state adapter passes conformance",
{ timeout: 300_000 },
async () => {
await runStateAdapterConformance(async () => /* … */);
},
);
```
### mocha / jest / jasmine
[Section titled “mocha / jest / jasmine”](#mocha--jest--jasmine)
Same shape — wrap the `await runStateAdapterConformance(...)` call in whatever `it()` or `test()` your framework provides. Raise the per-test timeout to `300_000` for state conformance (notify conformance fits inside 60s).
## What happens on failure
[Section titled “What happens on failure”](#what-happens-on-failure)
On any case failure the runner throws a `ConformanceError` whose message summarizes which cases failed plus their assertion messages:
```plaintext
ConformanceError: 2/132 conformance cases failed (130 passed, 0 skipped)
x createJobs > preserves provided chainId
expected 'chain-abc' to be 'chain-xyz'
x addJobsBlockers > marks job blocked when incomplete blockers present
expected 'pending' to be 'blocked'
```
`err.cause` is an `AggregateError` holding the original thrown errors with full stacks, so IDEs and CI viewers can jump to the failing case source line inside `queuert/conformance`.
For per-case progress, supply an `onResult` callback:
```ts
await runNotifyAdapterConformance(factory, {
onResult: (result) => {
console.log(`${result.status === "pass" ? "✓" : "✗"} ${result.name}`);
},
});
```
## See Also
[Section titled “See Also”](#see-also)
* [Conformance API Reference](/queuert/reference/queuert/conformance/) — full runner and type signatures
* [State Adapters](/queuert/integrations/state-adapters/) — supported drivers and provider interface
* [Notify Adapters](/queuert/integrations/notify-adapters/) — supported clients and provider interface
* [Adapter Architecture](/queuert/advanced/adapters/) — design philosophy and factory patterns
# Dashboard Internals
> API endpoints, SolidJS frontend, and deployment architecture of the dashboard.
## Overview
[Section titled “Overview”](#overview)
This document describes the internal implementation of `@queuert/dashboard` — its API layer, frontend architecture, and how it integrates with the Queuert client. The dashboard is a self-contained web application that ships as a single fetch handler with pre-built frontend assets embedded in the package.
## Architecture
[Section titled “Architecture”](#architecture)
```plaintext
HTTP Request
↓
await createDashboard({ client, basePath })
↓
fetch(request) → Response
├── /api/* → JSON API (reads from state adapter)
└── /assets/* → Pre-built SolidJS SPA
```
The dashboard accepts a Queuert `Client` instance and returns a `{ fetch }` object compatible with any server that handles the Web Fetch API (`Request` → `Response`).
## API Endpoints
[Section titled “API Endpoints”](#api-endpoints)
All API endpoints are read-only except `POST /api/jobs/{jobId}/trigger` and `DELETE /api/chains/{chainId}`. They query the state adapter through the Queuert client.
### Chain Endpoints
[Section titled “Chain Endpoints”](#chain-endpoints)
**`GET /api/chains`** — List chains with filtering and pagination.
| Parameter | Type | Description |
| ---------- | ----- | ----------------------------------------------------------------- |
| `typeName` | query | Filter by chain type name |
| `status` | query | Filter by status |
| `root` | query | Return only root chains (default `true`; pass `false` to disable) |
| `id` | query | Filter by chain ID |
| `jobId` | query | Filter by job ID within chain |
| `cursor` | query | Pagination cursor |
| `limit` | query | Page size |
Returns an array of `[rootJob, lastJob]` pairs and a `nextCursor` for pagination.
**`GET /api/chains/{chainId}`** — Get chain detail with full job sequence.
Returns the root job, last job, all jobs in the chain ordered by chain index, and a map of job blockers.
**`GET /api/chains/{chainId}/blocking`** — List jobs from other chains that depend on this chain as a blocker.
### Job Endpoints
[Section titled “Job Endpoints”](#job-endpoints)
**`GET /api/jobs`** — List individual jobs with filtering and pagination.
| Parameter | Type | Description |
| --------------- | ----- | ------------------------- |
| `status` | query | Filter by status |
| `typeName` | query | Filter by job type name |
| `chainTypeName` | query | Filter by chain type name |
| `chainId` | query | Filter by chain ID |
| `id` | query | Filter by job ID |
| `cursor` | query | Pagination cursor |
| `limit` | query | Page size |
**`GET /api/jobs/{jobId}`** — Get job detail with continuation and blockers.
**`POST /api/jobs/{jobId}/trigger`** — Trigger a pending job scheduled for the future. Sets `scheduled_at` to now and notifies the notify adapter. Only works for jobs with status `pending`.
### Chain Mutation Endpoints
[Section titled “Chain Mutation Endpoints”](#chain-mutation-endpoints)
**`DELETE /api/chains/{chainId}?cascade=true`** — Delete a chain and all its jobs. Pass `cascade=true` to also delete all transitive blocker chains. Returns the deleted chains on success. Returns 404 if the chain does not exist. Returns 409 if other jobs depend on the resolved deletion set as a blocker (`BlockerReferenceError`).
### Asset Serving
[Section titled “Asset Serving”](#asset-serving)
**`GET /assets/*`** — Serves pre-built frontend assets (JavaScript, CSS) with appropriate content types.
**`GET /`** (and all non-API paths) — Serves the SPA `index.html` with a dynamically injected `` tag matching the configured `basePath`. This enables client-side routing to work correctly behind reverse proxies.
## Query Performance
[Section titled “Query Performance”](#query-performance)
The chain listing endpoint (`GET /api/chains`) joins each root row with the last job in the chain. Filtering by `status` is not optimized — it applies to the joined last job and cannot use an index. Always pass `typeName` to narrow the scan. See [Performance considerations](/queuert/guides/queries/#performance-considerations).
## Frontend
[Section titled “Frontend”](#frontend)
The frontend is a SolidJS single-page application built with Vite.
### Views
[Section titled “Views”](#views)
**Chain List** (`/`) — Default view showing all chains ordered by creation time (newest first). Each chain displays as a card with type name, chain ID, status badge, last job type, attempt count, and input preview. Supports filtering by chain ID, job ID, type name, and status. Includes cursor-based “Load more” pagination.
**Chain Detail** (`/chains/:id`) — Full job sequence within a chain. Shows each job as a card with input/output JSON, blocker dependencies with links to blocker chains, and a “Blocking” section listing jobs from other chains that depend on this chain.
**Job List** (`/jobs`) — Cross-chain view of individual jobs with the same filtering and pagination patterns as the chain list.
**Job Detail** (`/jobs/:id`) — Detailed job view with status, timing information, worker/lease details, blockers, input/output data, continuation link, and error details. Shows a “Trigger” button for pending jobs scheduled in the future.
### Build and Embedding
[Section titled “Build and Embedding”](#build-and-embedding)
The frontend is compiled during package build, not at deploy time:
1. Vite compiles the SolidJS app to static assets in `dist/frontend/`
2. A build plugin reads the compiled assets and generates a TypeScript file (`assets.generated.ts`) containing all assets as string constants
3. The backend build (tsdown) bundles everything — including the embedded assets — into a single distributable file
This means the published package requires no frontend build tools, no `node_modules` for the frontend, and no separate static file serving. The entire dashboard is a single JavaScript module.
## basePath Support
[Section titled “basePath Support”](#basepath-support)
The `basePath` option enables mounting the dashboard at a sub-path behind a reverse proxy or framework router:
```typescript
const dashboard = await createDashboard({
client,
basePath: "/internal/queuert",
});
```
The dashboard injects a `` tag into the HTML response, which tells the SolidJS router to prefix all routes with the base path. API requests from the frontend are also prefixed accordingly.
## See Also
[Section titled “See Also”](#see-also)
* [Dashboard Reference](/queuert/reference/dashboard/) — Configuration and API
* [Adapter Architecture](../adapters/) — State adapter design
# In-Process Worker
> In-process worker lifecycle, concurrency, and lease management.
## Overview
[Section titled “Overview”](#overview)
This document describes the worker design in Queuert: how workers coordinate job processing, manage concurrency, and handle failures.
A **worker** runs a main loop that coordinates job processing across multiple **slots**. Each slot processes one job at a time; the worker manages concurrency and scaling.
## Concurrency Model
[Section titled “Concurrency Model”](#concurrency-model)
Workers process jobs in parallel using slots. See `createInProcessWorker` TSDoc for configuration options. Default: single slot (`concurrency: 1`).
### Architecture
[Section titled “Architecture”](#architecture)

**How it works:**
1. Main loop spawns slots up to `concurrency`
2. Each slot acquires a job and processes it independently
3. When a slot completes, main loop spawns a replacement
4. Slots compete for jobs via database-level locking (`FOR UPDATE SKIP LOCKED` in PostgreSQL)
## Worker Lifecycle
[Section titled “Worker Lifecycle”](#worker-lifecycle)
### Main Loop
[Section titled “Main Loop”](#main-loop)
The worker runs a single coordinating loop:
1. **Fill**: Spawn slots up to `concurrency`
2. **Reap**: Reclaim one expired lease (if any idle slots remain)
3. **Wait**: Listen for notification, poll timeout, or slot completion
4. **Repeat**
### Shutdown
[Section titled “Shutdown”](#shutdown)
On startup, the worker emits a `workerStarted` observability event.
Calling `stop()` triggers graceful shutdown:
1. Signal abort controller
2. Stop spawning new slots
3. Wait for all in-flight jobs to complete (or abandon via lease expiry)
4. Emit `workerStopping` and `workerStopped` observability events
## Worker Identity
[Section titled “Worker Identity”](#worker-identity)
Each worker has a unique identity stored in `leasedBy`. The worker tracks active jobs internally and routes abort signals by job ID—no per-slot identity is needed.
## Reaper
[Section titled “Reaper”](#reaper)
The reaper reclaims jobs with expired leases, making them available for retry.
When idle slots remain in the main loop:
1. Find oldest `running` job where `leasedUntil < now()` and type matches registered types
2. Transition job: `running` → `pending`, clear `leasedBy` and `leasedUntil`
3. Emit `jobReaped` observability event
4. Notify via `jobScheduled` (workers wake up) and `jobOwnershipLost` (original worker aborts)
**Design decisions:**
* **Integrated with main loop**: Runs once per iteration, no separate process needed.
* **One job per iteration**: Reaps at most one job to avoid blocking slot spawning.
* **Type-scoped**: Only reaps job types the worker is registered to handle.
* **Concurrent-safe**: Database locking prevents conflicts between workers.
* **Self-aware**: When running with multiple slots, the reaper excludes jobs currently being processed by the same worker (via `ignoredJobIds`). This prevents a race condition where a worker could reap its own in-progress job if the lease expires before renewal.
## Retry and Backoff
[Section titled “Retry and Backoff”](#retry-and-backoff)
When a job handler throws, the worker reschedules it with exponential backoff:
```plaintext
delay = min(initialDelayMs * multiplier^(attempt-1), maxDelayMs)
```
Example with defaults: 10s → 20s → 40s → 80s → 160s → 300s → 300s…
See [Job Processing](../job-processing/) for details on error handling and abort signals.
## Client-Based Construction
[Section titled “Client-Based Construction”](#client-based-construction)
`createInProcessWorker` accepts a `client` instance and extracts infrastructure (`stateAdapter`, `notifyAdapter`, `observabilityAdapter`, `jobTypes`, `log`) from it internally. Worker-specific options (`processors`, `concurrency`, `pollIntervalMs`, `recoveryBackoffConfig`, `defaults`, `requiredAttemptMiddleware`) remain separate parameters. The top-level `recoveryBackoffConfig` controls the worker’s own main loop retry behavior (e.g., recovery from database connection errors). Per-attempt configuration — `backoffConfig`, `leaseConfig`, `attemptMiddleware` — lives on the processor registry; the worker-level `defaults.backoffConfig` / `defaults.leaseConfig` provide a fallback for processors that don’t set their own (resolution order: processor → registry → worker `defaults` → library default). `requiredAttemptMiddleware` enforces that every slice merged into the worker includes a fixed set of middleware instances as an in-order subsequence — useful for guaranteeing cross-cutting concerns like auth or tracing are present on every slice. The worker only enforces presence; slices continue to run their own middleware chains.
This is purely a construction convenience — no lifecycle coupling is introduced. The client and worker remain independent after construction.
## Extensibility
[Section titled “Extensibility”](#extensibility)
### Multi-Type Workers
[Section titled “Multi-Type Workers”](#multi-type-workers)
A single worker can handle multiple job types. Slots poll all registered types and process whichever is available first. Per-type configuration (lease, retry) overrides worker defaults.
### Attempt Middlewares
[Section titled “Attempt Middlewares”](#attempt-middlewares)
Handler middleware hook into one or more job processing phases via `wrapHandler`, `wrapPrepare`, and `wrapComplete`. Each hook can inject typed context into the inner handler/callback through `next(ctx)`. Middleware compose as an onion: the first middleware’s “before” runs outermost. Middleware enable cross-cutting concerns like contextual logging, audit trails, tracing spans, and resource injection.
Middleware are declared on the processor registry via `createProcessors({ attemptMiddleware: [...] })`. Handler signatures inside that registry auto-infer their typed context from the middleware tuple. When multiple slices are passed as an array to `createInProcessWorker`, each processor keeps its slice’s middleware chain.
To share middleware across multiple registries, list them inline at each `createProcessors` call — the tuple inference narrows without requiring `as const`. Each slice’s middleware chain is the runtime source of truth; the worker simply dispatches to whichever processor matches the job’s typeName.
## Summary
[Section titled “Summary”](#summary)
The worker design emphasizes:
1. **Simplicity**: Single main loop coordinating parallel slots
2. **Efficiency**: Slots are self-contained, main loop just manages concurrency
3. **Reliability**: Integrated reaper ensures recovery from failures
4. **Flexibility**: Per-type configuration, multi-type workers
5. **Extensibility**: Handler middleware enable cross-cutting concerns
## See Also
[Section titled “See Also”](#see-also)
* [Job Processing](../job-processing/) — Prepare/complete pattern, abort signals, timeouts
* [Adapters](../adapters/) — Notification optimization, state provider design
# Job Processing
> Prepare/complete pattern, atomic and staged modes.
## Overview
[Section titled “Overview”](#overview)
This document describes how Queuert processes jobs: transactional design, prepare/complete pattern, and timeout philosophy.
## Transactional Design
[Section titled “Transactional Design”](#transactional-design)
Queuert’s core design principle is that **jobs are created inside the same database transaction as your application state changes**. This follows the transactional outbox pattern:
```typescript
await withTransactionHooks(async (transactionHooks) =>
db.transaction(async (tx) => {
// Application state change
const image = await tx.images.create({ ... });
// Job creation in the same transaction
// The transaction context property name matches your StateProvider
await client.startChain({
tx,
transactionHooks,
typeName: "process-image",
input: { imageId: image.id },
});
}),
);
```
### Why This Matters
[Section titled “Why This Matters”](#why-this-matters)
1. **Atomicity**: If the transaction rolls back, the job is never created. No orphaned jobs.
2. **Consistency**: The job always references valid application state.
3. **No dual-write problem**: You don’t need to coordinate between your database and a separate job queue.
### Extending to Job Processing
[Section titled “Extending to Job Processing”](#extending-to-job-processing)
The same transactional principle extends to job processing through the prepare/complete pattern:
* **Prepare phase**: Read application state within a transaction
* **Processing phase**: Perform side-effects (API calls, file operations) outside the transaction
* **Complete phase**: Write results back within a transaction
This ensures that job outputs and continuations are also created atomically with any state changes they produce.
Observability events (metrics, span ends, logs) emitted during the prepare and complete phases are transactional — they are buffered and only flushed after the transaction commits. If the transaction rolls back, no observability events leak out.
## Prepare/Complete Pattern
[Section titled “Prepare/Complete Pattern”](#preparecomplete-pattern)
Attempt handlers split processing into distinct phases to support both atomic (single-transaction) and staged (long-running) operations. See `AttemptHandler` TSDoc for the full handler signature and `AttemptPrepareOptions` for mode details.
### Auto-Setup (Default)
[Section titled “Auto-Setup (Default)”](#auto-setup-default)
Most jobs don’t need `prepare`. Call `complete` directly and auto-setup infers the mode:
* **Synchronous `complete`** (called immediately, no prior `await`): atomic mode — single transaction wraps everything
* **Async work before `complete`**: staged mode — lease renewal active between async work and complete
* Accessing `prepare` after auto-setup throws: “Prepare cannot be accessed after auto-setup”
See [Processing Modes](../../guides/processing-modes/) for examples and a decision flowchart.
### Explicit Modes
[Section titled “Explicit Modes”](#explicit-modes)
For more control, call `prepare` explicitly:
* **Atomic mode**: Prepare and complete run in the same transaction. Rarely needed since calling `complete` directly achieves the same result with less ceremony.
* **Staged mode**: Prepare runs in one transaction, long-running work happens outside, then complete runs in another transaction. The worker automatically renews the job lease between phases. Implement the processing phase idempotently as it may retry if the worker crashes.
## Error Recovery and Savepoints
[Section titled “Error Recovery and Savepoints”](#error-recovery-and-savepoints)
Both the `prepare` and `complete` callbacks run inside database savepoints. This is the mechanism that keeps jobs safe when user code throws.
### Why Savepoints
[Section titled “Why Savepoints”](#why-savepoints)
A naive approach would run user callbacks directly inside the job’s transaction. The problem: if user code throws after executing partial SQL, the transaction is **poisoned** — most databases reject further statements on a transaction that has seen an error. The engine couldn’t even reschedule the job because the reschedule SQL would fail on the same broken transaction.
Savepoints solve this. A savepoint is a checkpoint within a transaction. If code inside the savepoint throws, the database rolls back to that checkpoint — undoing the partial work — while the outer transaction remains healthy. The engine can then reschedule the job and commit normally.
### How It Works
[Section titled “How It Works”](#how-it-works)

On any unhandled error the job is rescheduled with exponential backoff (default: 10 s → 20 s → 40 s → … capped at 300 s). There is no maximum retry count — jobs retry indefinitely. Use [discriminated unions or compensation patterns](../../guides/error-handling/) to handle permanently failing jobs.
See [Job Processing Reliability](../../guides/processing-reliability/) for per-phase error scenarios with code examples.
## Timeouts
[Section titled “Timeouts”](#timeouts)
Queuert does not provide built-in soft timeout functionality. This is intentional:
1. **Userland solution is trivial**: Combine `AbortSignal.timeout()` with the existing `signal` parameter using `AbortSignal.any()`
2. **Lease mechanism is the hard timeout**: If a job doesn’t complete within `leaseMs`, the reaper reclaims it and another worker retries
### Cooperative Timeouts
[Section titled “Cooperative Timeouts”](#cooperative-timeouts)
Users implement cooperative timeouts by combining `AbortSignal.timeout()` with the existing `signal` parameter using `AbortSignal.any()`.
### Hard Timeouts
[Section titled “Hard Timeouts”](#hard-timeouts)
For hard timeouts (forceful termination), the lease mechanism already handles this:
* Configure `leaseMs` appropriately for the job type
* If the job doesn’t complete or renew its lease in time, the reaper reclaims it
* Another worker can then retry the job
## See Also
[Section titled “See Also”](#see-also)
* [Job Processing Reliability](../../guides/processing-reliability/) — Savepoint protection, automatic rollback
* [Client API](/queuert/reference/queuert/client/) — Mutation methods, query methods, awaitChain
* [In-Process Worker](../in-process-worker/) — Worker lifecycle, leasing, reaper
* [Adapters](../adapters/) — StateAdapter context architecture
# Job Type References
> Job type definition patterns and type hierarchy.
## Overview
[Section titled “Overview”](#overview)
This document describes the model for how job types reference each other. Instead of referencing other job types by name only, the system supports two reference modes that can be combined flexibly. See `JobTypeReference`, `NominalJobTypeReference`, and `StructuralJobTypeReference` TSDoc for type details.
## Reference Modes
[Section titled “Reference Modes”](#reference-modes)
### Nominal Reference (by typeName)
[Section titled “Nominal Reference (by typeName)”](#nominal-reference-by-typename)
Explicitly reference job types by their name. Supports union of names for flexibility:
```typescript
{
typeName: "step2" | "step2_alt";
}
```
### Structural Reference (by input)
[Section titled “Structural Reference (by input)”](#structural-reference-by-input)
Reference job types by their input type signature. This matches **all** job types whose input matches the given structure:
```typescript
{ input: { b: boolean } | { c: string } }
```
When multiple job types match, the user decides which one to use at runtime.
## Application
[Section titled “Application”](#application)
### Continuation (`continueWith`)
[Section titled “Continuation (continueWith)”](#continuation-continuewith)
Defines what job types a job can continue to. References can use either mode or combine them with unions:
```typescript
continueWith: { typeName: 'step2' | 'step2_alt' } | { input: { c: boolean } }
```
Structural references enable loose coupling — a router doesn’t need to know every handler by name:
```ts
const jobTypes = defineJobTypes<{
router: {
entry: true;
input: { path: string };
continueWith: { input: { payload: string } };
};
"handler-a": {
input: { payload: string };
output: { resultA: string };
};
"handler-b": {
input: { payload: string };
output: { resultB: number };
};
}>();
// continueWith accepts either "handler-a" or "handler-b" — both match the input shape
```
### Blockers
[Section titled “Blockers”](#blockers)
Defines job types that must complete before this job can run. Blockers are an ordered array supporting two slot types:
**Fixed slots**: Each position requires exactly one blocker matching the reference.
```typescript
blockers: [{ typeName: "auth" }, { typeName: "validate" }];
```
**Rest/variadic slots**: Zero or more blockers matching the reference.
```typescript
blockers: [
{ typeName: 'auth' },
...{ typeName: 'validator' }[]
]
```
Structural references allow any entry job type with a matching input shape to satisfy a blocker slot:
```ts
const jobTypes = defineJobTypes<{
"fetch-a": {
entry: true;
input: { url: string };
output: { data: string };
};
"fetch-b": {
entry: true;
input: { url: string };
output: { data: string };
};
aggregate: {
entry: true;
input: null;
output: { combined: string[] };
blockers: [...{ input: { url: string } }[]];
};
}>();
// aggregate accepts any number of blockers whose input has { url: string }
// — both "fetch-a" and "fetch-b" qualify
```
### Blocker Output Typing
[Section titled “Blocker Output Typing”](#blocker-output-typing)
When accessing `job.blockers`, outputs are typed based on the reference:
* **Nominal reference**: Output type of the named job type(s)
* **Structural reference**: Union of output types from all matching job types
```ts
const jobTypes = defineJobTypes<{
auth: {
entry: true;
input: { token: string };
output: { userId: string };
};
validate: {
entry: true;
input: { data: unknown };
output: { valid: boolean };
};
process: {
entry: true;
input: { action: string };
output: { done: boolean };
blockers: [{ typeName: "auth" }, { typeName: "validate" }];
};
}>();
const processors = createProcessors({
client,
jobTypes,
processors: {
process: {
attemptHandler: async ({ job, complete }) => {
const [auth, validate] = job.blockers;
// auth.output is { userId: string }
// validate.output is { valid: boolean }
return complete(() => ({ done: auth.output.userId !== "" && validate.output.valid }));
},
},
},
});
```
## Structural Matching Semantics
[Section titled “Structural Matching Semantics”](#structural-matching-semantics)
When using `{ input: Type }`, the system finds all job types whose input matches that type. This enables abstraction — multiple implementations can share an input contract — and runtime flexibility — the caller chooses the specific implementation when calling `continueWith`.
## Validation
[Section titled “Validation”](#validation)
### Compile-Time (`defineJobTypes`)
[Section titled “Compile-Time (defineJobTypes)”](#compile-time-definejobtypes)
Type-level validation only. References are checked at compile time via TypeScript’s type system.
### Runtime (`createJobTypes`)
[Section titled “Runtime (createJobTypes)”](#runtime-createjobtypes)
When using validation libraries (Zod, Valibot, etc.), references are validated at both compile time and runtime. Invalid references throw `JobTypeValidationError`.
## See Also
[Section titled “See Also”](#see-also)
* [Chain Patterns](/queuert/guides/chain-patterns/) — Continuation patterns (linear, branched, loops, go-to)
* [Job Blockers](/queuert/guides/job-blockers/) — Fan-out/fan-in dependencies
* [Chain Model](../chain-model/) — Chain structure, Promise analogy
* [Job Processing](../job-processing/) — Prepare/complete pattern
# Logging
> Structured log entries emitted during job and worker lifecycle events.
## Overview
[Section titled “Overview”](#overview)
Queuert emits structured log entries for every lifecycle event — worker start/stop, job creation, attempts, failures, completions, chain lifecycle, blockers, and adapter errors. Logging is part of `queuert` core and does not require the `@queuert/otel` package.
Pass a `log` function to `createClient` to receive log entries:
```ts
import { createClient, type Log } from "queuert";
const log: Log = (entry) => {
console.log(`[${entry.level}] ${entry.message}`, entry.data);
};
const client = await createClient({
stateAdapter,
notifyAdapter,
log,
jobTypes,
});
```
## Log Entry Structure
[Section titled “Log Entry Structure”](#log-entry-structure)
Every log entry is a typed object with the following shape:
```ts
{
type: string; // Machine-readable event identifier (e.g. "job_created")
level: LogLevel; // "info" | "warn" | "error"
message: string; // Human-readable description
data: { ... }; // Structured data specific to the event
error?: unknown; // Present only on error/warn entries that carry an error
}
```
All entries are strongly typed — the `type` field determines the exact shape of `data`, the `level`, and the `message`. This means consumers can switch on `type` for type-safe handling.
## Log Entries
[Section titled “Log Entries”](#log-entries)
### Worker Lifecycle
[Section titled “Worker Lifecycle”](#worker-lifecycle)
| Type | Level | Message | Data |
| ----------------- | ------- | ----------------------- | -------------------------- |
| `worker_started` | `info` | Started worker | `workerId`, `jobTypeNames` |
| `worker_error` | `error` | Worker error | `workerId`, `error` |
| `worker_stopping` | `info` | Stopping worker… | `workerId` |
| `worker_stopped` | `info` | Worker has been stopped | `workerId` |
### Job Lifecycle
[Section titled “Job Lifecycle”](#job-lifecycle)
| Type | Level | Message | Data |
| --------------- | ------ | -------------------------------- | ---------------------------------------------------------------------------------------------------------- |
| `job_created` | `info` | Job created | `id`, `typeName`, `chainId`, `chainTypeName`, `input`, `blockers`, `scheduledAt?`, `scheduleAfterMs?` |
| `job_completed` | `info` | Job completed | `id`, `typeName`, `chainId`, `chainTypeName`, `status`, `attempt`, `output?`, `continuedWith?`, `workerId` |
| `job_reaped` | `info` | Reaped expired job lease | `id`, `typeName`, `chainId`, `chainTypeName`, `leasedBy`, `leasedUntil`, `workerId` |
| `job_blocked` | `info` | Job blocked by incomplete chains | `id`, `typeName`, `chainId`, `chainTypeName`, `blockedByChains` |
| `job_triggered` | `info` | Job triggered | `id`, `typeName`, `chainId`, `chainTypeName` |
| `job_unblocked` | `info` | Job unblocked | `id`, `typeName`, `chainId`, `chainTypeName`, `unblockedByChain` |
### Attempt Lifecycle
[Section titled “Attempt Lifecycle”](#attempt-lifecycle)
| Type | Level | Message | Data |
| ------------------------------------- | ------- | --------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------- |
| `job_attempt_started` | `info` | Job attempt started | `id`, `typeName`, `chainId`, `chainTypeName`, `status`, `attempt`, `workerId` |
| `job_attempt_completed` | `info` | Job attempt completed | `id`, `typeName`, `chainId`, `chainTypeName`, `status`, `attempt`, `output?`, `continuedWith?`, `workerId` |
| `job_attempt_failed` | `error` | Job attempt failed | `id`, `typeName`, `chainId`, `chainTypeName`, `status`, `attempt`, `rescheduledAfterMs?`, `rescheduledAt?`, `workerId`, `error` |
| `job_attempt_taken_by_another_worker` | `warn` | Job taken by another worker | `id`, `typeName`, `chainId`, `chainTypeName`, `status`, `attempt`, `leasedBy`, `leasedUntil`, `workerId` |
| `job_attempt_already_completed` | `warn` | Job already completed by another worker | `id`, `typeName`, `chainId`, `chainTypeName`, `status`, `attempt`, `completedBy`, `workerId` |
| `job_attempt_lease_expired` | `warn` | Job lease expired | `id`, `typeName`, `chainId`, `chainTypeName`, `status`, `attempt`, `leasedBy`, `leasedUntil`, `workerId` |
| `job_attempt_lease_renewed` | `info` | Job lease renewed | `id`, `typeName`, `chainId`, `chainTypeName`, `status`, `attempt`, `leasedBy`, `leasedUntil`, `workerId` |
### Chain Lifecycle
[Section titled “Chain Lifecycle”](#chain-lifecycle)
| Type | Level | Message | Data |
| ----------------- | ------ | --------------- | -------------------------- |
| `chain_created` | `info` | Chain created | `id`, `typeName`, `input` |
| `chain_completed` | `info` | Chain completed | `id`, `typeName`, `output` |
| `chain_deleted` | `info` | Chain deleted | `id`, `typeName` |
### Adapter Errors
[Section titled “Adapter Errors”](#adapter-errors)
| Type | Level | Message | Data |
| ---------------------- | ------ | -------------------- | -------------------- |
| `notify_adapter_error` | `warn` | Notify adapter error | `operation`, `error` |
| `state_adapter_error` | `warn` | State adapter error | `operation`, `error` |
### Validation Errors
[Section titled “Validation Errors”](#validation-errors)
| Type | Level | Message | Data |
| --------------------------- | ------- | ----------- | -------------------------------------------------------- |
| `job_type_validation_error` | `error` | *(dynamic)* | `code`, `typeName`, `error`, plus error-specific details |
## Data Shapes
[Section titled “Data Shapes”](#data-shapes)
Log entry data fields compose from a few base shapes:
* **JobBasicData** — `id`, `typeName`, `chainId`, `chainTypeName`
* **JobProcessingData** — extends JobBasicData with `status`, `attempt`
* **ChainData** — `id`, `typeName`
## Relationship to ObservabilityAdapter
[Section titled “Relationship to ObservabilityAdapter”](#relationship-to-observabilityadapter)
The `log` function and the `ObservabilityAdapter` are independent. The internal `ObservabilityHelper` calls both on each event, ensuring logs and metrics/traces stay consistent. You can use either or both:
* `log` only — structured logging without OTel dependency
* `ObservabilityAdapter` only — metrics and traces without logging
* Both — full observability
## See Also
[Section titled “See Also”](#see-also)
* [OTEL Metrics](../otel-metrics/) — OpenTelemetry counters, histograms, and gauges
* [OTEL Tracing](../otel-tracing/) — Span hierarchy and distributed tracing
* [Adapters](../adapters/) — Overall adapter design philosophy
# NATS Internals
> Pub/sub subjects, JetStream KV hints, and revision-based CAS in the NATS notify adapter.
## Overview
[Section titled “Overview”](#overview)
This document describes the internal implementation of `@queuert/nats`. Like Redis, NATS is used exclusively as a **notification adapter** — it does not store job state. NATS provides pub/sub notifications with an optional JetStream KV store for thundering herd optimization using revision-based compare-and-swap.
## Pub/Sub Subjects
[Section titled “Pub/Sub Subjects”](#pubsub-subjects)
Three NATS subjects carry notifications (configurable prefix, default `queuert`):
| Subject | Published When | Payload Format | Purpose |
| ----------------- | ------------------- | -------------- | ----------------------------- |
| `{prefix}.sched` | Jobs become pending | `{typeName}` | Wake idle workers |
| `{prefix}.chainc` | Chain completes | `{chainId}` | Wake clients awaiting results |
| `{prefix}.owls` | Lease reaped | `{jobId}` | Notify ownership loss |
NATS core pub/sub is fire-and-forget — messages are delivered to currently connected subscribers only.
## JetStream KV for Hints
[Section titled “JetStream KV for Hints”](#jetstream-kv-for-hints)
When a JetStream KV bucket is provided, the adapter uses it for thundering herd prevention. Without KV, all listeners query the database on every notification.
### KV Bucket Configuration
[Section titled “KV Bucket Configuration”](#kv-bucket-configuration)
The KV bucket is created by the application with a 60-second TTL:
```typescript
const kv = await js.views.kv("queuert_hints", { ttl: 60_000 });
```
### Key Format
[Section titled “Key Format”](#key-format)
```plaintext
{subjectPrefix}_hint_{typeName}
```
Example: `queuert_hint_process-order`
### Hint Lifecycle
[Section titled “Hint Lifecycle”](#hint-lifecycle)
1. **Create / add**: the publisher calls `provideWakeHint(typeName, count)`. If the key doesn’t exist, the adapter creates it with `kv.create`; otherwise it reads the current value and writes back `current + count` via CAS, retrying on revision conflicts.
2. **Decrement**: workers receiving the notification call `consumeWakeHint(typeName)`, which reads the value and revision then attempts an atomic update with the decremented value.
3. **Expire**: keys auto-expire after 60 seconds via the bucket’s TTL.
If `consumeWakeHint` finds no key (the budget never existed or expired), it returns `true` — graceful degradation rather than silently missing wakeups.
### Revision-Based CAS
[Section titled “Revision-Based CAS”](#revision-based-cas)
NATS JetStream KV supports optimistic concurrency via revision numbers. Each `kv.put()` returns a revision, and `kv.update()` accepts an expected revision — the update fails if another writer modified the value since it was read:
```plaintext
Worker A: kv.get("hint_process-order") → { value: "3", revision: 42 }
Worker B: kv.get("hint_process-order") → { value: "3", revision: 42 }
Worker A: kv.update("hint_process-order", "2", 42) → succeeds (revision 43)
Worker B: kv.update("hint_process-order", "2", 42) → fails ("wrong last sequence")
Worker B: kv.get("hint_process-order") → { value: "2", revision: 43 }
Worker B: kv.update("hint_process-order", "1", 43) → succeeds (revision 44)
```
The adapter retries up to 5 times on “wrong last sequence” errors before giving up. A failed CAS means another writer modified the value — the retrying caller reads the new value and tries again. Both `provideWakeHint` (additive contributions from concurrent publishers) and `consumeWakeHint` (workers racing to claim slots) use the same retry loop.
### Decrement Logic
[Section titled “Decrement Logic”](#decrement-logic)
```plaintext
1. Read hint value and revision
2. If key missing: return true (graceful degradation — wake)
3. If value ≤ 0: return false (budget exhausted)
4. Try kv.update(key, value - 1, revision)
5. If success: return true (slot claimed, worker should query database)
6. If "wrong last sequence": retry from step 1 (max 5 times)
7. If max retries exceeded: return false (skip this notification)
```
This provides the same thundering herd prevention as Redis Lua scripts, using NATS-native primitives instead of atomic scripting.
## Without JetStream KV
[Section titled “Without JetStream KV”](#without-jetstream-kv)
When no KV bucket is provided, `provideWakeHint`/`consumeWakeHint` become no-ops:
* `provideWakeHint` does nothing
* `consumeWakeHint` always returns `true`
* `notifyJobScheduled` still publishes
* All listeners wake on every notification; the database (`FOR UPDATE SKIP LOCKED` in PostgreSQL, exclusive locking in SQLite) prevents duplicate processing
This mode is simpler to deploy but generates more database queries under high worker counts.
## Shared Listener Pattern
[Section titled “Shared Listener Pattern”](#shared-listener-pattern)
The NATS adapter uses the same shared listener pattern as Redis — a single NATS subscription per subject with multiplexed callbacks:
* **Lazy start**: Subscription created on first listener registration
* **Shared**: Additional listeners attach without new subscriptions
* **Lazy stop**: Subscription torn down when last listener unsubscribes
* **Serialization**: All mutations serialize on a single async write lock — no intermediate `starting`/`stopping` states
## Connection Model
[Section titled “Connection Model”](#connection-model)
NATS uses a single connection (`NatsConnection`) for both publishing and subscribing — unlike Redis, there is no need for separate connections. The adapter accepts the connection directly:
```typescript
createNatsNotifyAdapter({
nc, // NatsConnection
kv, // Optional: JetStream KV bucket
subjectPrefix, // Optional: default "queuert"
});
```
## See Also
[Section titled “See Also”](#see-also)
* [Adapter Architecture](../adapters/) — Hint-based optimization design
* [NATS Reference](/queuert/reference/nats/) — API documentation
* [Redis Internals](../redis-internals/) — Alternative notify adapter with Lua scripts
# OTEL Internals
> Adapter architecture, W3C context propagation, and transactional buffering.
## Overview
[Section titled “Overview”](#overview)
This document describes the internal implementation of `@queuert/otel` — how the observability adapter bridges Queuert’s core with the OpenTelemetry SDK, how trace context survives process boundaries via database persistence, and how transactional buffering ensures metrics and spans reflect committed state.
## Adapter Architecture
[Section titled “Adapter Architecture”](#adapter-architecture)
The observability system has three layers:
```plaintext
Core operations (createStateJobs, finishJob, job-process)
↓ calls
ObservabilityHelper (maps domain objects to primitive data)
↓ calls
ObservabilityAdapter (emits metrics and spans)
↓ implemented by
@queuert/otel (OpenTelemetry SDK integration)
```
### ObservabilityAdapter Interface
[Section titled “ObservabilityAdapter Interface”](#observabilityadapter-interface)
The core defines an `ObservabilityAdapter` interface with methods for:
* **Metrics**: Counters (`jobCreated`, `jobCompleted`, etc.), histograms (`jobDuration`, `jobAttemptDuration`), and gauges (`jobTypeIdleChange`, `jobTypeProcessingChange`)
* **Tracing**: Span lifecycle methods (`startJobSpan`, `startAttemptSpan`, `startBlockerSpan`, `completeBlockerSpan`, `completeJobSpan`)
All metric methods accept primitive data types (strings, numbers) rather than domain objects, keeping the adapter interface stable even as internal types evolve.
### ObservabilityHelper
[Section titled “ObservabilityHelper”](#observabilityhelper)
The helper layer maps domain objects (`StateJob`, `Job`, `Chain`) to the adapter’s primitive parameters. It also handles logging via the `Log` interface. This separation means the OTEL adapter never needs to import or understand Queuert’s domain types.
### Noop Default
[Section titled “Noop Default”](#noop-default)
When no adapter is provided, a noop implementation is used automatically — all methods are no-ops. This makes observability opt-in with zero overhead when disabled.
## W3C Trace Context Propagation
[Section titled “W3C Trace Context Propagation”](#w3c-trace-context-propagation)
Queuert persists trace context in the database so spans can be linked across process boundaries and time gaps (e.g., a job created by one process and processed minutes later by another).
### Storage Model
[Section titled “Storage Model”](#storage-model)
Each job stores two trace contexts as W3C traceparent strings:
| Field | Stored On | Purpose |
| ------------------- | ------------------- | -------------------------------------------------------------------------- |
| `chainTraceContext` | `job` table | Chain-level span context — used for chain completion and blocker linking |
| `traceContext` | `job` table | Job-level span context — used for attempt spans and continuation linking |
| `trace_context` | `job_blocker` table | Blocker PRODUCER span context — used to create CONSUMER span on resolution |
### W3C Traceparent Format
[Section titled “W3C Traceparent Format”](#w3c-traceparent-format)
All contexts are serialized as W3C traceparent strings:
```plaintext
00-{traceId(32hex)}-{spanId(16hex)}-{flags(2hex)}
```
Example: `00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01`
The OTEL adapter serializes `SpanContext` objects to this format for storage and deserializes them back when creating child spans.
### Context Flow
[Section titled “Context Flow”](#context-flow)
1. **Chain creation** (`startChain`): Creates PRODUCER chain span → serializes to `chainTraceContext`. Creates PRODUCER job span as child → serializes to `traceContext`. Both stored with the job in the database.
2. **Blockers**: For each blocker dependency, creates a PRODUCER `await chain` span as child of the job span → serializes to `trace_context` in the `job_blocker` table.
3. **Continuation** (`continueWith`): Reads origin job’s `traceContext`, creates new PRODUCER job span as child. Inherits `chainTraceContext` from origin (chain context stays the same). New job gets its own `traceContext`.
4. **Worker processing**: Reads job’s `traceContext` from database, creates CONSUMER attempt span as child. All processing spans (prepare, complete) are children of the attempt span.
5. **Blocker resolution** (`unblockJobs`): Reads PRODUCER span context from `job_blocker` table, creates CONSUMER `resolve chain` span as child of the PRODUCER — linking across processes and time.
6. **Chain completion**: Reads `chainTraceContext`, creates CONSUMER `complete chain` span as child of the PRODUCER chain span.
### Why Two Contexts
[Section titled “Why Two Contexts”](#why-two-contexts)
Separate chain and job contexts serve different roles:
* `chainTraceContext` links the chain’s creation to its completion, surviving across all continuations. Every job in the chain shares the same `chainTraceContext`.
* `traceContext` links a specific job to its attempt spans and to its continuation. Each job has its own `traceContext`.
## Transactional Buffering
[Section titled “Transactional Buffering”](#transactional-buffering)
Observability events emitted inside database transactions are buffered and flushed only after the transaction commits. If the transaction rolls back, buffered events are discarded.
### Why Buffer
[Section titled “Why Buffer”](#why-buffer)
Without buffering, a rolled-back transaction could emit metrics and spans for state changes that never persisted — misleading dashboards and traces. Buffering ensures observability reflects committed state.
### Buffered Events
[Section titled “Buffered Events”](#buffered-events)
Events representing write claims inside transactions:
* **Creation**: `chainCreated`, `jobCreated`, `jobBlocked`, PRODUCER span ends
* **Completion**: `jobCompleted`, `jobDuration`, `completeJobSpan`, `chainCompleted`, `chainDuration`, `completeBlockerSpan`, `jobUnblocked`
* **Worker complete**: `jobAttemptCompleted`, continuation PRODUCER span ends
* **Error handling**: `jobAttemptFailed`
### Not Buffered
[Section titled “Not Buffered”](#not-buffered)
Events that need immediate context or occur outside transactions:
* **Span starts**: Must happen before the database write that stores the trace context
* **Events outside transactions**: `jobAttemptStarted`, `jobAttemptDuration`, `jobAttemptLeaseRenewed`, attempt span ends
* **Read-only observations**: Events that observe state without claiming writes
### Self-Cleaning via Savepoints
[Section titled “Self-Cleaning via Savepoints”](#self-cleaning-via-savepoints)
Both `createStateJobs` and `finishJob` use savepoints to automatically roll back buffered observability events on failure. The `TransactionHooks` system captures a checkpoint of the buffer position before each operation. If the operation throws, the savepoint restores the buffer to its checkpoint — partial events from a failed operation are discarded without affecting events from earlier successful operations in the same transaction.
### TransactionHooks
[Section titled “TransactionHooks”](#transactionhooks)
The buffering mechanism is shared with notification events (`notifyJobScheduled`, `notifyChainCompleted`). Both observability and notification events register callbacks on `TransactionHooks`, which flushes all hooks after commit so callbacks run only for committed state changes. Each hook owns its own ordering: observability events register every callback under a single shared hook key and the hook flushes them sequentially, so the order of observability events matches the order of operations. Notification events use separate hook keys and flush in parallel — order across distinct hooks is not guaranteed.
## See Also
[Section titled “See Also”](#see-also)
* [OTEL Metrics](../otel-metrics/) — Counters, histograms, and gauges
* [OTEL Tracing](../otel-tracing/) — Span hierarchy and attributes
* [Adapter Architecture](../adapters/) — Transactional buffering design
* [Chain Model](../chain-model/) — Chain identity and continuation model
* [Job Processing](../job-processing/) — Prepare/complete pattern
* [In-Process Worker](../in-process-worker/) — Worker lifecycle and attempt handling
# OTEL Metrics
> OpenTelemetry counters, histograms, and gauges.
## Overview
[Section titled “Overview”](#overview)
Queuert emits OpenTelemetry metrics through the `@queuert/otel` adapter. Users must configure their OTEL SDK with desired exporters (Prometheus, OTLP, etc.) before using the adapter. See the `ObservabilityAdapter` TSDoc for the adapter interface.
All metrics follow the naming pattern:
```plaintext
queuert.{component}.{operation}[.{suboperation}]
```
The `ObservabilityAdapter` interface accepts milliseconds; the `@queuert/otel` adapter converts duration values to seconds per [OTEL Messaging Semantic Conventions](https://opentelemetry.io/docs/specs/semconv/messaging/messaging-metrics/).
## Counters
[Section titled “Counters”](#counters)
Attribute names follow OpenTelemetry semantic conventions (lowercase, dotted) and match the span attributes documented in [OTEL Tracing](../otel-tracing/):
* `queuert.worker.id` — worker identifier
* `queuert.job.type` — job type name
* `queuert.chain.type` — chain (entry job) type name
* `queuert.job.continued` — boolean: `true` if the completion produced a continuation, `false` otherwise
* `queuert.adapter.operation` — adapter operation that produced an error
### Worker Lifecycle
[Section titled “Worker Lifecycle”](#worker-lifecycle)
| Metric | Attributes | Description |
| ------------------------- | ------------------- | --------------------------- |
| `queuert.worker.started` | `queuert.worker.id` | Worker started processing |
| `queuert.worker.error` | `queuert.worker.id` | Worker encountered an error |
| `queuert.worker.stopping` | `queuert.worker.id` | Worker received stop signal |
| `queuert.worker.stopped` | `queuert.worker.id` | Worker fully stopped |
### Job Lifecycle
[Section titled “Job Lifecycle”](#job-lifecycle)
| Metric | Attributes | Description |
| ----------------------- | -------------------------------------------------------------------------------------- | ------------------------------------------------------------------------ |
| `queuert.job.created` | `queuert.job.type`, `queuert.chain.type` | Job created |
| `queuert.job.completed` | `queuert.job.type`, `queuert.chain.type`, `queuert.worker.id`, `queuert.job.continued` | Job completed. `queuert.worker.id` is omitted for workerless completion. |
| `queuert.job.reaped` | `queuert.job.type`, `queuert.chain.type`, `queuert.worker.id` | Stale job reclaimed by reaper |
| `queuert.job.blocked` | `queuert.job.type`, `queuert.chain.type` | Job blocked by pending blocker chains |
| `queuert.job.triggered` | `queuert.job.type`, `queuert.chain.type` | Pending job triggered to run immediately |
| `queuert.job.unblocked` | `queuert.job.type`, `queuert.chain.type` | Job unblocked after blocker chain completed |
### Attempt Lifecycle
[Section titled “Attempt Lifecycle”](#attempt-lifecycle)
| Metric | Attributes | Description |
| --------------------------------------------- | ------------------------------------------------------------- | ----------------------------------------------------- |
| `queuert.job.attempt.started` | `queuert.job.type`, `queuert.chain.type`, `queuert.worker.id` | Worker began processing an attempt |
| `queuert.job.attempt.completed` | `queuert.job.type`, `queuert.chain.type`, `queuert.worker.id` | Attempt completed successfully |
| `queuert.job.attempt.failed` | `queuert.job.type`, `queuert.chain.type`, `queuert.worker.id` | Attempt failed (may retry) |
| `queuert.job.attempt.taken_by_another_worker` | `queuert.job.type`, `queuert.chain.type`, `queuert.worker.id` | Job already leased by another worker |
| `queuert.job.attempt.already_completed` | `queuert.job.type`, `queuert.chain.type`, `queuert.worker.id` | Job already completed when worker tried to process it |
| `queuert.job.attempt.lease_expired` | `queuert.job.type`, `queuert.chain.type`, `queuert.worker.id` | Lease expired before attempt finished |
| `queuert.job.attempt.lease_renewed` | `queuert.job.type`, `queuert.chain.type`, `queuert.worker.id` | Lease successfully renewed during processing |
### Chain Lifecycle
[Section titled “Chain Lifecycle”](#chain-lifecycle)
| Metric | Attributes | Description |
| ------------------------- | -------------------- | --------------- |
| `queuert.chain.created` | `queuert.chain.type` | Chain created |
| `queuert.chain.completed` | `queuert.chain.type` | Chain completed |
| `queuert.chain.deleted` | `queuert.chain.type` | Chain deleted |
### Adapter Errors
[Section titled “Adapter Errors”](#adapter-errors)
| Metric | Attributes | Description |
| ------------------------------ | --------------------------- | ------------------------------- |
| `queuert.state_adapter.error` | `queuert.adapter.operation` | State adapter operation failed |
| `queuert.notify_adapter.error` | `queuert.adapter.operation` | Notify adapter operation failed |
## Histograms
[Section titled “Histograms”](#histograms)
Histograms track duration distributions at three levels. Unit is seconds.
| Metric | Attributes | Description |
| ------------------------------ | ------------------------------------------------------------- | ------------------------------------------ |
| `queuert.chain.duration` | `queuert.chain.type` | Duration from chain creation to completion |
| `queuert.job.duration` | `queuert.job.type`, `queuert.chain.type` | Duration from job creation to completion |
| `queuert.job.attempt.duration` | `queuert.job.type`, `queuert.chain.type`, `queuert.worker.id` | Duration of a single attempt |
These form a hierarchy — chain duration encompasses job durations (plus wait time between continuations), and job duration encompasses attempt durations (plus wait time between retries):
```plaintext
queuert.chain.duration
├── queuert.job.duration (first job)
│ ├── queuert.job.attempt.duration (attempt 1)
│ └── queuert.job.attempt.duration (attempt 2, retry)
├── queuert.job.duration (continuation)
│ └── queuert.job.attempt.duration
└── (wait time between jobs)
```
## UpDownCounters (Gauges)
[Section titled “UpDownCounters (Gauges)”](#updowncounters-gauges)
Two gauges track real-time worker state. They are incremented/decremented via delta values.
| Metric | Attributes | Description |
| ----------------------------- | --------------------------------------- | ------------------------------------------- |
| `queuert.job_type.idle` | `queuert.job.type`, `queuert.worker.id` | Workers currently idle for this job type |
| `queuert.job_type.processing` | `queuert.job.type`, `queuert.worker.id` | Jobs of this type currently being processed |
## See Also
[Section titled “See Also”](#see-also)
* [OTEL Tracing](../otel-tracing/) — Span hierarchy and attributes
* [OTEL Internals](../otel-internals/) — Adapter architecture, W3C context propagation, and transactional buffering
* [Adapters](../adapters/) — Overall adapter design philosophy
* [In-Process Worker](../in-process-worker/) — Worker lifecycle and processing
# OTEL Tracing
> OpenTelemetry span hierarchy and messaging conventions.
## Overview
[Section titled “Overview”](#overview)
This document describes Queuert’s OpenTelemetry tracing implementation. Tracing provides end-to-end visibility into chain execution, including job dependencies, retry attempts, and blocker relationships.
## Span Hierarchy
[Section titled “Span Hierarchy”](#span-hierarchy)
Queuert uses a five-level span hierarchy:
```plaintext
PRODUCER: create chain.{type} ← Chain published (ends immediately)
│
├── PRODUCER: create job.{type} ← Job published (ends immediately)
│ │
│ ├── PRODUCER: await chain.{type} ← Blocker dependency
│ │ links: [blocker chain]
│ │ └── CONSUMER: resolve chain.{type} ← Blocker resolved
│ │
│ ├── CONSUMER: start job-attempt.{type} ← Worker processes attempt (has duration)
│ │ ├── INTERNAL: prepare
│ │ └── INTERNAL: complete
│ │
│ └── CONSUMER: start job-attempt.{type} ← Retry attempt
│ ├── INTERNAL: prepare
│ └── INTERNAL: complete
│
├── PRODUCER: create job.{type} ← Continuation job
│ │
│ └── CONSUMER: start job-attempt.{type} (final)
│ ├── INTERNAL: prepare
│ ├── INTERNAL: complete
│ └── CONSUMER: complete chain.{type} ← Chain completion
```
Span kinds use OpenTelemetry’s PRODUCER/CONSUMER/INTERNAL semantics. The chain has both a PRODUCER (creation) and CONSUMER (completion) span for symmetry.
| Span | Kind | Created | Ended | Duration |
| ---------------------------- | -------- | -------------------------------- | ----------------------- | ---------------- |
| **create chain.{type}** | PRODUCER | `startChain()` | Immediately | \~0ms |
| **create job.{type}** | PRODUCER | `startChain()`, `continueWith()` | Immediately | \~0ms |
| **await chain.{type}** | PRODUCER | `startChain()` with blockers | Immediately | \~0ms |
| **resolve chain.{type}** | CONSUMER | Blocker chain completes | Immediately | \~0ms |
| **start job-attempt.{type}** | CONSUMER | Worker claims job | Attempt completes/fails | Processing time |
| **prepare** | INTERNAL | `prepare()` called | `prepare()` returns | Transaction time |
| **complete** | INTERNAL | `complete()` called | `complete()` returns | Transaction time |
| **complete job.{type}** | CONSUMER | Workerless completion | Immediately | \~0ms |
| **complete chain.{type}** | CONSUMER | Final job completes | Immediately | \~0ms |
## Blocker Relationships
[Section titled “Blocker Relationships”](#blocker-relationships)
When a job has blockers (dependencies on other chains), each blocker gets a PRODUCER/CONSUMER span pair as a child of the blocked job’s PRODUCER span. The PRODUCER (`await chain.{type}`) is created at `startChain` time with a link to the blocker chain. The CONSUMER (`resolve chain.{type}`) is created when the blocker chain completes, so the time between them represents the blocking duration.
The blocker PRODUCER span’s trace context is persisted in the `job_blocker` table so the CONSUMER can be created later by a different process (the one completing the blocker chain).
```plaintext
EXTERNAL span (e.g., HTTP request)
│
├── PRODUCER: create chain.process-order ──────────────
│ │
│ └── PRODUCER: create job.process-order
│ │
│ ├── PRODUCER: await chain.fetch-user ──link──→ chain fetch-user
│ │ └── CONSUMER: resolve chain.fetch-user
│ │
│ ├── PRODUCER: await chain.fetch-inventory ──link──→ chain fetch-inventory
│ │ └── CONSUMER: resolve chain.fetch-inventory
│ │
│ └── CONSUMER: start job-attempt.process-order
│ │ job.blockers contains resolved blocker outputs
│ ├── INTERNAL: prepare
│ ├── INTERNAL: complete ✓
│ └── CONSUMER: complete chain.process-order
│
├── PRODUCER: create chain.fetch-user ─────────────────
│ │
│ └── PRODUCER: create job.fetch-user
│ │
│ └── CONSUMER: start job-attempt.fetch-user ✓
│ ├── INTERNAL: prepare
│ ├── INTERNAL: complete
│ └── CONSUMER: complete chain.fetch-user
│
└── PRODUCER: create chain.fetch-inventory ────────────
│
└── PRODUCER: create job.fetch-inventory
│
└── CONSUMER: start job-attempt.fetch-inventory ✓
├── INTERNAL: prepare
├── INTERNAL: complete
└── CONSUMER: complete chain.fetch-inventory
```
### Blocker Span Lifecycle
[Section titled “Blocker Span Lifecycle”](#blocker-span-lifecycle)
1. **PRODUCER created and ended** in `startChain` when the job has blockers — one PRODUCER span per blocker, as a child of the job’s PRODUCER span, with a link to the blocker chain’s trace context
2. **Persisted** — the PRODUCER span context is stored in the `job_blocker` table (`trace_context` column) so the CONSUMER can be created by another process
3. **CONSUMER created** when `unblockJobs` detects the blocker chain has completed — the PRODUCER span context is read from `job_blocker` and a CONSUMER span is created as its child
## Continuation Relationships
[Section titled “Continuation Relationships”](#continuation-relationships)
When a job continues to another job via `continueWith`, the continuation links to its origin:
```plaintext
PRODUCER: create chain.multi-step ────────────────────────
│
├── PRODUCER: create job.step-one
│ └── CONSUMER: start job-attempt.step-one #1
│ ├── INTERNAL: prepare
│ └── INTERNAL: complete (calls continueWith)
│
└── PRODUCER: create job.step-two
│ links: [job step-one] ← origin link
│
└── CONSUMER: start job-attempt.step-two #1 (final)
├── INTERNAL: prepare
├── INTERNAL: complete
└── CONSUMER: complete chain.multi-step
```
The origin link shows the causal flow: “step-two was created by step-one’s completion”.
## Workerless Completion
[Section titled “Workerless Completion”](#workerless-completion)
When a job is completed via `completeChain` (without a worker), there is no job-attempt. Instead, a CONSUMER job span marks the completion, and if the chain is fully completed, a CONSUMER chain span closes the trace:
```plaintext
PRODUCER: create chain.approve-order ─────────────────────
│
└── PRODUCER: create job.approve-order
│
└── CONSUMER: complete job.approve-order ← Workerless completion
│
└── CONSUMER: complete chain.approve-order
```
The CONSUMER job span is a child of the PRODUCER job span and carries the same chain/job attributes. When `continueWith` is called during workerless completion, the CONSUMER chain span is omitted (the chain continues):
```plaintext
PRODUCER: create chain.multi-step ────────────────────────
│
├── PRODUCER: create job.step-one
│ │
│ └── CONSUMER: complete job.step-one ← Workerless completion (continueWith)
│
└── PRODUCER: create job.step-two
│ links: [job step-one]
│
└── ...
```
This uses the `completeJobSpan` adapter method rather than `startAttemptSpan`, reflecting that no attempt processing occurred.
## Chain Duration Measurement
[Section titled “Chain Duration Measurement”](#chain-duration-measurement)
With `create chain` at start and `complete chain` at end, total chain duration is calculated as:
```plaintext
Chain Duration = complete chain.startTime - create chain.startTime
```
This provides end-to-end visibility even though individual PRODUCER/CONSUMER spans are instantaneous markers.
## Deduplication
[Section titled “Deduplication”](#deduplication)
When `startChain` is called with deduplication options and a matching chain already exists, no new chain is created. The span must reflect this outcome correctly.
Deduplication is **not an error**—it’s expected behavior that successfully returned an existing chain. Per [OpenTelemetry status conventions](https://opentelemetry.io/docs/specs/otel/trace/api/#set-status), the span status should remain `UNSET` (not `ERROR`), with an attribute indicating deduplication occurred.
When deduplication occurs:
1. Adds attribute `queuert.chain.deduplicated: true`
2. References the existing chain’s IDs
3. Optionally links to the existing chain’s trace context
```plaintext
Caller requests startChain with deduplication key "user-123":
First call (creates new chain):
PRODUCER create chain.process-user [0ms] ──────────────
│ queuert.chain.id: "abc-123"
│ queuert.chain.deduplicated: false
│
└── ... (normal processing)
Second call (deduplicated):
PRODUCER create chain.process-user [0ms] ──────────────
queuert.chain.id: "abc-123" ← same as existing
queuert.chain.deduplicated: true
links: [chain abc-123] ← link to existing chain
```
## Span Attributes
[Section titled “Span Attributes”](#span-attributes)
### Chain Attributes
[Section titled “Chain Attributes”](#chain-attributes)
| Attribute | Type | Description |
| ---------------------------- | ------- | ---------------------------------- |
| `queuert.chain.id` | string | Chain ID |
| `queuert.chain.type` | string | Chain type name |
| `queuert.chain.deduplicated` | boolean | `true` when chain was deduplicated |
### Job Attributes
[Section titled “Job Attributes”](#job-attributes)
| Attribute | Type | Description |
| --------------------- | ------ | --------------------------------- |
| `queuert.job.id` | string | Job ID |
| `queuert.job.type` | string | Job type name |
| `queuert.job.attempt` | number | Attempt number (on attempt spans) |
### Worker Attributes
[Section titled “Worker Attributes”](#worker-attributes)
| Attribute | Type | Description |
| ------------------- | ------ | -------------------------------- |
| `queuert.worker.id` | string | Worker ID processing the attempt |
### Attempt Result Attributes
[Section titled “Attempt Result Attributes”](#attempt-result-attributes)
| Attribute | Type | Description |
| ------------------------------ | ------ | --------------------------------------------- |
| `queuert.attempt.result` | string | `"completed"` or `"failed"` |
| `queuert.rescheduled_at` | string | ISO 8601 timestamp of next retry (on failure) |
| `queuert.rescheduled_after_ms` | number | Delay in ms before next retry (on failure) |
### Continuation Attributes
[Section titled “Continuation Attributes”](#continuation-attributes)
| Attribute | Type | Description |
| --------------------------------- | ------ | --------------------------------- |
| `queuert.continued_with.job_id` | string | ID of the continuation job |
| `queuert.continued_with.job_type` | string | Type name of the continuation job |
### Blocker Attributes
[Section titled “Blocker Attributes”](#blocker-attributes)
| Attribute | Type | Description |
| ---------------------------- | ------ | ------------------------------------------ |
| `queuert.blocker.chain.id` | string | Blocker chain ID |
| `queuert.blocker.chain.type` | string | Blocker chain type name |
| `queuert.blocker.index` | number | Index of the blocker in the blockers array |
## See Also
[Section titled “See Also”](#see-also)
* [OTEL Metrics](../otel-metrics/) — Counters, histograms, and gauges
* [OTEL Internals](../otel-internals/) — Adapter architecture, W3C context propagation, and transactional buffering
* [Chain Model](../chain-model/) — Chain identity and continuation model
* [Job Processing](../job-processing/) — Prepare/complete pattern
* [Adapters](../adapters/) — Overall adapter design philosophy
* [In-Process Worker](../in-process-worker/) — Worker lifecycle and attempt handling
# PostgreSQL Internals
> Schema, indexes, locking, and notification design in the PostgreSQL adapter.
## Overview
[Section titled “Overview”](#overview)
This document describes the internal implementation of `@queuert/postgres` — the tables it creates, how it uses PostgreSQL-specific features for correctness and performance, and how notifications propagate between workers.
## Schema
[Section titled “Schema”](#schema)
The adapter creates its schema via `migrateToLatest()`. All objects live under a configurable PostgreSQL schema (default: `public`) with a table name prefix (default: `queuert_`) for namespace isolation.
### Custom Enum
[Section titled “Custom Enum”](#custom-enum)
```sql
CREATE TYPE job_status AS ENUM ('blocked', 'pending', 'running', 'completed');
```
PostgreSQL enums provide type safety at the database level — invalid status values are rejected by the engine rather than relying on application-level checks.
### Job Table
[Section titled “Job Table”](#job-table)
The `job` table stores all job state:
| Column | Type | Description |
| --------------------- | ------------------------------ | ---------------------------------------------------------------------------------- |
| `id` | configurable (default: `uuid`) | Primary key. Type is set via `idType`; values are generated in JS via `generateId` |
| `type_name` | `text` | Job type identifier |
| `chain_id` | same as `id` | Foreign key to root job — every job in a chain points to the root |
| `chain_type_name` | `text` | Type name of the chain (copied from root for query efficiency) |
| `chain_index` | `integer` | Position in chain (0 for root, incrementing for continuations) |
| `input` | `jsonb` | Job input data |
| `output` | `jsonb` | Completion output (null until completed) |
| `status` | `job_status` | Current state: blocked, pending, running, or completed |
| `created_at` | `timestamptz` | When the job was created |
| `scheduled_at` | `timestamptz` | Earliest time the job can be acquired |
| `completed_at` | `timestamptz` | When the job completed (null until completed) |
| `completed_by` | `text` | Worker ID that completed the job (null for workerless) |
| `attempt` | `integer` | Number of processing attempts (starts at 0) |
| `last_attempt_at` | `timestamptz` | When the last attempt started |
| `last_attempt_error` | `jsonb` | Error from last failed attempt |
| `leased_by` | `text` | Worker ID holding the lease |
| `leased_until` | `timestamptz` | Lease expiry time |
| `deduplication_key` | `text` | Key for chain deduplication |
| `chain_trace_context` | `text` | W3C traceparent for chain-level spans |
| `trace_context` | `text` | W3C traceparent for job-level spans |
The `chain_id` foreign key references `job(id)`, forming a self-referential relationship where all jobs in a chain point to the root job (chain\_index = 0).
### Job Blocker Table
[Section titled “Job Blocker Table”](#job-blocker-table)
The `job_blocker` table tracks dependencies between jobs and chains:
| Column | Type | Description |
| --------------------- | ------------------------ | -------------------------------------------- |
| `job_id` | foreign key to `job(id)` | The blocked job |
| `blocked_by_chain_id` | foreign key to `job(id)` | Root job ID of the blocker chain |
| `index` | `integer` | Position in the blockers array |
| `trace_context` | `text` | PRODUCER span context for blocker resolution |
Primary key: `(job_id, blocked_by_chain_id)` — each job–blocker pair is unique.
### Migration Table
[Section titled “Migration Table”](#migration-table)
The `migration` table tracks applied schema migrations:
| Column | Type | Description |
| ------------ | ------------- | ------------------------------------------------------------ |
| `name` | `text` | Migration identifier (e.g., `20240101000000_initial_schema`) |
| `applied_at` | `timestamptz` | When the migration was applied |
## Indexes
[Section titled “Indexes”](#indexes)
All indexes use partial conditions (WHERE clauses) to minimize size and target specific query patterns.
### Job Acquisition
[Section titled “Job Acquisition”](#job-acquisition)
```sql
CREATE INDEX job_acquisition_idx
ON job (type_name, scheduled_at)
WHERE status = 'pending'
```
Speeds up `acquireJob` — only pending jobs participate in the index.
### Chain Uniqueness
[Section titled “Chain Uniqueness”](#chain-uniqueness)
```sql
CREATE UNIQUE INDEX chain_index_idx
ON job (chain_id, chain_index)
```
Guarantees each position in a chain has exactly one job.
### Deduplication
[Section titled “Deduplication”](#deduplication)
```sql
CREATE INDEX job_deduplication_idx
ON job (deduplication_key, created_at DESC)
WHERE deduplication_key IS NOT NULL AND chain_index = 0
```
Fast lookup for existing chains with the same deduplication key. Only root jobs (chain\_index = 0) are indexed.
### Lease Expiry
[Section titled “Lease Expiry”](#lease-expiry)
```sql
CREATE INDEX job_expired_lease_idx
ON job (type_name, leased_until)
WHERE status = 'running' AND leased_until IS NOT NULL
```
The reaper uses this to find timed-out jobs efficiently.
### Blocker Lookups
[Section titled “Blocker Lookups”](#blocker-lookups)
```sql
CREATE INDEX job_blocker_chain_idx
ON job_blocker (blocked_by_chain_id)
```
Fast reverse lookup — given a completed chain, find all jobs it was blocking.
### Listing Indexes
[Section titled “Listing Indexes”](#listing-indexes)
Five indexes support the listing and filtering queries used by the dashboard and `listJobs`/`listChains` APIs:
```sql
CREATE INDEX chain_listing_idx ON job (created_at DESC) WHERE chain_index = 0
CREATE INDEX job_listing_idx ON job (created_at DESC)
CREATE INDEX job_listing_status_idx ON job (status, created_at DESC)
CREATE INDEX job_listing_type_name_idx ON job (type_name, created_at DESC)
CREATE INDEX chain_listing_type_name_idx ON job (type_name, created_at DESC) WHERE chain_index = 0
```
## Locking
[Section titled “Locking”](#locking)
The adapter uses row-level locking exclusively — no advisory locks.
### FOR UPDATE SKIP LOCKED — Job Acquisition
[Section titled “FOR UPDATE SKIP LOCKED — Job Acquisition”](#for-update-skip-locked--job-acquisition)
The core acquisition query atomically selects and claims a job:
```sql
WITH acquired_job AS (
SELECT id FROM job
WHERE type_name IN (...)
AND status = 'pending'
AND scheduled_at <= now()
ORDER BY scheduled_at ASC
LIMIT 1
FOR UPDATE SKIP LOCKED
)
UPDATE job SET status = 'running', attempt = attempt + 1
WHERE id = (SELECT id FROM acquired_job)
RETURNING *, EXISTS(...) AS has_more
```
`FOR UPDATE SKIP LOCKED` is the key mechanism:
* **FOR UPDATE** locks the selected row, preventing other transactions from modifying it
* **SKIP LOCKED** skips rows already locked by other transactions instead of waiting
This means multiple workers can acquire jobs concurrently without blocking each other — each worker atomically claims the next available job. The `has_more` flag in RETURNING tells the worker whether to immediately attempt another acquisition or wait for a notification.
The same pattern is used for lease reaping (`reapExpiredJobLease`), where expired leases are reclaimed without blocking active transactions.
### FOR UPDATE — Mutations
[Section titled “FOR UPDATE — Mutations”](#for-update--mutations)
Operations that modify a specific job (e.g., completing a job, renewing a lease) use `FOR UPDATE` without `SKIP LOCKED`:
```sql
SELECT * FROM job WHERE id = $1 FOR UPDATE
```
This blocks until the row is available, ensuring the operation sees the latest state. Used by `getJob` and `getChain` when called with `lock: "exclusive"` from inside a transaction.
### Deadlock Prevention in Deletion
[Section titled “Deadlock Prevention in Deletion”](#deadlock-prevention-in-deletion)
When deleting connected chains, the adapter locks rows in physical (`ctid`) order:
```sql
SELECT id FROM job WHERE chain_id = ANY($1) ORDER BY ctid FOR UPDATE
```
Ordering by `ctid` ensures all concurrent deletions acquire locks in the same physical order, preventing deadlock cycles that would occur with arbitrary ordering.
### Transaction Management
[Section titled “Transaction Management”](#transaction-management)
The adapter uses explicit `BEGIN`/`COMMIT`/`ROLLBACK` with savepoints for nested operations:
```sql
SAVEPOINT queuert_sp
-- user callback executes here
RELEASE SAVEPOINT queuert_sp
-- or on error: ROLLBACK TO SAVEPOINT queuert_sp
```
Savepoints enable partial rollback within a transaction — if a user callback fails, the savepoint rolls back its effects without aborting the entire transaction.
## Notifications (LISTEN/NOTIFY)
[Section titled “Notifications (LISTEN/NOTIFY)”](#notifications-listennotify)
PostgreSQL’s built-in `LISTEN`/`NOTIFY` mechanism provides low-latency event delivery between processes without polling.
### Channels
[Section titled “Channels”](#channels)
The adapter uses three notification channels (configurable prefix, default `queuert`):
| Channel | Published When | Payload | Purpose |
| ----------------- | ------------------------------- | ------------- | ----------------------------------- |
| `{prefix}_sched` | Jobs become pending | Job type name | Wake idle workers |
| `{prefix}_chainc` | Chain completes | Chain ID | Wake clients awaiting chain results |
| `{prefix}_owls` | Lease expires and job is reaped | Job ID | Notify workers of ownership loss |
### Publishing
[Section titled “Publishing”](#publishing)
Notifications are published via `pg_notify()`:
```sql
SELECT pg_notify($1, $2)
```
When called inside `withTransaction`, the notification is delivered after the transaction commits — PostgreSQL guarantees this atomicity.
### Subscribing
[Section titled “Subscribing”](#subscribing)
Each channel subscription maintains a dedicated connection that issues `LISTEN` and stays open, receiving events via the PostgreSQL protocol’s asynchronous notification mechanism. The adapter uses a shared listener pattern that multiplexes multiple callbacks on a single subscription, lazily starting when the first subscriber registers and stopping when the last unsubscribes.
### No Hint Optimization
[Section titled “No Hint Optimization”](#no-hint-optimization)
Unlike Redis and NATS, the PostgreSQL notify adapter does not implement hint-based thundering herd optimization. All listening workers query the database on each notification. This is acceptable because `FOR UPDATE SKIP LOCKED` ensures only one worker acquires each job — redundant queries are cheap, not harmful.
## CTE Patterns
[Section titled “CTE Patterns”](#cte-patterns)
The adapter uses CTEs (Common Table Expressions) extensively to perform multi-step operations in a single round-trip:
* **Job creation**: Deduplication check + batch INSERT in one query
* **Blocker management**: INSERT blockers + UPDATE job status from pending to blocked
* **Unblocking**: UPDATE jobs from blocked to pending when all their blockers have completed (blocker rows are retained to propagate trace context into the unblocked job)
* **Chain deletion**: Recursive CTE to find connected chains + cascading DELETE
* **Connected chain discovery**: Recursive CTE traversing blocker relationships in both directions
All writeable CTEs use `RETURNING` to propagate results between steps without additional round-trips.
## Vacuum Tuning
[Section titled “Vacuum Tuning”](#vacuum-tuning)
The adapter configures aggressive autovacuum and storage settings on the job tables via the `vacuum_tuning` migration:
### Fillfactor
[Section titled “Fillfactor”](#fillfactor)
```sql
ALTER TABLE job SET (fillfactor = 75);
```
Fillfactor reserves 25% free space per heap page. Jobs go through multiple in-place status updates (pending → running → completed, plus lease renewals), and PostgreSQL can perform these as HOT (Heap-Only Tuple) updates when free space is available in the same page. HOT updates avoid creating new index entries, reducing both index bloat and vacuum workload.
The `job_blocker` table does not set a fillfactor because blockers are inserted and deleted without intermediate updates.
### Autovacuum
[Section titled “Autovacuum”](#autovacuum)
```sql
ALTER TABLE job SET (
autovacuum_vacuum_scale_factor = 0.02,
autovacuum_analyze_scale_factor = 0.02,
autovacuum_vacuum_cost_delay = 0
);
```
| Setting | Default | Configured | Effect |
| --------------------------------- | --------- | ---------- | --------------------------------------------------- |
| `autovacuum_vacuum_scale_factor` | 0.2 (20%) | 0.02 (2%) | Triggers vacuum after 2% dead tuples instead of 20% |
| `autovacuum_analyze_scale_factor` | 0.1 (10%) | 0.02 (2%) | Re-analyzes planner statistics after 2% row changes |
| `autovacuum_vacuum_cost_delay` | 2ms | 0 | Removes I/O throttling — vacuum runs at full speed |
These settings are applied per-table (not server-wide) to the `job` table. The `job_blocker` table sets only `autovacuum_vacuum_cost_delay = 0` since blockers are inserted and deleted without intermediate updates, producing less churn than the job table.
### On-Demand Vacuum
[Section titled “On-Demand Vacuum”](#on-demand-vacuum)
The adapter also exposes a `vacuum()` method that runs `VACUUM` on both job tables:
```typescript
await stateAdapter.vacuum();
```
PostgreSQL’s `VACUUM` (without `FULL`) does not block reads or writes — it reclaims dead tuples while the tables remain accessible. This complements autovacuum for cases where immediate reclamation is desired (e.g., after a large batch deletion in the cleanup job).
## Listing Queries and Vacuum
[Section titled “Listing Queries and Vacuum”](#listing-queries-and-vacuum)
`listChains` joins each root row with the last job in the chain via a lateral subquery. The `status` filter applies to the joined last job and cannot use an index — only `typeName` and date range filters narrow the scan before the join. Without these filters, every root row is scanned and joined.
Listing queries hold an MVCC snapshot for their duration. On tables with frequent writes, unfiltered scans hold snapshots longer, preventing autovacuum from reclaiming dead tuples and causing table bloat over time. The aggressive autovacuum settings above help mitigate this by reclaiming dead tuples more frequently between listing scans.
`listJobs` uses straightforward indexed scans without a join and is efficient at any scale.
## See Also
[Section titled “See Also”](#see-also)
* [Adapter Architecture](../adapters/) — Provider/adapter design philosophy
* [PostgreSQL Reference](/queuert/reference/postgres/) — API documentation
* [SQLite Internals](../sqlite-internals/) — SQLite-specific implementation
# Redis Internals
> Pub/sub channels, hint keys, and Lua scripts in the Redis notify adapter.
## Overview
[Section titled “Overview”](#overview)
This document describes the internal implementation of `@queuert/redis`. Redis is used exclusively as a **notification adapter** — it does not store job state. Job storage is handled by a separate state adapter (PostgreSQL or SQLite). Redis provides low-latency pub/sub notifications to wake workers when jobs are scheduled, with an atomic hint mechanism to prevent thundering herd.
## Data Structures
[Section titled “Data Structures”](#data-structures)
### Pub/Sub Channels
[Section titled “Pub/Sub Channels”](#pubsub-channels)
Three channels carry notifications between processes (configurable prefix, default `queuert`):
| Channel | Published When | Payload Format | Purpose |
| ----------------- | ------------------- | -------------- | ----------------------------- |
| `{prefix}:sched` | Jobs become pending | `{typeName}` | Wake idle workers |
| `{prefix}:chainc` | Chain completes | `{chainId}` | Wake clients awaiting results |
| `{prefix}:owls` | Lease reaped | `{jobId}` | Notify ownership loss |
Channels use Redis Pub/Sub — messages are fire-and-forget with no persistence. If no subscriber is listening when a message is published, it is lost. This is acceptable because workers fall back to polling when notifications are missed.
### Hint Keys
[Section titled “Hint Keys”](#hint-keys)
Hint counters are stored as Redis strings keyed by typeName, with a 60-second TTL:
```plaintext
{prefix}:hint:{typeName}
```
* **Type**: String (integer value)
* **TTL**: 60 seconds (auto-expires; refreshed on each `provideWakeHint` call)
* **Value**: Cumulative wakeup budget contributed by all publishers
Example: `queuert:hint:process-order` → `"5"`
Hints are managed via the `provideWakeHint`/`consumeWakeHint` pair on `NotifyAdapter`. The publisher calls `provideWakeHint(typeName, count)` (which adds `count` to the budget for this typeName), then `notifyJobScheduled(typeName)`. Workers receiving the notification call `consumeWakeHint(typeName)` and only query the database if the call returns `true`. Concurrent publishers contributing to the same typeName compose additively — two `provideWakeHint(t, 3)` calls produce a budget of 6.
## Lua Scripts
[Section titled “Lua Scripts”](#lua-scripts)
Two Lua scripts ensure atomicity for hint operations. Redis executes Lua scripts atomically — no other command can interleave.
### Provide Wake Hint
[Section titled “Provide Wake Hint”](#provide-wake-hint)
Adds `count` to the hint counter, refreshing the 60-second TTL:
```lua
local current = tonumber(redis.call('GET', KEYS[1])) or 0
redis.call('SET', KEYS[1], current + tonumber(ARGV[1]), 'EX', 60)
```
* `KEYS[1]`: Hint key (e.g., `queuert:hint:process-order`)
* `ARGV[1]`: Count to add
The atomic GET-then-SET ensures concurrent `provideWakeHint` calls compose additively without losing increments. The TTL refresh keeps long-lived budgets alive across notification batches.
### Consume Wake Hint
[Section titled “Consume Wake Hint”](#consume-wake-hint)
Atomically claims one slot of the budget, returning whether the worker should wake:
```lua
local current = redis.call('GET', KEYS[1])
if not current then
return 1
end
local n = tonumber(current)
if n and n > 0 then
redis.call('DECR', KEYS[1])
return 1
end
return 0
```
* Returns `1`: caller should wake (slot claimed, **or** hint key absent — graceful degradation)
* Returns `0`: budget exhausted by other consumers
The `not current` branch is the graceful-degradation case: if the hint key never existed or the TTL expired, listeners wake unconditionally rather than silently miss notifications. This trades a one-shot thundering herd for never losing a wakeup.
## Thundering Herd Prevention
[Section titled “Thundering Herd Prevention”](#thundering-herd-prevention)
The hint mechanism ensures that when N jobs are scheduled for a typeName, approximately N workers query the database — not all idle workers:
```plaintext
1. provideWakeHint("process-order", 3) → SET queuert:hint:process-order "3" EX 60
2. notifyJobScheduled("process-order") → PUBLISH queuert:sched "process-order"
Workers A, B, C, D, E receive the notification:
A: consumeWakeHint("process-order") → DECR hint to 2 → returns 1 → queries database ✓
B: consumeWakeHint("process-order") → DECR hint to 1 → returns 1 → queries database ✓
C: consumeWakeHint("process-order") → DECR hint to 0 → returns 1 → queries database ✓
D: consumeWakeHint("process-order") → GET hint = "0" → returns 0 → skips ✗
E: consumeWakeHint("process-order") → GET hint = "0" → returns 0 → skips ✗
```
Concurrent publishers compose: if two publishers each schedule 3 jobs of `process-order`, both call `provideWakeHint(t, 3)`, the budget becomes 6, and 6 workers wake across the two notifications.
Without hints, all 5 workers would query the database for 3 available jobs — wasted I/O. With hints, only 3 query. The hint counter has a 60-second TTL refreshed on each `provideWakeHint` call — if a budget goes unused, it eventually expires and the next notification triggers graceful-degradation wakeup.
## Connection Model
[Section titled “Connection Model”](#connection-model)
Redis Pub/Sub requires **two separate connections**:
1. **Command client** — for `PUBLISH`, `SET`, and `EVAL` (Lua scripts). Cannot be in subscribe mode.
2. **Subscription client** — for `SUBSCRIBE`/`UNSUBSCRIBE`. Blocked in subscribe mode, cannot execute regular commands.
The `RedisNotifyProvider` interface abstracts this — users manage the two connections in their provider implementation.
## Shared Listener Pattern
[Section titled “Shared Listener Pattern”](#shared-listener-pattern)
The adapter multiplexes multiple application-level listeners onto a single Redis subscription per channel:
```plaintext
Channel: queuert:sched
└── Redis SUBSCRIBE (single connection)
├── Worker A callback (filters for "process-order")
├── Worker B callback (filters for "send-email")
└── Worker C callback (filters for "process-order")
```
All mutations (subscribe / unsubscribe / dispose) serialize on a single async write lock so concurrent callers execute one at a time. The state is just `running` or `not running` — no intermediate `starting`/`stopping` bookkeeping.
* **Lazy start**: The Redis subscription is created when the first listener registers.
* **Shared**: Additional listeners attach callbacks without creating new subscriptions.
* **Lazy stop**: The subscription is torn down when the last listener unsubscribes.
This avoids creating a separate Redis subscription for each worker or job type.
## See Also
[Section titled “See Also”](#see-also)
* [Adapter Architecture](../adapters/) — Hint-based optimization design
* [Redis Reference](/queuert/reference/redis/) — API documentation
* [NATS Internals](../nats-internals/) — Alternative notify adapter
# SQLite Internals
> Schema, indexes, exclusive locking, and concurrency in the SQLite adapter.
## Overview
[Section titled “Overview”](#overview)
This document describes the internal implementation of `@queuert/sqlite` — the tables it creates, how it handles concurrency within SQLite’s single-writer model, and where it diverges from the PostgreSQL adapter.
## Schema
[Section titled “Schema”](#schema)
The adapter creates its schema via `migrateToLatest()`. All table names use a configurable prefix (default: `queuert_`).
### Job Table
[Section titled “Job Table”](#job-table)
The `{tablePrefix}job` table mirrors the PostgreSQL schema with SQLite-appropriate types:
| Column | Type | Description |
| --------------------- | ------------------------------ | ------------------------------------------------------------------- |
| `id` | configurable (default: `text`) | Primary key. Type set via `idType`, value generated by `generateId` |
| `type_name` | `TEXT` | Job type identifier |
| `chain_id` | same as `id` | Foreign key to root job |
| `chain_type_name` | `TEXT` | Type name of the chain |
| `chain_index` | `INTEGER` | Position in chain (0 for root) |
| `input` | `TEXT` | Job input as JSON string |
| `output` | `TEXT` | Completion output as JSON string |
| `status` | `TEXT` | Job state, constrained by CHECK |
| `created_at` | `TEXT` | ISO 8601 timestamp |
| `scheduled_at` | `TEXT` | ISO 8601 timestamp |
| `completed_at` | `TEXT` | ISO 8601 timestamp |
| `completed_by` | `TEXT` | Worker ID |
| `attempt` | `INTEGER` | Attempt count |
| `last_attempt_at` | `TEXT` | ISO 8601 timestamp |
| `last_attempt_error` | `TEXT` | Error as JSON string |
| `leased_by` | `TEXT` | Worker ID holding the lease |
| `leased_until` | `TEXT` | ISO 8601 timestamp |
| `deduplication_key` | `TEXT` | Deduplication key |
| `chain_trace_context` | `TEXT` | W3C traceparent |
| `trace_context` | `TEXT` | W3C traceparent |
Key differences from PostgreSQL:
* **No enum type**: Status uses `CHECK (status IN ('blocked', 'pending', 'running', 'completed'))` instead of a custom enum
* **TEXT for JSON**: SQLite stores JSON as plain TEXT, not JSONB. The adapter uses `json_each()` for parameterized array operations
* **TEXT for timestamps**: ISO 8601 strings with `datetime('now', 'subsec')` for subsecond precision
* **Application-generated IDs**: Since SQLite lacks `gen_random_uuid()`, IDs are generated by the `generateId` function before insertion
### Foreign Keys
[Section titled “Foreign Keys”](#foreign-keys)
The `chain_id` column references `job(id)`. SQLite has foreign keys disabled by default — the adapter issues `PRAGMA foreign_keys = ON` at connection time. This must be done on every connection; it is not persisted.
The `checkForeignKeys` option (default: `true`) causes `migrateToLatest()` to verify that `PRAGMA foreign_keys` is enabled and throws with a clear error message if not. Disable this check only if foreign key enforcement is managed externally.
### Job Blocker Table
[Section titled “Job Blocker Table”](#job-blocker-table)
The `{tablePrefix}job_blocker` table is structurally identical to PostgreSQL:
| Column | Type | Description |
| --------------------- | ------------------ | -------------------------------- |
| `job_id` | foreign key to job | The blocked job |
| `blocked_by_chain_id` | foreign key to job | Root job ID of the blocker chain |
| `index` | `INTEGER` | Position in blockers array |
| `trace_context` | `TEXT` | PRODUCER span context |
Primary key: `(job_id, blocked_by_chain_id)`.
### Migration Table
[Section titled “Migration Table”](#migration-table)
Same structure as PostgreSQL, tracking applied migrations by name and timestamp.
## Indexes
[Section titled “Indexes”](#indexes)
The SQLite adapter creates the same set of indexes as PostgreSQL, using partial indexes (`WHERE` clauses) where supported:
| Index | Definition | Purpose |
| ----------------------------- | ---------------------------------------------------------------------------------------------- | --------------------------- |
| `job_acquisition_idx` | `(type_name, scheduled_at) WHERE status = 'pending'` | Job acquisition |
| `chain_index_idx` | `UNIQUE (chain_id, chain_index)` | Chain position uniqueness |
| `job_deduplication_idx` | `(deduplication_key, created_at DESC) WHERE deduplication_key IS NOT NULL AND chain_index = 0` | Deduplication lookup |
| `job_expired_lease_idx` | `(type_name, leased_until) WHERE status = 'running' AND leased_until IS NOT NULL` | Lease reaping |
| `job_blocker_chain_idx` | `(blocked_by_chain_id)` on job\_blocker | Blocker resolution |
| `chain_listing_idx` | `(created_at DESC) WHERE chain_index = 0` | Chain listing |
| `job_listing_idx` | `(created_at DESC)` | Job listing |
| `job_listing_status_idx` | `(status, created_at DESC)` | Filtered listing |
| `job_listing_type_name_idx` | `(type_name, created_at DESC)` | Type-filtered listing |
| `chain_listing_type_name_idx` | `(type_name, created_at DESC) WHERE chain_index = 0` | Type-filtered chain listing |
## Locking and Concurrency
[Section titled “Locking and Concurrency”](#locking-and-concurrency)
SQLite’s concurrency model differs fundamentally from PostgreSQL. There is no row-level locking — writes are serialized at the database level.
### BEGIN (DEFERRED) + operation-level locking
[Section titled “BEGIN (DEFERRED) + operation-level locking”](#begin-deferred--operation-level-locking)
The bundled providers start transactions with plain `BEGIN`:
```sql
BEGIN;
-- operations
COMMIT;
```
Under `BEGIN DEFERRED`, no lock is taken until the first write. Operations that need write-intent on a row before reading it (worker lease refetches, chain extension in `triggerJobs`) pass `lock: "exclusive"` to `getJob` / `getChain`. The SQLite adapter implements this with a no-op `UPDATE ... SET id = id RETURNING *`, which promotes the transaction to `RESERVED` and blocks other writers until commit. This mirrors the role `FOR UPDATE` plays in the Postgres adapter.
`BEGIN IMMEDIATE` is *not* used by the bundled providers — it would force every transaction to take `RESERVED` upfront, including read-only ones. With WAL + a connection pool, that defeats the point of allowing concurrent readers.
### AsyncRwLock
[Section titled “AsyncRwLock”](#asyncrwlock)
Since SQLite serializes writes at the database level (but permits concurrent reads), the adapter adds an application-level `AsyncRwLock` to prevent concurrent write access from async code within the same process while allowing reads to run in parallel:
```typescript
const lock = createAsyncRwLock();
executeSql: async ({ txCtx, sql, params, readOnly }) => {
if (txCtx) return executeRaw(/* ... */); // Lock already held
using _h = readOnly ? await lock.acquireRead() : await lock.acquireWrite();
return executeRaw(/* ... */);
};
```
* **Outside a transaction**: Every SQL execution acquires the lock in the mode indicated by `readOnly` (pure `SELECT` → read; anything else → write)
* **Inside a transaction**: The write lock was already acquired by `withTransaction`, so individual operations skip it
The lock is writer-preference and FIFO to prevent writer starvation: once a writer is queued, new readers wait. The handle returned from `acquireRead`/`acquireWrite` implements `Symbol.dispose`, so `using` releases at scope exit.
Custom `SqliteStateProvider` implementations must use `createAsyncRwLock()` to ensure correct serialization.
### No SKIP LOCKED
[Section titled “No SKIP LOCKED”](#no-skip-locked)
SQLite has no equivalent to `FOR UPDATE SKIP LOCKED`. The acquisition query uses a subquery-based atomic UPDATE instead:
```sql
UPDATE job
SET status = 'running', attempt = attempt + 1
WHERE id = (
SELECT id FROM job
WHERE type_name IN (SELECT value FROM json_each(?))
AND status = 'pending'
AND scheduled_at <= datetime('now', 'subsec')
ORDER BY scheduled_at ASC
LIMIT 1
)
RETURNING *, EXISTS(...) AS has_more
```
This is safe because SQLite’s exclusive locking ensures only one writer executes at a time — there is no concurrent acquisition to contend with. The trade-off is that SQLite cannot process jobs in parallel from multiple processes.
### Savepoints
[Section titled “Savepoints”](#savepoints)
The adapter supports nested operations via SQLite savepoints:
```sql
SAVEPOINT queuert_sp;
-- nested operation
RELEASE SAVEPOINT queuert_sp;
-- or on error: ROLLBACK TO SAVEPOINT queuert_sp;
```
Used for partial rollback within transactions — if a user callback or observability event fails, the savepoint rolls back without aborting the outer transaction.
## No Writeable CTEs
[Section titled “No Writeable CTEs”](#no-writeable-ctes)
SQLite does not support writeable CTEs with RETURNING in the same way as PostgreSQL. Operations that PostgreSQL handles in a single CTE are split into multiple sequential queries within a transaction:
* **`addJobBlockers`**: Separate INSERT for blockers, then UPDATE for job status
* **`deleteChains`**: Separate SELECT to find connected chains, DELETE blockers, DELETE jobs
* **`unblockJobs`**: Separate DELETE for resolved blockers, SELECT to check remaining, UPDATE for unblocked jobs
This results in more round-trips per operation, but is safe under SQLite’s exclusive locking model. See [Adapter Architecture](../adapters/) for the design rationale.
## Timestamp Arithmetic
[Section titled “Timestamp Arithmetic”](#timestamp-arithmetic)
SQLite uses Julian day conversion for time calculations:
```sql
MAX(0, CAST(
(julianday(job.scheduled_at) - julianday(datetime('now', 'subsec'))) * 86400000
AS INTEGER)) AS available_in_ms
```
This calculates milliseconds until a scheduled job is ready, multiplying the Julian day difference by 86,400,000 (milliseconds per day).
## Notifications
[Section titled “Notifications”](#notifications)
SQLite has no built-in notification mechanism like PostgreSQL’s `LISTEN`/`NOTIFY`. The adapter uses the in-process notify adapter (`createInProcessNotifyAdapter`), which provides synchronous event delivery within a single process. This means SQLite deployments are limited to single-process operation for notification delivery.
For multi-process deployments, an external notify adapter (Redis or NATS) can be paired with the SQLite state adapter.
## Vacuum
[Section titled “Vacuum”](#vacuum)
SQLite does not reclaim disk space from deleted rows automatically by default. The adapter exposes a `vacuum()` method that runs `PRAGMA incremental_vacuum` to free reclaimable pages without rewriting the entire database:
```typescript
await stateAdapter.vacuum();
```
This requires `PRAGMA auto_vacuum = INCREMENTAL` to be set on the database before any tables are created:
```typescript
const db = new Database("queue.db");
db.pragma("auto_vacuum = INCREMENTAL");
db.pragma("foreign_keys = ON");
```
Incremental vacuum frees pages that are already marked as free by prior DELETE operations. It does not rewrite the database or defragment it — it only returns free pages to the OS. This makes it safe to call frequently (e.g., after each cleanup run) without blocking other operations for extended periods.
## Listing Queries and Locking
[Section titled “Listing Queries and Locking”](#listing-queries-and-locking)
`listChains` joins each root row with the last job in the chain. The `status` filter applies to the joined last job and cannot use an index — only `typeName` and date range filters narrow the scan before the join. Without these filters, every root row is scanned and joined. On deployments with frequent writes, unfiltered scans over large tables can extend write queue wait times because the read lock is held longer.
`listJobs` uses straightforward indexed scans without a join and is efficient at any scale.
## See Also
[Section titled “See Also”](#see-also)
* [Adapter Architecture](../adapters/) — Provider/adapter design philosophy
* [SQLite Reference](/queuert/reference/sqlite/) — API documentation
* [PostgreSQL Internals](../postgres-internals/) — PostgreSQL-specific implementation
# Benchmarks
> Processing capacity, memory footprint, and type complexity benchmarks for Queuert.
## Processing Capacity
[Section titled “Processing Capacity”](#processing-capacity)
Job throughput measured in two phases: starting chains (chains/s) and processing them to completion (jobs/s). Each adapter is exercised across four orthogonal modes — single vs. batched start (`startChain` one at a time vs. `startChains` in batches of 100), and atomic vs. staged processing (see [Job Processing Modes](./guides/processing-modes/)). To avoid doubling the wall-clock, the four numbers are folded into two runs per adapter: atomic-process pairs with batched-start, staged-process pairs with single-start. The pairing is layout-only — start mode and process mode are independent in production. Each run uses 5,000 chains × concurrency 10, in its own child process for isolation (Node.js v22, Apple M1 Pro). State and notify are measured along separate axes — when one is varied, the other is held at the in-process default. PostgreSQL, Redis, and NATS run as Dockerized containers on macOS (Docker Desktop), so per-RTT latency includes the VM bridge — numbers reflect that environment rather than a host-native or production deployment.
The Start columns measure two ends of the realistic range: **single** is a tight `await client.startChain(...)` loop, dominated by per-call RTT (HTTP-handler-shaped traffic); **batched** is `client.startChains({ items: [...100] })`, amortizing transaction and notify overhead across the batch (bulk-enqueue / migration / replay traffic). Real workloads sit between the two depending on call shape and concurrency.
The Process columns measure how fast a single worker drains the queue once it’s full. Atomic mode wraps each attempt in one transaction; staged mode adds an empty `prepare({ mode: "staged" })` round-trip before `complete`, isolating the pure cost of the second transaction without confounding with handler work. Steady-state deployment throughput is bounded by `min(start, process)`.
### State adapter (no notify)
[Section titled “State adapter (no notify)”](#state-adapter-no-notify)
| State adapter | Start single (chains/s) | Start batched (chains/s) | Process atomic (jobs/s) | Process staged (jobs/s) |
| ------------------------ | ----------------------: | -----------------------: | ----------------------: | ----------------------: |
| In-process | \~67,459 | \~173,791 | \~17,753 | \~12,191 |
| SQLite (better-sqlite3) | \~21,757 | \~51,653 | \~10,214 | \~6,837 |
| SQLite (node:sqlite) | \~20,208 | \~51,833 | \~8,286 | \~5,747 |
| PostgreSQL (postgres-js) | \~504 | \~20,317 | \~725 | \~634 |
| PostgreSQL (pg) | \~584 | \~20,880 | \~766 | \~647 |
### Notify adapter (in-process state)
[Section titled “Notify adapter (in-process state)”](#notify-adapter-in-process-state)
| Notify adapter | Start single (chains/s) | Start batched (chains/s) | Process atomic (jobs/s) | Process staged (jobs/s) |
| ------------------------ | ----------------------: | -----------------------: | ----------------------: | ----------------------: |
| In-process | \~64,051 | \~191,963 | \~17,829 | \~12,322 |
| Redis (redis) | \~2,478 | \~68,248 | \~8,932 | \~6,364 |
| Redis (ioredis) | \~2,485 | \~72,958 | \~10,868 | \~7,892 |
| PostgreSQL (pg) | \~3,871 | \~72,343 | \~7,863 | \~5,590 |
| PostgreSQL (postgres-js) | \~3,864 | \~70,733 | \~7,675 | \~4,787 |
| NATS | \~4,275 | \~107,948 | \~10,286 | \~7,129 |
See [processing-capacity](https://github.com/kvet/queuert/tree/main/benchmarks/processing-capacity) for the full benchmark tool.
## Memory Footprint
[Section titled “Memory Footprint”](#memory-footprint)
Each adapter is exercised through a full lifecycle: build adapters → process 100 jobs → `close()`. A discarded warmup run beforehand stabilizes V8 JIT and lazy module loads (Node.js v22, Apple M1 Pro). Four numbers are reported, all measured against an infrastructure baseline taken after warmup. Snapshot-based, because `process.memoryUsage().heapUsed` significantly over-reports retention by including V8 fragmentation and code arena outside the live object graph.
* **Setup overhead** — heap allocated by all queuert pieces (state adapter, notify adapter, client, in-process worker) when fully built but before any jobs run.
* **In-flight peak** — heap during the processing of 100 concurrent jobs.
* **Live JS retained after close** — live-JS-object-graph delta from the infra baseline after `close()`. This is what answers “does queuert leak heap?”.
* **JIT code retained after close** — V8-compiled instruction streams retained by the process. This is module-permanent (Node modules don’t unload, so JIT’d functions stay), not a per-lifecycle leak. Reported separately so the picture is honest.
| Benchmark | Setup overhead | In-flight peak | Live JS retained | JIT code retained |
| ----------------- | -------------: | -------------: | ---------------: | ----------------: |
| `notify-redis` | \~80 KB | \~255 KB | \~10 KB | \~65 KB |
| `notify-postgres` | \~545 KB | \~705 KB | \~10 KB | \~35 KB |
| `notify-nats` | \~485 KB | \~640 KB | \~10 KB | \~40 KB |
| `state-sqlite` | \~465 KB | \~490 KB | \~10 KB | \~70 KB |
| `state-postgres` | \~510 KB | \~760 KB | \~20 KB | \~180 KB |
| `dashboard` | \~610 KB | \~795 KB | \~10 KB | \~85 KB |
| `otel` | \~45 KB | \~240 KB | \~10 KB | \~85 KB |
The Live JS retained column is consistently \~10 KB across all adapters — that’s V8 hidden classes and shape descriptors that persist from method invocations, not queuert state. The JIT code retained scales with adapter complexity: more SQL queries / driver code paths exercised → more functions JIT-compiled → more code retained. Both are one-time costs of *running* the library in a process, not retention that grows per job or per lifecycle.
The driver/connection cost (e.g. node-redis client, postgres-js pool, NATS connection) lives outside queuert’s lifecycle and is measured separately in the per-run output, not aggregated here.
See [memory-footprint](https://github.com/kvet/queuert/tree/main/benchmarks/memory-footprint) for the full measurement tool, methodology details, and per-step breakdowns.
## Type Complexity
[Section titled “Type Complexity”](#type-complexity)
Queuert’s type-level machinery scales linearly across chain topologies (prebuilt `.d.mts`, Node.js v22, Apple M1 Pro):
### tsc (6.0.2)
[Section titled “tsc (6.0.2)”](#tsc-602)
| Scenario | Types | Time | Instantiations | Scaling |
| ------------------ | ----: | --------: | -------------: | ------: |
| Linear: 1 type | 1 | \~554ms | 20,644 | 1.0x |
| Linear: 10 types | 10 | \~583ms | 30,481 | 1.5x |
| Linear: 50 types | 50 | \~762ms | 72,081 | 3.5x |
| Linear: 100 types | 100 | \~993ms | 124,081 | 6.0x |
| Branched: 4w x 3d | 85 | \~981ms | 104,856 | 5.1x |
| Branched: 2w x 6d | 127 | \~1,175ms | 148,556 | 7.2x |
| Blockers: 8 steps | 30 | \~661ms | 54,136 | 2.6x |
| Blockers: 25 steps | 98 | \~987ms | 160,488 | 7.8x |
| Loop: 20 steps | 21 | \~653ms | 44,654 | 2.2x |
| Loop: 50 steps | 51 | \~834ms | 79,964 | 3.9x |
| Merge: 2 x 50 | 100 | \~974ms | 128,242 | 6.2x |
| Merge: 5 x 50 | 250 | \~1,511ms | 281,574 | 13.6x |
| Merge: 10 x 50 | 500 | \~2,390ms | 537,404 | 26.0x |
| Merge: 20 x 50 | 1,000 | \~4,070ms | 1,049,169 | 50.8x |
| Merge: 50 x 50 | 2,500 | \~9,630ms | 2,589,554 | 125.4x |
### Practical limits
[Section titled “Practical limits”](#practical-limits)
| Configuration | Status |
| ------------------------------------------- | ---------------- |
| Up to 100 types in a single linear chain | OK, \~1.0s (tsc) |
| Branched chains up to 2w x 6d (\~127 types) | OK, \~1.2s (tsc) |
| Blockers: up to 25 steps, 3 blockers each | OK, <1s (tsc) |
| Loops: up to 50 self-referencing steps | OK, <1s (tsc) |
| Merging 10 slices of 50 types (500 total) | OK, \~2.4s (tsc) |
| Merging 50 slices of 50 types (2500 total) | OK, \~9.6s (tsc) |
See [type-complexity](https://github.com/kvet/queuert/tree/main/benchmarks/type-complexity) for the full benchmark tool and detailed results.
# Comparison
> How Queuert relates to other background-work libraries.
Queuert is a **job-chain library** — durable, typed background work in your database. It sits between job queues and workflow engines: a one-job chain *is* a queue; a multi-step chain with blockers is closer to a workflow. Neither label fully fits, so Queuert isn’t a drop-in replacement for any single neighbor — but readers evaluating it usually arrive from one. This section has one page per neighbor, each structured the same way: what each tool is, where they aren’t directly comparable, what each is good at, practical differences worth knowing about, and how to choose between them.
[vs. pg-boss ](/queuert/comparison/pg-boss/)A Postgres-backed job queue. Same storage tier, different category.
[vs. BullMQ ](/queuert/comparison/bullmq/)A Redis-backed job queue. Different storage tier, different category.
[vs. Temporal ](/queuert/comparison/temporal/)A distributed workflow platform. Different category — both can model multi-step durable work.
[vs. Inngest ](/queuert/comparison/inngest/)An event-driven workflow platform. Different category, different trigger model.
## How to read these comparisons
[Section titled “How to read these comparisons”](#how-to-read-these-comparisons)
Each page tries to be even-handed: what the neighbor is genuinely good at first, what Queuert is good at second, where they overlap, and where they don’t. The decision is rarely “X is better than Y” — it’s usually “are these the same shape of tool?” and, if not, “which shape fits the problem at hand?”
If your problem involves multiple shapes of work — high-throughput queue lanes *and* chain-shaped sequences, or transactional handlers *and* long-lived signal-driven workflows — those are different concerns that may genuinely deserve different tools. They aren’t strict substitutes.
## At-a-glance
[Section titled “At-a-glance”](#at-a-glance)
| | Queuert | pg-boss | BullMQ | Temporal | Inngest |
| -------------------------------- | --------------------- | ------------------- | ---------------- | -------------------------- | ------------------------------- |
| Category | Job-chain library | Job queue | Job queue | Workflow platform | Workflow platform |
| Storage | Your DB (PG / SQLite) | Postgres | Redis | Separate cluster (or SaaS) | Inngest server (managed or OSS) |
| Operate a server? | No | No | Redis | Yes | Yes |
| Transactional enqueue | ✅ structural | 🟡 per-call adapter | ❌ app discipline | ❌ app discipline | ❌ app discipline |
| Transactional handler completion | ✅ structural | 🟡 per-call adapter | ❌ app discipline | ❌ app discipline | ❌ app discipline |
| Typed multi-step chains | ✅ end-to-end | ❌ | 🟡 FlowProducer | ✅ workflow code | ✅ functions + steps |
| Resume work days/weeks later | ✅ schedule next step | ✅ `sendAfter` | ✅ `delay` option | ✅ in-line `sleep('30d')` | ✅ in-line `step.sleep('30d')` |
The full text on each row, with maintainer quotes and source citations, is on the per-neighbor pages.
# BullMQ
> How Queuert relates to BullMQ — different tools for different shapes of background work.
[BullMQ](https://github.com/taskforcesh/bullmq) is the most established Redis-backed job queue in the Node.js ecosystem. Queuert and BullMQ both run background work, but they sit on different storage tiers and approach the problem from different categories.
> Compared versions: Queuert `0.12.0` and BullMQ `5.76.6`.
## What BullMQ is
[Section titled “What BullMQ is”](#what-bullmq-is)
BullMQ is a **Redis-backed job queue**. The mental model is messages on Redis lists and sorted sets, moved between states by atomic Lua scripts. Workers block on `BZPOPMIN` and process jobs in process or in sandboxed child processes. Comes with priority, rate limiting, parent/child flows (`FlowProducer`), repeatable jobs / cron, sandbox isolation, and cross-language workers (Python, Elixir, PHP) that share the same Lua scripts.
You install it, point it at Redis, create queues, and `add` jobs. Workers either run in your process or in sandboxed child processes.
## What Queuert is
[Section titled “What Queuert is”](#what-queuert-is)
Queuert is a **job-chain library** — durable, typed background work in your database. Job chains compose like Promise chains (`.then`, `Promise.all`), but they survive crashes and commit with your transactions.
The unit isn’t a message on a queue — it’s a typed **chain** of jobs of (potentially different) types, where each job’s `continueWith` enqueues the next one in the same chain. Inputs, outputs, continuations, and blockers are inferred end-to-end via `defineJobTypes`. Chains start *inside* your DB transactions, so the work that follows a write commits-or-rolls-back with the data that triggered it.
Queuert sits between job queues and workflow engines: a one-job chain *is* a queue; a multi-step chain with blockers is closer to a workflow. Neither label fully fits — which is why the canonical term is “job-chain library.”
## They aren’t directly comparable
[Section titled “They aren’t directly comparable”](#they-arent-directly-comparable)
BullMQ and Queuert run on different storage tiers and model different problems:
* **Queue concepts** like priority, rate limiting, sandboxed processors, and atomic Lua scripts are central to BullMQ because BullMQ is a high-throughput Redis queue. They’re absent from Queuert because Queuert isn’t modeling messages-on-Redis — it’s modeling chained workflows tied to DB transactions.
* **Chain concepts** like typed continuations, blocker DAGs, and transactional enqueue tied to your DB are central to Queuert because Queuert is a job-chain library that lives in your DB. They’re absent from BullMQ because BullMQ lives in Redis, separate from your domain data.
The narrow overlap is “both let you defer work into the background.” Beyond that, the storage model and the shape diverge.
## What BullMQ is good at
[Section titled “What BullMQ is good at”](#what-bullmq-is-good-at)
* **Speed.** Redis lists/sorted sets and Lua-script atomicity make BullMQ the fastest path among Node queue libraries on raw throughput and wakeup latency. `BZPOPMIN` typically wakes in sub-millisecond.
* **Sandboxed processors.** Pass a `processFile` path; BullMQ runs handlers in separate Node processes (or worker threads) via a child pool. Real isolation and crash containment.
* **Cross-language workers.** Python, Elixir, and PHP clients share the same Lua scripts. The Redis state is the contract.
* **Rich queue primitives.** Priority (0–2,097,152), rate limiting (per queue, per key), parent/child flows via `FlowProducer`, repeat / cron schedules, deduplication windows.
* **Mature ecosystem.** Bull Board (third-party OSS dashboard), Taskforce.sh dashboards (paid), proxy package for serverless, broad deployment.
These are what a *Redis queue* should be good at, and BullMQ invests heavily in them.
## What Queuert is good at
[Section titled “What Queuert is good at”](#what-queuert-is-good-at)
* **Chained execution of typed jobs.** A chain is a typed sequence: `"send-email"` continues with `"log-sent"` continues with `"update-user-status"`. Each step’s input/output type is inferred from the previous step’s `continueWith`. Renames are compiler-checked.
* **Fan-in via blockers.** “Wait for these N independent chains to finish, then run X” is a typed primitive backed by a `job_blocker` table — not glue code.
* **Transactional consistency, by design.** `startChain` enqueues inside your DB transaction; handler completion + next-step `continueWith` commit in the same transaction as your domain writes. For DB-bound work, no outbox at enqueue and no idempotency-key ritual at processing — both halves are structural, not application discipline.
* **Database as the system of record.** Workflow state lives in the same DB as your domain data. No separate store, no separate consistency model, no separate operational target.
* **Pluggable transports.** State (Postgres / SQLite / in-process) and notify (LISTEN/NOTIFY / Redis / NATS / polling) are independent.
These are what a *job-chain library* should be good at, and Queuert is built around them.
## Differences worth knowing about
[Section titled “Differences worth knowing about”](#differences-worth-knowing-about)
A few practical differences:
* **Storage tier.** BullMQ requires Redis; durability depends on your Redis configuration (RDB / AOF / fsync settings). Queuert uses Postgres or SQLite; durability is whatever your DB gives you.
* **Wakeup mechanism.** BullMQ’s `BZPOPMIN` blocking pop wakes in sub-millisecond. Queuert’s `LISTEN/NOTIFY` (or Redis pub/sub, or NATS) wakes in tens of milliseconds.
* **Transactional consistency.** BullMQ’s queue lives in Redis, separate from your domain DB — so both ends require application discipline. *Enqueue:* dual-write between your DB and Redis is structural; transactional `add` isn’t possible. *Processing:* BullMQ’s [Important Notes](https://docs.bullmq.io/bull/important-notes) describe at-least-once execution and warn that on lock expiration the job is “double processed” — handlers must be idempotent. With Queuert, both halves commit inside your DB transaction; for DB-bound work, no outbox and no idempotency-key ritual.
* **Sandboxing.** BullMQ provides first-class sandboxed processors. Queuert runs handlers in your worker process; isolation is your application’s concern.
* **Cross-language workers.** BullMQ has SDKs in several languages sharing the same Redis state. Queuert is Node-only.
* **Failure shape.** BullMQ’s `failed` sorted set acts as the dead-letter queue; you re-process via `job.retry()`. Queuert leaves the error as data on the chain (`last_attempt_error`) and lets the application decide what to do next.
## Choosing between them
[Section titled “Choosing between them”](#choosing-between-them)
**Reach for BullMQ when:**
* You already operate Redis and accept it as durable storage (or are fine with the loss-on-crash trade-off).
* You need sub-millisecond wakeup latency and high raw throughput.
* You want sandboxed processors for crash containment, untrusted handlers, or memory limits.
* You need cross-language workers (Python / Elixir / PHP).
* Your problem is naturally queue-shaped: messages, lanes, routing, rate limits.
**Reach for Queuert when:**
* Your problem is naturally chain-shaped: typed multi-step sequences where this job continues with that job, possibly waiting on others.
* You want enqueue to commit-or-rollback structurally with the data that triggered it.
* Your DB is already the system of record and you’d rather not introduce a second durable store.
* Sub-second (not sub-millisecond) wakeup latency via `LISTEN/NOTIFY` (or Redis / NATS) is enough.
If you genuinely need both — high-throughput queue work *and* chain-shaped sequences tied to your DB — those are different concerns and deserve different tools. They aren’t substitutes.
# Inngest
> How Queuert relates to Inngest — different categories that overlap on multi-step durable work.
[Inngest](https://www.inngest.com) and Queuert both express multi-step durable work, but they’re different categories of tool. Inngest is an event-driven workflow platform; Queuert is a job-chain library. Their starting points and deployment shapes are different.
> Compared versions: Queuert `0.12.0` and the Inngest SDK `inngest@4.3.0`.
## What Inngest is
[Section titled “What Inngest is”](#what-inngest-is)
Inngest is an **event-driven durable-function platform**. The mental model is events that trigger functions; each function is composed of `step.run` blocks whose results are persisted server-side. Functions execute inside HTTP handlers in your application — there’s no worker process — with the Inngest server invoking your `serve()` adapter and re-invoking it as steps complete. Built-in primitives for concurrency, rate-limiting, throttling, debouncing, priority, cron, `step.sleep('30d')`, `step.waitForEvent`, and fan-out via subscribe.
You install the SDK, mount a `serve()` adapter at `/api/inngest`, and either rent the managed Inngest Cloud or operate the OSS Go server. Functions are defined in your app and discovered by the server when it pings your endpoint.
## What Queuert is
[Section titled “What Queuert is”](#what-queuert-is)
Queuert is a **job-chain library** — durable, typed background work in your database. Job chains compose like Promise chains (`.then`, `Promise.all`), but they survive crashes and commit with your transactions.
The unit is a typed **chain** of jobs of (potentially different) types, where each job’s `continueWith` enqueues the next one in the same chain. Inputs, outputs, continuations, and blockers are inferred end-to-end via `defineJobTypes`. Chains start *inside* your DB transactions, so the work that follows a write commits-or-rolls-back with the data that triggered it.
No separate server. No event-driven dispatch. No HTTP-handler execution shape. Just typed chains in a couple of tables next to your domain data, processed by a worker in your Node process.
## Different tools — overlapping problem space
[Section titled “Different tools — overlapping problem space”](#different-tools--overlapping-problem-space)
Both can express multi-step durable work, but they start from different places:
* **Inngest** starts from events. You publish events; functions subscribe to them. Multiple functions can subscribe to the same event (fan-out). Long-lived workflows pause via `step.sleep` / `step.waitForEvent` and resume when conditions are met. Functions execute as HTTP request/response cycles invoked by the Inngest server.
* **Queuert** starts from database transactions. You write data and start a chain in the same transaction. Continuations propagate forward via `continueWith`. Workers in your process pull and execute jobs.
Both can model “a 5-step background workflow.” The difference shows up in (1) how it’s triggered, (2) where it executes, and (3) what runtime it requires.
## What Inngest is good at
[Section titled “What Inngest is good at”](#what-inngest-is-good-at)
* **Event-driven workflows.** Publishing an event can fan out to many subscribed functions. `step.waitForEvent('payment.completed', { match: '...' })` durably waits for a future event to arrive.
* **Long-lived durable waits.** `step.sleep('30 days')` survives restarts, redeploys, region failovers — the server handles re-invocation.
* **Rich orchestration knobs.** First-class concurrency limits (per-key, expression-keyed), rate limiting, throttling, debouncing, priority — directly on the function definition.
* **HTTP-handler execution shape.** Functions live next to your routes and run on whatever HTTP runtime you already have (Vercel, Cloudflare, Lambda, Express, etc.). No worker process to manage.
* **Hosted option.** Inngest Cloud handles the server-side concerns; the OSS Go server is the self-hosted alternative.
* **Cross-language SDKs.** TypeScript, Python, Go, Kotlin, Elixir, Rust.
These are what a *managed event-driven workflow platform* should be good at.
## What Queuert is good at
[Section titled “What Queuert is good at”](#what-queuert-is-good-at)
* **Chained execution of typed jobs.** Multi-step work as a typed sequence; inputs, outputs, continuations, and blockers infer end-to-end via `defineJobTypes`. Renames are compiler-checked.
* **Transactional consistency, by design.** `startChain` enqueues inside your DB transaction; handler completion + next-step `continueWith` commit in the same transaction as your domain writes. For DB-bound work, no outbox at enqueue and no idempotency-key ritual at processing — both halves are structural, not application discipline.
* **Operational simplicity.** No platform to depend on, no service to operate. Your existing Postgres (or SQLite) is the entire backing store.
* **Database as the system of record.** Chain state lives next to your domain data. Same DB, same backups, same observability.
* **Plain in-process workers.** Handlers run in your Node process; closures over outer scope work normally; no per-step HTTP roundtrip cost.
These are what a *job-chain library* should be good at.
## Differences worth knowing about
[Section titled “Differences worth knowing about”](#differences-worth-knowing-about)
A few practical differences:
* **Trigger model.** Inngest is event-first: you `inngest.send({ name, data })` and matching functions run. Queuert is transaction-first: you `client.startChain({ typeName, input })` inside a DB transaction.
* **Where execution happens.** Inngest functions run in your HTTP handlers, invoked by the Inngest server. Queuert handlers run in your worker process, pulled from the DB.
* **Where state lives.** Inngest server (managed or self-hosted) owns step state and event histories. Queuert keeps everything in your application’s DB.
* **Per-step cost.** Each Inngest `step.run` is an HTTP roundtrip to the Inngest server (sync checkpointing). Queuert does one DB transaction per attempt; a chain of 5 jobs is 5 DB transactions, no platform RTT.
* **Long durable waits.** Inngest’s `step.sleep('30d')` and `step.waitForEvent` survive crashes / deploys. Queuert can schedule the next attempt for a future time, but doesn’t carry an awaiting call-stack.
* **Transactional consistency.** Inngest state lives on the Inngest server — so both ends require application discipline. *Enqueue:* `inngest.send` posts over HTTP independently of your DB transaction; dual-write is the default. *Processing:* Inngest’s own [Errors & Retries](https://www.inngest.com/docs/guides/error-handling) doc tells users *“a step inserting a new user to the database is not idempotent while a step upserting a user is”* — `step.run` is at-least-once until the result reaches the server. With Queuert, both halves commit inside your DB transaction; for DB-bound work, no outbox and no idempotency-key ritual.
* **Vendor / hosting story.** Inngest Cloud is the easy path; self-hosting the OSS server is possible but newer. Queuert has no vendor — your existing DB is the entire dependency.
## Choosing between them
[Section titled “Choosing between them”](#choosing-between-them)
**Reach for Inngest when:**
* Your work is naturally event-driven: webhooks fan out, long-pending workflows resume on a future event, durable sleeps measured in days.
* You want first-class concurrency / rate-limit / throttle / debounce knobs without writing them yourself.
* You’re comfortable with Inngest Cloud (or operating the OSS server) as a dependency.
* HTTP-handler execution fits your runtime (Vercel / Cloudflare / Lambda / etc.).
* You can accept the dual-write story and use idempotency keys to make it safe.
**Reach for Queuert when:**
* Your work is naturally transaction-driven: this DB write commits, then this background work follows.
* You want enqueue to commit-or-rollback structurally with your DB transaction — no dual-write window.
* You don’t want to depend on a SaaS or operate a separate workflow server.
* Plain TypeScript handlers in your worker process are simpler than per-step HTTP roundtrips.
* Your DB is the system of record and you want chain state living there too.
Both can express multi-step durable work. The forcing question is usually whether your problem is shaped more like “events trigger functions” or “transactions create chains” — and how comfortable you are with the platform/dependency that comes with the event-driven shape.
# pg-boss
> How Queuert relates to pg-boss — different tools for different shapes of background work.
[pg-boss](https://github.com/timgit/pg-boss) and Queuert both run background work and both store it in Postgres. They aren’t the same kind of tool, and choosing between them is mostly a question of which kind you need.
> Compared versions: Queuert `0.12.0` and pg-boss `12.18.2`.
## What pg-boss is
[Section titled “What pg-boss is”](#what-pg-boss-is)
pg-boss is a **Postgres-backed job queue**. The mental model is messages routed through named queues, with rich policies attached to each queue (singleton, exclusive, strict-FIFO, throttling), retries with backoff, cron schedules, dead-letter queues, and a supervisor that runs maintenance for you. Seven years of production use, polling-based, Postgres-only.
You install it, point it at Postgres, create queues, and `send` jobs to them. Workers poll those queues and run handlers.
## What Queuert is
[Section titled “What Queuert is”](#what-queuert-is)
Queuert is a **job-chain library** — durable, typed background work in your database. Job chains compose like Promise chains (`.then`, `Promise.all`), but they survive crashes and commit with your transactions.
The unit isn’t a message on a queue — it’s a typed **chain** of jobs of (potentially different) types, where each job’s `continueWith` enqueues the next one in the same chain. Inputs, outputs, continuations, and blockers are inferred end-to-end via `defineJobTypes`. Chains start *inside* your DB transactions, so the work that follows a write commits-or-rolls-back with the data that triggered it.
Queuert sits between job queues and workflow engines: a one-job chain *is* a queue; a multi-step chain with blockers is closer to a workflow. Neither label fully fits — which is why the canonical term is “job-chain library.”
## They aren’t directly comparable
[Section titled “They aren’t directly comparable”](#they-arent-directly-comparable)
It’s tempting to ask “does Queuert have a DLQ?” or “does pg-boss support transactional outbox?” and conclude one of them is missing features. That framing doesn’t fit:
* **Queue concepts** like DLQs, queue policies, named lanes, and rate limits are central to pg-boss because pg-boss is a queue. They are absent from Queuert because Queuert isn’t modeling messages-through-lanes — it’s modeling chains tied to data.
* **Chain concepts** like typed continuations, blocker DAGs, and transactional enqueue are central to Queuert because Queuert is a job-chain library. They are absent from pg-boss because pg-boss isn’t modeling chained execution — it’s modeling queues.
The narrow overlap is “both let you defer work into the background and persist it in Postgres so it survives crashes.” Beyond that, the shapes diverge.
## What pg-boss is good at
[Section titled “What pg-boss is good at”](#what-pg-boss-is-good-at)
* **Queue semantics out of the box.** Six policies (`standard`, `short`, `singleton`, `stately`, `exclusive`, `key_strict_fifo`) enforced at the schema level via partial unique indexes. “At most one active per key,” “strict FIFO per key with head-of-line blocking” — first-class, no application code.
* **Built-in cron scheduling.** `schedule(name, cron, data, { tz })` with timezone support, multiple schedules per queue.
* **Dead letter queues.** Set `deadLetter: 'dlq-name'` and final-failure jobs route there atomically.
* **Throttle / debounce primitives.** `sendThrottled` / `sendDebounced` with per-key time windows.
* **Built-in supervisor.** Cleanup, retention, and timeout detection run without you scheduling anything.
* **Maturity.** Seven years of deployment, widely used, well-documented.
These are what a *queue* should be good at, and pg-boss invests heavily in them.
## What Queuert is good at
[Section titled “What Queuert is good at”](#what-queuert-is-good-at)
* **Chained execution of typed jobs.** A chain is a typed sequence: `"send-email"` continues with `"log-sent"` continues with `"update-user-status"`. Each step’s input/output type is inferred from the previous step’s `continueWith`. Renames are compiler-checked.
* **Fan-in via blockers.** “Wait for these N independent chains to finish, then run X” is a typed primitive backed by a `job_blocker` table — not glue code.
* **Transactional consistency, by design.** `startChain` enqueues inside your DB transaction; handler completion + next-step `continueWith` commit in the same transaction as your domain writes. For DB-bound work, no outbox at enqueue and no idempotency-key ritual at processing — both halves are structural, not application discipline.
* **Sub-second wakeup latency.** `LISTEN/NOTIFY` (or Redis pub/sub, or NATS) wakes workers when a row commits — no polling-interval floor.
* **Pluggable transports.** State (Postgres / SQLite / in-process) and notify (LISTEN/NOTIFY / Redis / NATS / polling) are independent.
* **Database as the system of record.** Chain state lives in the same DB as your domain data. No separate store, no separate consistency model.
These are what a *job-chain library* should be good at, and Queuert is built around them.
## Differences worth knowing about
[Section titled “Differences worth knowing about”](#differences-worth-knowing-about)
A few practical differences are worth calling out — not as scorecard rows, but as things you’d hit operationally:
* **Wakeup mechanism.** pg-boss polls every `pollingIntervalSeconds` (default 2s); that’s the floor on enqueue→dequeue latency. Queuert listens on `LISTEN/NOTIFY` (or Redis / NATS), so workers wake when a row commits — typically tens of milliseconds.
* **Failure shape.** In pg-boss, final failure routes the job to a dead-letter queue (or its own `failed` set). In Queuert, failure stays as data on the chain (`last_attempt_error`); what happens next is an application decision. These are direct consequences of “queue” vs. “job-chain library.”
* **Storage backends.** pg-boss is Postgres-only. Queuert works against Postgres or SQLite (experimental), or an in-process adapter for tests / single-process apps.
## Transactional consistency, both ends
[Section titled “Transactional consistency, both ends”](#transactional-consistency-both-ends)
Both pg-boss and Queuert store state in your Postgres, so the question isn’t “is the state nearby?” — it’s “is the API wired to commit your domain write atomically with the queue’s state mutation?” pg-boss requires per-call discipline at one end and offers no equivalent at the other; Queuert is structural at both.
### Enqueue
[Section titled “Enqueue”](#enqueue)
pg-boss v12.17 (April 2026) added a `{ db }` option on `send` with bridge adapters for Knex / Kysely / Drizzle / Prisma to share the user’s transaction:
```ts
await prisma.$transaction(async (tx) => {
await prisma.user.create({ data: { ... } });
await boss.send("welcome-email", { ... }, { db: fromPrisma(tx) });
});
```
It works, but it’s per-call discipline: the adapter set is fixed (raw `pg` users have to write their own `IDatabase` shim), and most pg-boss code in the wild predates v12.17 and uses pg-boss’s own pool — meaning dual-write is the default unless every call site remembers to pass `{ db }`.
Queuert’s `startChain` writes into your DB transaction structurally — there is no enqueue path that bypasses it:
```ts
await withTransactionHooks(async (transactionHooks) =>
db.transaction(async (tx) => {
await tx.users.create({ ... });
await client.startChain({
tx,
transactionHooks,
typeName: "send-welcome-email",
input: { ... },
});
}),
);
```
### Processing
[Section titled “Processing”](#processing)
This is where the gap is sharper. pg-boss’s README markets *“Exactly-once job delivery”* — but that phrase refers specifically to `SKIP LOCKED` on the fetch path (two workers can’t claim the same row atomically). It does NOT mean handler-to-completion is exactly-once. Under `work()`, the handler runs, returns, and pg-boss then calls `complete()` against its own pool in a separate transaction (see [`src/manager.ts`](https://github.com/timgit/pg-boss/blob/master/src/manager.ts)). If your handler commits domain writes and the worker crashes before `complete()` lands (or the lease expires via `expireInSeconds`, default 15 min), the job is re-fetched and the handler runs again — domain writes commit twice.
v12.17 (April 2026) added `{ db }` on `complete()` (and `fetch()`, `fail()`, etc.), so the *primitives* for atomic completion exist — you can call `complete(jobId, output, { db: tx })` inside your domain transaction and the job’s state flips in the same commit. But the `work()` worker loop doesn’t surface them: to actually fuse “handler tx” with “completion tx,” you have to opt out of `work()`, write your own `fetch` + handler + `complete(..., { db: tx })` loop, and re-implement lease, retry, and backoff yourself. Atomic processing is possible, but it’s a parallel API you build — for code using the supported `work()` worker, idempotency at processing is application discipline.
Queuert’s complete callback runs inside the state adapter’s transaction. Your handler’s domain writes, the chain’s completion, and the next step’s `continueWith` all commit in one transaction:
```ts
"send-welcome-email": {
attemptHandler: async ({ job, complete }) =>
complete(async ({ sql, continueWith }) => {
await sql`insert into email_log (user_id) values (${job.input.userId})`;
return continueWith({ typeName: "log-sent", input: { ... } });
}),
},
```
If the worker crashes before the transaction commits, *nothing* lands — neither the domain write nor the chain progression. The next attempt starts fresh. At-least-once delivery becomes effectively exactly-once for DB-bound work.
### What still needs care
[Section titled “What still needs care”](#what-still-needs-care)
The precondition is that your application DB is the system of record for the data your handlers touch. *External* side effects (the email actually being sent, a Stripe charge) still need idempotency keys — Queuert structurally fixes the DB half of at-least-once, not the network half. Cross-DB writes (handler writing to a separate microservice’s database via API) still need an outbox at that boundary. For the chunk of your application where one Postgres is the source of truth, both outboxes go away.
## Choosing between them
[Section titled “Choosing between them”](#choosing-between-them)
The decision is mostly about which shape of tool fits your problem:
**Reach for pg-boss when:**
* Your problem is naturally queue-shaped: messages, lanes, routing, policies.
* You want first-class queue policies (singleton, exclusive, strict-FIFO) without building them yourself.
* You want cron, DLQ, and a maintenance supervisor in the box.
* Polling-interval wakeup latency is fine.
* You value seven years of production deployment over newer designs.
**Reach for Queuert when:**
* Your problem is naturally chain-shaped: typed multi-step sequences where this job continues with that job, possibly waiting on others.
* You want the work that follows a transaction to commit-or-rollback structurally with the data that triggered it.
* You want sub-second wakeup latency via `LISTEN/NOTIFY` (or Redis / NATS).
* Your DB is the system of record and you’d rather not introduce queue concepts you don’t need.
If both shapes plausibly fit, the deciding question is usually whether transactional enqueue and typed chains matter more than queue policies, or the other way around. Neither is a feature the other side can add cheaply — they’re consequences of what each tool fundamentally is.
# Temporal
> How Queuert relates to Temporal — different categories that overlap on multi-step durable work.
[Temporal](https://temporal.io) and Queuert both express multi-step durable work, but they’re different categories of tool. Temporal is a distributed workflow platform; Queuert is a job-chain library. Picking between them is mostly a question of how heavyweight a tool the problem actually warrants.
> Compared versions: Queuert `0.12.0` and the Temporal TypeScript SDK `1.17.1`.
## What Temporal is
[Section titled “What Temporal is”](#what-temporal-is)
Temporal is a **distributed durable-execution platform**. The mental model is workflow functions that run forever — deterministically, replayable from event history — execute side effects via separately-deployed Activities, and survive any crash by being replayed from their persistent history. Workflows can wait for hours or days, accept signals from outside, expose queries on their state, and spawn child workflows. Cross-language: official SDKs in Go, Java, Python, .NET, TypeScript, PHP, Ruby — all sharing the same server.
You operate (or rent via Temporal Cloud) a separate Temporal server cluster — frontend, matching, history, and worker services backed by Cassandra, MySQL, or Postgres. Your application contains an SDK that polls task queues over gRPC, executes workflow code in a sandbox VM, and runs activities directly.
## What Queuert is
[Section titled “What Queuert is”](#what-queuert-is)
Queuert is a **job-chain library** — durable, typed background work in your database. Job chains compose like Promise chains (`.then`, `Promise.all`), but they survive crashes and commit with your transactions.
The unit is a typed **chain** of jobs of (potentially different) types, where each job’s `continueWith` enqueues the next one in the same chain. Inputs, outputs, continuations, and blockers are inferred end-to-end via `defineJobTypes`. Chains start *inside* your DB transactions, so the work that follows a write commits-or-rolls-back with the data that triggered it.
No separate cluster. No deterministic replay. No event-history reconstruction. Just typed jobs in a couple of tables next to your domain data.
## Different tools — overlapping problem space
[Section titled “Different tools — overlapping problem space”](#different-tools--overlapping-problem-space)
Temporal and Queuert come from different starting points and end up at different shapes:
* **Temporal** is a workflow platform. It trades operational complexity (a server cluster, bundled workflow code, a determinism contract) for unbounded durability — workflows can `await sleep('30 days')` and survive arbitrary crashes / redeploys — plus rich runtime interaction (signals / queries / updates) and cross-language workflows.
* **Queuert** is a job-chain library. It trades those things away for “you just have a Postgres” — no cluster to operate, no determinism constraint, no separate durability tier — and wins back transactional enqueue and structural simplicity.
Both can express multi-step durable work that finishes in seconds-to-minutes. They diverge sharply outside that range: Temporal makes month-long sleeping workflows trivial; Queuert doesn’t try to.
## What Temporal is good at
[Section titled “What Temporal is good at”](#what-temporal-is-good-at)
* **In-line durable awaits.** A workflow function can `await sleep('30 days')` or `await condition(...)` literally inside its body and pick up where it left off — call stack restored — after a server restart, deploy, or region failover. Event-sourced replay makes this work. (Queuert can also span 30-day chains by scheduling the next step in the future; the difference is the programming model — “schedule the next step” vs. “await inside the same function.”)
* **Rich runtime interaction.** Signals (fire-and-forget messages into a running workflow), queries (synchronous read of state), updates (RPC-shaped mutations with return values) are first-class.
* **Cross-language workflows.** A workflow defined in Go can call activities written in TypeScript and Python — same server, same task queues.
* **Built-in scheduling and child workflows.** Server-managed cron schedules with overlap policies, child workflows with parent-close policies, continue-as-new for unbounded loops.
* **Battle-tested at scale.** Production-deployed at Stripe, Snap, Coinbase, and many others.
These are what a *distributed durable-execution platform* should be good at.
## What Queuert is good at
[Section titled “What Queuert is good at”](#what-queuert-is-good-at)
* **Chained execution of typed jobs.** Multi-step work as a typed sequence; inputs, outputs, continuations, and blockers infer end-to-end via `defineJobTypes`. Renames are compiler-checked.
* **Transactional consistency, by design.** `startChain` enqueues inside your DB transaction; handler completion + next-step `continueWith` commit in the same transaction as your domain writes. For DB-bound work, no outbox at enqueue and no idempotency-key ritual at processing — both halves are structural, not application discipline.
* **Plain TypeScript handlers.** No determinism constraint, no separate workflow bundle, no “you can’t call `Date.now()` here.” Job handlers are normal Node code that does normal Node things.
* **Operational simplicity.** No cluster to run, no separate persistence tier, no bundling step. Your application’s Postgres is the entire backing store.
* **Database as the system of record.** Chain state lives next to your domain data. Joins, foreign keys, transactional consistency — all available.
These are what a *job-chain library* should be good at.
## Differences worth knowing about
[Section titled “Differences worth knowing about”](#differences-worth-knowing-about)
A few practical differences:
* **Where state lives.** Temporal owns workflow state in its server cluster (Cassandra / MySQL / Postgres). Queuert keeps chain state in your application’s DB. This affects everything downstream — backups, observability, joins, transactions.
* **Transactional consistency.** Because Temporal state lives elsewhere, both ends require application discipline. *Enqueue:* starting a workflow is a gRPC call to the Temporal Service, not a DB transaction. Temporal staff describe the dual-write trap explicitly in [their own forum](https://community.temporal.io/t/what-is-recommended-approach-on-starting-workflow-in-transaction/16248): *“this pattern will start the workflow even if the database needs to abort and retry the database transaction, leaving you in an inconsistent state where the workflow has started but the database doesn’t know that happened.”* *Processing:* activities are at-least-once — Temporal’s [Activity Definition](https://docs.temporal.io/activity-definition) docs state *“You should always make your business logic Activities idempotent in Temporal. Because Activities may be retried, these functions may be executed more than once.”* The Temporal-blessed workaround is “workflow as the source of truth”: start the workflow first, then write to the DB from inside an activity. That’s a real architectural choice — it inverts the assumption many applications start from (that the DB is the system of record). With Queuert, both halves commit inside your DB transaction; the precondition is that your DB *is* the SoT for the data your handlers touch.
* **Determinism.** Temporal workflow code must be deterministic; you can’t call `Date.now()`, `Math.random()`, `fetch`, or use plain `setTimeout`. Replay relies on this. Queuert handlers are plain TypeScript with no such constraint.
* **Long durable waits.** Temporal can `await sleep('30 days')` and survive crashes / deploys. Queuert can schedule the next attempt for a future time, but doesn’t carry an awaiting call-stack across that wait.
* **Runtime interaction.** Temporal’s signals / queries / updates are first-class. Queuert exposes `triggerJob` and `completeChain` but doesn’t model an externally-interactive running process.
* **Versioning.** Bumping workflow code mid-flight in Temporal requires explicit `patched` / `getVersion` discipline. In Queuert, deploying new code doesn’t risk replay drift because there’s no replay.
* **Operational footprint.** Temporal: a multi-service cluster (frontend / matching / history / worker) plus Cassandra-class persistence, or pay for Temporal Cloud. Queuert: your existing Postgres.
## Choosing between them
[Section titled “Choosing between them”](#choosing-between-them)
The decision is about scale and shape:
**Reach for Temporal when:**
* You need long-lived workflows that survive arbitrary failures and run for days, weeks, or months.
* You need rich runtime interaction with running workflows — signals, queries, updates.
* You need cross-language workflows or activities (Go / Java / Python / .NET / TS / PHP / Ruby).
* The operational complexity of a separate cluster (or paying for Temporal Cloud) is acceptable.
* The determinism constraint and workflow bundling step are acceptable trade-offs for what you get.
**Reach for Queuert when:**
* Your work is chain-shaped and bounded — finishes in seconds-to-minutes per chain.
* You want transactional enqueue with your DB.
* You don’t want to operate (or pay for) a separate workflow cluster.
* Plain TypeScript handlers with no determinism contract are worth more than long-lived `await sleep('30d')`.
* Your DB is the system of record and you want chain state living next to your domain data.
Both can express multi-step durable work. The difference is whether you need a workflow platform with replay and signals, or a small library that fits in a few tables next to your data.
# Examples
> Browsable index of all Queuert examples with source links.
All examples are self-contained and runnable. Each one demonstrates a single integration or pattern.
Source: [`examples/`](https://github.com/kvet/queuert/tree/main/examples)
## State Adapters
[Section titled “State Adapters”](#state-adapters)
How to connect Queuert to your database using different ORMs and drivers.
### PostgreSQL
[Section titled “PostgreSQL”](#postgresql)
| Example | ORM / Driver |
| ------------------------------------------------------------------------------------------------------------- | ------------------------------------- |
| [state-postgres-kysely](https://github.com/kvet/queuert/tree/main/examples/state-postgres-kysely) | Kysely |
| [state-postgres-drizzle](https://github.com/kvet/queuert/tree/main/examples/state-postgres-drizzle) | Drizzle ORM |
| [state-postgres-prisma](https://github.com/kvet/queuert/tree/main/examples/state-postgres-prisma) | Prisma |
| [state-postgres-pg](https://github.com/kvet/queuert/tree/main/examples/state-postgres-pg) | pg (node-postgres) |
| [state-postgres-postgres-js](https://github.com/kvet/queuert/tree/main/examples/state-postgres-postgres-js) | postgres.js |
| [state-postgres-multi-worker](https://github.com/kvet/queuert/tree/main/examples/state-postgres-multi-worker) | Multiple workers sharing one database |
### SQLite
[Section titled “SQLite”](#sqlite)
| Example | ORM / Driver |
| ------------------------------------------------------------------------------------------------------------- | -------------- |
| [state-sqlite-node](https://github.com/kvet/queuert/tree/main/examples/state-sqlite-node) | node:sqlite |
| [state-sqlite-bun](https://github.com/kvet/queuert/tree/main/examples/state-sqlite-bun) | bun:sqlite |
| [state-sqlite-better-sqlite3](https://github.com/kvet/queuert/tree/main/examples/state-sqlite-better-sqlite3) | better-sqlite3 |
| [state-sqlite-kysely](https://github.com/kvet/queuert/tree/main/examples/state-sqlite-kysely) | Kysely |
| [state-sqlite-drizzle](https://github.com/kvet/queuert/tree/main/examples/state-sqlite-drizzle) | Drizzle ORM |
| [state-sqlite-prisma](https://github.com/kvet/queuert/tree/main/examples/state-sqlite-prisma) | Prisma |
## Notify Adapters
[Section titled “Notify Adapters”](#notify-adapters)
How to set up real-time job notifications between client and workers.
| Example | Transport |
| --------------------------------------------------------------------------------------------------------------------- | -------------------------------------- |
| [notify-redis-redis](https://github.com/kvet/queuert/tree/main/examples/notify-redis-redis) | Redis (node-redis) |
| [notify-redis-ioredis](https://github.com/kvet/queuert/tree/main/examples/notify-redis-ioredis) | Redis (ioredis) |
| [notify-redis-cluster-node-redis](https://github.com/kvet/queuert/tree/main/examples/notify-redis-cluster-node-redis) | Redis Cluster (node-redis) |
| [notify-redis-cluster-ioredis](https://github.com/kvet/queuert/tree/main/examples/notify-redis-cluster-ioredis) | Redis Cluster (ioredis) |
| [notify-nats-nats](https://github.com/kvet/queuert/tree/main/examples/notify-nats-nats) | NATS |
| [notify-postgres-pg](https://github.com/kvet/queuert/tree/main/examples/notify-postgres-pg) | PostgreSQL LISTEN/NOTIFY (pg) |
| [notify-postgres-postgres-js](https://github.com/kvet/queuert/tree/main/examples/notify-postgres-postgres-js) | PostgreSQL LISTEN/NOTIFY (postgres.js) |
## Patterns & Features
[Section titled “Patterns & Features”](#patterns--features)
Chain patterns, error handling, scheduling, and other core features.
| Example | What it demonstrates |
| ----------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------- |
| [showcase-chain-patterns](https://github.com/kvet/queuert/tree/main/examples/showcase-chain-patterns) | Linear, branched, looped, and go-to chain execution |
| [showcase-error-handling](https://github.com/kvet/queuert/tree/main/examples/showcase-error-handling) | Discriminated unions, compensation, rescheduling |
| [showcase-error-recovery](https://github.com/kvet/queuert/tree/main/examples/showcase-error-recovery) | Engine-level recovery: savepoints, post-complete errors, staged retries |
| [showcase-scheduling](https://github.com/kvet/queuert/tree/main/examples/showcase-scheduling) | Delayed and time-scheduled jobs |
| [showcase-blockers](https://github.com/kvet/queuert/tree/main/examples/showcase-blockers) | Cross-chain job dependencies |
| [showcase-chain-awaiting](https://github.com/kvet/queuert/tree/main/examples/showcase-chain-awaiting) | Awaiting chain completion programmatically |
| [showcase-chain-deletion](https://github.com/kvet/queuert/tree/main/examples/showcase-chain-deletion) | Deleting chains |
| [showcase-processing-modes](https://github.com/kvet/queuert/tree/main/examples/showcase-processing-modes) | Atomic vs staged processing modes |
| [showcase-queries](https://github.com/kvet/queuert/tree/main/examples/showcase-queries) | Querying jobs and chains |
| [showcase-timeouts](https://github.com/kvet/queuert/tree/main/examples/showcase-timeouts) | Job and chain timeouts |
| [showcase-slices](https://github.com/kvet/queuert/tree/main/examples/showcase-slices) | Feature slices with merged job types and processors |
| [showcase-cleanup](https://github.com/kvet/queuert/tree/main/examples/showcase-cleanup) | Automatic cleanup of completed chains |
| [showcase-workerless](https://github.com/kvet/queuert/tree/main/examples/showcase-workerless) | Running without a worker (polling only) |
| [showcase-multiworker-prioritization](https://github.com/kvet/queuert/tree/main/examples/showcase-multiworker-prioritization) | Priority tiers via specialized workers; cross-worker chain handoff |
| [showcase-middleware](https://github.com/kvet/queuert/tree/main/examples/showcase-middleware) | Attempt middleware: wrapHandler, wrapPrepare, wrapComplete with typed ctx |
## Logging
[Section titled “Logging”](#logging)
| Example | Logger |
| ----------------------------------------------------------------------------- | ----------------------- |
| [log-console](https://github.com/kvet/queuert/tree/main/examples/log-console) | Built-in console logger |
| [log-pino](https://github.com/kvet/queuert/tree/main/examples/log-pino) | Pino |
| [log-winston](https://github.com/kvet/queuert/tree/main/examples/log-winston) | Winston |
## Validation
[Section titled “Validation”](#validation)
Input/output validation with different schema libraries.
| Example | Library |
| ------------------------------------------------------------------------------------------- | ------- |
| [validation-zod](https://github.com/kvet/queuert/tree/main/examples/validation-zod) | Zod |
| [validation-arktype](https://github.com/kvet/queuert/tree/main/examples/validation-arktype) | ArkType |
| [validation-valibot](https://github.com/kvet/queuert/tree/main/examples/validation-valibot) | Valibot |
| [validation-typebox](https://github.com/kvet/queuert/tree/main/examples/validation-typebox) | TypeBox |
## Observability & Dashboard
[Section titled “Observability & Dashboard”](#observability--dashboard)
| Example | What it demonstrates |
| ------------------------------------------------------------------------------------------- | --------------------------------- |
| [observability-otel](https://github.com/kvet/queuert/tree/main/examples/observability-otel) | OpenTelemetry tracing and metrics |
| [dashboard](https://github.com/kvet/queuert/tree/main/examples/dashboard) | Web dashboard UI with SQLite |
# Core Concepts
> Jobs, chains, types, adapters, and workers.
### Job
[Section titled “Job”](#job)
An individual unit of work. Jobs have a lifecycle: `blocked` → `pending` → `running` → `completed`. Each job belongs to a Job Type and contains typed input/output. Jobs start as `blocked` when they depend on other chains (see [Job Blockers](/queuert/guides/job-blockers/)); otherwise they start as `pending`.
### Chain
[Section titled “Chain”](#chain)
A chain of linked jobs where each job can `continueWith` to the next - just like a Promise chain. In fact, a chain IS its first job, the same way a Promise chain IS the first promise. When you call `startChain`, the returned `chain.id` is the first job’s ID. Continuation jobs share this `chainId` but have their own unique `id`. The chain completes when its final job completes without continuing.
### Job Type
[Section titled “Job Type”](#job-type)
Defines a named job type with its input/output types and attempt handler function. Job types are registered with workers. The attempt handler receives the job and context for completing or continuing the chain.
### State Adapter
[Section titled “State Adapter”](#state-adapter)
Abstracts database operations for job persistence. Queuert provides adapters for PostgreSQL and SQLite. The adapter handles job creation, status transitions, leasing, and queries.
**Available adapters:**
* `@queuert/postgres` - PostgreSQL state adapter (recommended for production)
* `@queuert/sqlite` - SQLite state adapter *(experimental)*
Tip
See [State Adapters](/queuert/integrations/state-adapters/) for supported ORMs, drivers, and configuration details.
### State Provider
[Section titled “State Provider”](#state-provider)
Bridges your database client (Kysely, Drizzle, Prisma, raw pg, etc.) with the state adapter. You implement a simple interface that provides transaction handling and SQL execution. See [Adapter Architecture](/queuert/advanced/adapters/).
### Notify Adapter
[Section titled “Notify Adapter”](#notify-adapter)
Handles pub/sub notifications for efficient job scheduling. When a job is created, workers are notified immediately instead of polling. This reduces latency from seconds to milliseconds.
**Available adapters:**
* `@queuert/redis` - Redis notify adapter (recommended for production)
* `@queuert/nats` - NATS notify adapter *(experimental)*
* `@queuert/postgres` - PostgreSQL notify adapter (uses LISTEN/NOTIFY, no additional infrastructure)
* None (default) - polling only, no real-time notifications
Tip
See [Notify Adapters](/queuert/integrations/notify-adapters/) for supported clients and configuration details.
### Notify Provider
[Section titled “Notify Provider”](#notify-provider)
Bridges your pub/sub client (Redis, PostgreSQL, etc.) with the notify adapter. Similar to state providers, you implement an interface for publishing messages and subscribing to channels. See [Adapter Architecture](/queuert/advanced/adapters/).
### Worker
[Section titled “Worker”](#worker)
Processes jobs by polling for available work. Workers automatically renew leases during long-running operations and handle retries with configurable backoff. See [In-Process Worker](/queuert/advanced/in-process-worker/) and [Job Processing](/queuert/advanced/job-processing/).
### Logging
[Section titled “Logging”](#logging)
By default, Queuert operates silently. Enable logging with `createConsoleLog()` for development, or implement a custom `Log` function for production (Pino, Winston, etc.). See the [log-console](https://github.com/kvet/queuert/tree/main/examples/log-console), [log-pino](https://github.com/kvet/queuert/tree/main/examples/log-pino), and [log-winston](https://github.com/kvet/queuert/tree/main/examples/log-winston) examples.
## What’s next?
[Section titled “What’s next?”](#whats-next)
Now that you understand the building blocks, follow the guides in order:
1. **[Transaction Hooks](/queuert/guides/transaction-hooks/)** — How jobs are created inside database transactions (required for all usage)
2. **[Job Processing Modes](/queuert/guides/processing-modes/)** — Atomic vs staged processing and the prepare/complete pattern
3. **[Chain Patterns](/queuert/guides/chain-patterns/)** — Linear chains, branching, loops, and go-to patterns
For setting up your database and infrastructure, see [Integrations](/queuert/integrations/state-adapters/).
# Installation
> Install Queuert and its adapters.
## Requirements
[Section titled “Requirements”](#requirements)
* Node.js 22 or later
* TypeScript 5.0+ (recommended)
## Installation
[Section titled “Installation”](#installation)
1. Install the core package:
* npm
```bash
npm install queuert
```
* pnpm
```bash
pnpm add queuert
```
* yarn
```bash
yarn add queuert
```
2. Install a state adapter (pick one):
* PostgreSQL
Recommended for production. Supports horizontal scaling and all Queuert features. Requires PostgreSQL 14+.
* npm
```bash
npm install @queuert/postgres
```
* pnpm
```bash
pnpm add @queuert/postgres
```
* yarn
```bash
yarn add @queuert/postgres
```
* SQLite
```bash
npm install @queuert/postgres
```
* npm
```bash
pnpm add @queuert/postgres
```
* pnpm
```bash
yarn add @queuert/postgres
```
* yarn
Experimental Suitable for local development, CLI tools, and embedded applications. Requires SQLite 3.42+.
* npm
```bash
npm install @queuert/sqlite
```
* pnpm
```bash
pnpm add @queuert/sqlite
```
* yarn
```bash
yarn add @queuert/sqlite
```
* npm
```bash
npm install @queuert/sqlite
```
* pnpm
```bash
pnpm add @queuert/sqlite
```
* yarn
```bash
yarn add @queuert/sqlite
```
3. (Optional) Install a notify adapter for reduced latency:
* Redis
Recommended for production. Uses Redis pub/sub with hint-based optimization to prevent thundering herd. Requires Redis 6+.
* npm
```bash
npm install @queuert/redis
```
* pnpm
```bash
pnpm add @queuert/redis
```
* yarn
```bash
yarn add @queuert/redis
```
* NATS
```bash
npm install @queuert/redis
```
* PostgreSQL LISTEN/NOTIFY
```bash
pnpm add @queuert/redis
```
* None (polling)
```bash
yarn add @queuert/redis
```
* npm
Experimental Uses NATS pub/sub. Supports revision-based CAS optimization when JetStream KV is available. Requires NATS 2.2+ (2.6+ for JetStream KV).
* npm
```bash
npm install @queuert/nats
```
* pnpm
```bash
pnpm add @queuert/nats
```
* yarn
```bash
yarn add @queuert/nats
```
* pnpm
```bash
npm install @queuert/nats
```
* yarn
```bash
pnpm add @queuert/nats
```
* npm
```bash
yarn add @queuert/nats
```
* pnpm
Uses PostgreSQL’s built-in `LISTEN`/`NOTIFY`. No additional infrastructure beyond your existing PostgreSQL database — already included in `@queuert/postgres`.
* npm
```bash
npm install @queuert/postgres
```
* pnpm
```bash
pnpm add @queuert/postgres
```
* yarn
```bash
yarn add @queuert/postgres
```
* yarn
```bash
npm install @queuert/postgres
```
* npm
```bash
pnpm add @queuert/postgres
```
* pnpm
```bash
yarn add @queuert/postgres
```
* yarn
Workers poll the database on a configurable interval. No extra packages or infrastructure required. Suitable for low-throughput workloads where millisecond latency is not critical.
4. (Optional) Install additional packages:
* npm
```bash
npm install @queuert/dashboard # Embeddable web UI for job observation
npm install @queuert/otel # OpenTelemetry metrics and tracing
```
* pnpm
```bash
pnpm add @queuert/dashboard # Embeddable web UI for job observation
pnpm add @queuert/otel # OpenTelemetry metrics and tracing
```
* yarn
```bash
yarn add @queuert/dashboard # Embeddable web UI for job observation
yarn add @queuert/otel # OpenTelemetry metrics and tracing
```
For detailed adapter configuration (ORM setup, driver options, provider interfaces), see the [Integrations](/queuert/integrations/state-adapters/) section.
Next up: **[Core Concepts](/queuert/getting-started/core-concepts/)** — learn the building blocks before diving into guides.
# Introduction
> What Queuert is and why it exists.
## What is Queuert
[Section titled “What is Queuert”](#what-is-queuert)
Queuert is a **job-chain library** — durable, typed background work in your database. Job chains compose like Promise chains (`.then`, `Promise.all`), but they survive crashes and commit with your transactions.
The unit of work is a typed **chain** of jobs of (potentially different) types. Each step’s input, output, and continuation are inferred end-to-end via `defineJobTypes`. Chains start *inside* your DB transactions, so the work that follows a write commits-or-rolls-back with the data that triggered it.
Queuert sits between job queues and workflow engines. A one-job chain *is* a queue. A multi-step chain with blockers is closer to a workflow. Neither label fully fits — which is why the canonical term is “job-chain library.”
## A look at the API
[Section titled “A look at the API”](#a-look-at-the-api)
Define a typed chain. Each step declares its input, output, and which type it continues with.
```ts
const jobTypes = defineJobTypes<{
"provision-account": {
entry: true;
input: { userId: number };
continueWith: { typeName: "send-welcome-email" };
};
"send-welcome-email": {
input: { userId: number; accountId: string };
continueWith: { typeName: "sync-to-crm" };
};
"sync-to-crm": {
input: { userId: number; accountId: string };
};
}>();
```
Start the chain *inside* your application’s DB transaction. If the transaction rolls back (because, say, user creation fails a constraint check), the chain is never created. There’s no separate queue to keep in sync — your DB transaction is the boundary. (See [transactional outbox pattern](https://microservices.io/patterns/data/transactional-outbox.html).)
```ts
const client = await createClient({ stateAdapter, jobTypes });
await withTransactionHooks(async (transactionHooks) =>
db.transaction(async (tx) => {
const user = await tx.users.create({ name: "Alice", email: "alice@example.com" });
await client.startChain({
tx,
transactionHooks,
typeName: "provision-account",
input: { userId: user.id },
// ↑ wrong shape here is a compile error
});
}),
);
```
A worker picks up each step and continues to the next. The compiler enforces that `continueWith` matches the declared next type’s input.
```ts
const worker = await createInProcessWorker({
client,
processors: createProcessors({
client,
jobTypes,
processors: {
"provision-account": {
attemptHandler: async ({ job, complete }) => {
const accountId = await provisionAccount(job.input.userId);
return complete(async ({ continueWith }) =>
continueWith({
typeName: "send-welcome-email",
input: { userId: job.input.userId, accountId },
// ↑ missing accountId would be a compile error
}),
);
},
},
// ...handlers for "send-welcome-email" and "sync-to-crm"
},
}),
});
const stop = await worker.start();
```
## Where it fits
[Section titled “Where it fits”](#where-it-fits)
Background-work libraries split across two axes: the *shape* of work they model and where the *state* lives.
* **Job queues** (BullMQ, pg-boss) model messages routed through named lanes with policies. Good fit for “I have many independent jobs to run.”
* **Workflow platforms** (Temporal, Inngest) model long-lived processes with rich runtime interaction (signals, queries, durable sleeps). Good fit for “I have multi-step processes that run for hours/days/weeks and need to survive arbitrary failures.”
* **Queuert** is a third thing: a job-chain library. Chains can be a single job (queue-shaped) or a multi-step typed sequence with fan-in (workflow-shaped) — both are first-class. Good fit for “I have background work that should commit with my domain writes and finish in seconds-to-minutes.”
For one-on-one comparisons see the [comparison docs](/queuert/comparison/).
## Why pick Queuert
[Section titled “Why pick Queuert”](#why-pick-queuert)
* **Transactional, both ends.** Enqueue commits inside your DB transaction; handler completion + next-step `continueWith` commit in the same transaction as your domain writes. For DB-bound work, no outbox at enqueue and no idempotency-key ritual at processing — both halves are structural.
* **Typed job chains.** Inputs, outputs, continuations, and blockers infer end-to-end via `defineJobTypes`. Renames and refactors are compiler-checked.
* **Lives in your database.** Postgres or SQLite. No Redis required, no workflow server, no separate persistence tier to operate.
* **Sub-second wakeup latency.** `LISTEN/NOTIFY` (or Redis pub/sub, or NATS) wakes workers when a row commits — not on a polling timer.
* **Fan-in via blockers.** “Wait for these N independent chains to finish, then run X” is a typed primitive backed by a `job_blocker` table.
* **Schedule for later.** Delay a chain to a specific time or duration. Schedule retries with backoff. Future work, no extra infrastructure.
* **Deduplication.** Pass a deduplication key on enqueue. Identical keys collapse to a single chain — at-most-once, by construction.
* **MIT licensed.** No enterprise tier, no vendor lock-in.
# Awaiting Chains
> Wait for chains to complete with polling and notifications.
`awaitChain` waits for a chain to complete by combining polling with notify adapter events. Between polls, it listens for completion notifications to react immediately.
```ts
const completedChain = await client.awaitChain(
{ id: chainId },
{ timeoutMs: 30_000, pollIntervalMs: 5_000 },
);
console.log(completedChain.output); // Typed output from the final job
```
Throws `WaitChainTimeoutError` on timeout. Supports an `AbortSignal` for cancellation.

See [examples/showcase-chain-awaiting](https://github.com/kvet/queuert/tree/main/examples/showcase-chain-awaiting) for a complete working example demonstrating basic awaiting, parallel awaiting, timeout handling, and abort signals.
# Chain Deletion
> Delete chains with blocker safety and cascade support.
Chains can be deleted using `deleteChains` (plural) or `deleteChain` (singular). All jobs in the chain (entry job and continuations) are removed together.
```ts
await withTransactionHooks(async (transactionHooks) =>
client.deleteChains({
transactionHooks,
ids: [chain.id],
}),
);
```
Use `deleteChain` to target a single chain — it returns the deleted chain or `undefined` if no chain with that ID exists. `deleteChains` silently skips missing IDs and returns the chains that were actually deleted. Both calls are idempotent:
```ts
await withTransactionHooks(async (transactionHooks) =>
client.deleteChain({
transactionHooks,
id: chain.id,
}),
);
```
If a chain is referenced as a blocker by another chain, deletion is rejected unless both chains are deleted together:
```ts
await withTransactionHooks(async (transactionHooks) =>
client.deleteChains({ transactionHooks, ids: [blockerChain.id] }),
); // throws
await withTransactionHooks(async (transactionHooks) =>
client.deleteChains({ transactionHooks, ids: [mainChain.id, blockerChain.id] }),
); // ok
```
## Cascade Deletion
[Section titled “Cascade Deletion”](#cascade-deletion)
Use `cascade: true` to automatically resolve and delete transitive dependencies (blockers) without enumerating them manually:
```ts
await withTransactionHooks(async (transactionHooks) =>
client.deleteChains({
transactionHooks,
ids: [mainChain.id],
cascade: true,
}),
);
```
Cascade follows dependencies downward — it deletes the specified chains and everything they depend on. If any chain in the resolved set is still referenced by an external chain, deletion is rejected with `BlockerReferenceError`.
If a worker is currently processing a job in a deleted chain, the worker’s `signal` is aborted with reason `"not_found"`, allowing graceful cleanup.
See [examples/showcase-chain-deletion](https://github.com/kvet/queuert/tree/main/examples/showcase-chain-deletion) for a complete working example demonstrating simple deletion, blocker safety, co-deletion, and cascade deletion. See also [Transaction Hooks](../transaction-hooks/) and [Job Blockers](../job-blockers/).
## How It Works
[Section titled “How It Works”](#how-it-works)
### What Gets Deleted
[Section titled “What Gets Deleted”](#what-gets-deleted)
Given a list of `ids`, the operation deletes all jobs in each chain (every job where `job.chainId` matches a provided ID, including root and continuations) and cleans up blocker references pointing at deleted chains from surviving jobs.
### Blocker Safety Check
[Section titled “Blocker Safety Check”](#blocker-safety-check)
Before deleting, the system checks whether any external chain depends on the target chains as blockers. “External” means the dependent job’s own chain is not in the deletion set. This prevents orphaning blocked chains that would never unblock.
```plaintext
Chain A (blocker) --> Chain B (blocked)
deleteChains({ ids: [A] }) // BlockerReferenceError -- B depends on A
deleteChains({ ids: [A, B] }) // Both in deletion set -- no external refs
```
### Cascade Resolution Algorithm
[Section titled “Cascade Resolution Algorithm”](#cascade-resolution-algorithm)
Chains form a DAG through blocker relationships. Cascade delete starting from a chain follows dependencies downward to include all transitive blockers:
```plaintext
Main --depends on--+-- Blocker X
|
+-- Blocker Y --depends on-- Blocker Z
```
Cascade delete starting from `Main` resolves to: `Main`, `Blocker X`, `Blocker Y`, and `Blocker Z`. The traversal direction is downward only — from a chain to its blockers, recursively. The blocker safety check still applies to the expanded set: if any chain in the resolved set is referenced by an external chain, the operation throws `BlockerReferenceError`.
Blocker graphs are DAGs by construction (blockers must exist at chain creation time), so cycles are impossible. Running jobs in the resolved set are handled by the existing lease-renewal signal mechanism.
# Chain Patterns
> Linear, branched, loop, and go-to patterns.
Chains support various execution patterns via `continueWith`:
* [Linear](#linear) — `continueWith` returns the next type
* [Branched](#branched) — `continueWith` returns one of a union of types
* [Loop](#loop) — `continueWith` returns the same type until a terminal output
* [Go-to](#go-to) — `continueWith` jumps to a different type, skipping intermediates
## Linear
[Section titled “Linear”](#linear)

Jobs execute one after another: `create-subscription -> activate-trial`
```ts
const jobTypes = defineJobTypes<{
'create-subscription': {
entry: true;
input: { userId: string; planId: string };
continueWith: { typeName: 'activate-trial' };
};
'activate-trial': {
input: { subscriptionId: number; trialDays: number };
continueWith: { typeName: 'trial-decision' };
};
}>();
// In processor
'create-subscription': {
attemptHandler: async ({ job, complete }) => {
return complete(async ({ sql, continueWith }) => {
const [sub] = await sql`INSERT INTO subscriptions ... RETURNING id`;
return continueWith({
typeName: "activate-trial",
input: { subscriptionId: sub.id, trialDays: 7 },
});
});
},
},
```
## Branched
[Section titled “Branched”](#branched)

Jobs conditionally continue to different types: `trial-decision -> convert-to-paid | expire-trial`
```ts
'trial-decision': {
input: { subscriptionId: number };
continueWith: { typeName: 'convert-to-paid' | 'expire-trial' }; // Union type
};
// In processor - choose path based on condition
'trial-decision': {
attemptHandler: async ({ job, complete }) => {
const shouldConvert = userWantsToConvert;
return complete(async ({ continueWith }) => {
return continueWith({
typeName: shouldConvert ? "convert-to-paid" : "expire-trial",
input: { subscriptionId: job.input.subscriptionId },
});
});
},
},
```
## Loops
[Section titled “Loops”](#loops)

Jobs continue to the same type: `charge-billing -> charge-billing -> ... -> done`
```ts
const jobTypes = defineJobTypes<{
'charge-billing': {
input: { subscriptionId: number; cycle: number };
output: { finalCycle: number; totalCharged: number }; // Terminal output
continueWith: { typeName: 'charge-billing' }; // Self-reference for looping
};
}>();
// In processor - loop or terminate with output
'charge-billing': {
attemptHandler: async ({ job, complete }) => {
await chargePayment(job.input.subscriptionId);
return complete(async ({ continueWith }) => {
if (job.input.cycle < MAX_CYCLES) {
return continueWith({
typeName: "charge-billing",
input: { subscriptionId: job.input.subscriptionId, cycle: job.input.cycle + 1 },
});
}
return { finalCycle: job.input.cycle, totalCharged: calculateTotal() };
});
},
},
```
## Go-to
[Section titled “Go-to”](#go-to)

Jobs jump to a different type mid-chain: `charge-billing -> cancel-subscription`
```ts
const jobTypes = defineJobTypes<{
'charge-billing': {
input: { subscriptionId: number; cycle: number };
output: { finalCycle: number; totalCharged: number };
continueWith: { typeName: 'charge-billing' | 'cancel-subscription' }; // Loop or jump
};
'cancel-subscription': {
input: { subscriptionId: number; reason: string };
output: { cancelledAt: string };
};
}>();
// In processor - jump to cancel when max cycles reached
'charge-billing': {
attemptHandler: async ({ job, complete }) => {
return complete(async ({ continueWith }) => {
if (job.input.cycle >= MAX_CYCLES) {
return continueWith({
typeName: "cancel-subscription",
input: { subscriptionId: job.input.subscriptionId, reason: "max_billing_cycles_reached" },
});
}
return continueWith({
typeName: "charge-billing",
input: { subscriptionId: job.input.subscriptionId, cycle: job.input.cycle + 1 },
});
});
},
},
```
## Continuation References
[Section titled “Continuation References”](#continuation-references)
All examples above use **nominal references** — `{ typeName: "..." }`. Queuert also supports **structural references** (`{ input: {...} }`) that match any job type with a compatible input shape, enabling loose coupling. See [Job Type References](/queuert/advanced/job-type-references/) for details and examples.
See [examples/showcase-chain-patterns](https://github.com/kvet/queuert/tree/main/examples/showcase-chain-patterns) for a complete working example demonstrating all four patterns through a subscription lifecycle workflow. See also [Job Blockers](../job-blockers/) for parallel dependencies and [Chain Model](/queuert/advanced/chain-model/) reference.
# Cleanup
> How to implement automatic cleanup of completed chains.
## Overview
[Section titled “Overview”](#overview)
Without cleanup, the job table grows unboundedly as completed chains accumulate. This guide shows how to implement cleanup as a regular Queuert job — listing completed chains older than a cutoff date, deleting them in batches using cursor pagination, reclaiming disk space with vacuum, and scheduling the next run.
## Define a Cleanup Job Type
[Section titled “Define a Cleanup Job Type”](#define-a-cleanup-job-type)
```ts
const cleanupJobTypes = defineJobTypes<{
"queuert.cleanup": {
entry: true;
input: null;
output: null;
};
}>();
```
## Write the Processor
[Section titled “Write the Processor”](#write-the-processor)
```ts
const CLEANUP_RETENTION_MS = 7 * 24 * 60 * 60 * 1000; // 7 days
const CLEANUP_BATCH_SIZE = 100;
const CLEANUP_INTERVAL_MS = 60 * 60 * 1000; // 1 hour
const cleanupProcessorRegistry = createProcessors({
client,
jobTypes: cleanupJobTypes,
processors: {
"queuert.cleanup": {
attemptHandler: async ({ job, complete }) => {
const cutoffDate = new Date(Date.now() - CLEANUP_RETENTION_MS);
let deletedChainCount = 0;
let cursor: string | undefined;
do {
const page = await client.listChains({
filter: { root: true, to: cutoffDate },
orderDirection: "asc",
limit: CLEANUP_BATCH_SIZE,
...(cursor != null ? { cursor } : {}),
});
const chainsToDelete = page.items.filter(
(chain) => chain.id !== job.chainId && chain.status === "completed",
);
if (chainsToDelete.length > 0) {
const deleted = await withTransactionHooks(async (transactionHooks) =>
stateProvider.withTransaction(async (txCtx) =>
client.deleteChains({
...txCtx,
transactionHooks,
ids: chainsToDelete.map((chain) => chain.id),
}),
),
);
deletedChainCount += deleted.length;
}
cursor = page.nextCursor ?? undefined;
} while (cursor);
await stateAdapter.vacuum();
return complete(async ({ transactionHooks, ...txCtx }) => {
await client.startChain({
...txCtx,
transactionHooks,
typeName: "queuert.cleanup",
input: null,
schedule: { afterMs: CLEANUP_INTERVAL_MS },
deduplication: {
key: "queuert.cleanup",
scope: "incomplete",
excludeChainIds: [job.chainId],
},
});
return null;
});
},
},
},
});
```
Key patterns used:
* **Retention cutoff** — `CLEANUP_RETENTION_MS` controls how long completed chains are kept before deletion
* **Self-exclusion filter** — the cleanup chain filters itself out of the deletion list to avoid deleting its own chain
* **Cursor pagination** — processes chains in bounded batches using `listChains` cursor, preventing unbounded memory usage
* **Vacuum** — reclaims disk space after all deletions complete
* **`deduplication`** with `scope: "incomplete"` — ensures only one cleanup chain is active at a time
* **`excludeChainIds`** — prevents the finishing cleanup chain from deduplicating against itself
* **`schedule`** — defers the next run by `CLEANUP_INTERVAL_MS`
## Merge and Start
[Section titled “Merge and Start”](#merge-and-start)
Compose the cleanup slice with your application slices by passing arrays to `createClient` and `createInProcessWorker`:
```ts
const client = await createClient({
stateAdapter,
notifyAdapter,
jobTypes: [cleanupJobTypes, yourJobTypes],
});
const worker = await createInProcessWorker({
client,
processors: [cleanupProcessorRegistry, yourProcessorRegistry],
});
```
## Schedule the First Run
[Section titled “Schedule the First Run”](#schedule-the-first-run)
Schedule the initial cleanup at application startup. Deduplication makes this idempotent — calling it multiple times returns the same chain:
```ts
await withTransactionHooks(async (transactionHooks) =>
stateProvider.withTransaction(async (txCtx) =>
client.startChain({
...txCtx,
transactionHooks,
typeName: "queuert.cleanup",
input: null,
deduplication: { key: "queuert.cleanup", scope: "incomplete" },
}),
),
);
```
After the first run completes, the cleanup job automatically schedules its next run.
## Reclaiming Disk Space
[Section titled “Reclaiming Disk Space”](#reclaiming-disk-space)
The cleanup job calls `stateAdapter.vacuum()` after all batches are deleted, reclaiming disk space as part of the cleanup run.
### PostgreSQL
[Section titled “PostgreSQL”](#postgresql)
The adapter configures aggressive autovacuum on the job tables (2% dead-tuple threshold, no I/O throttle) and sets `fillfactor = 75` on the job table to enable HOT updates. PostgreSQL’s autovacuum handles most space reclamation automatically, but the explicit vacuum step ensures timely cleanup after large deletions. See [PostgreSQL Internals](/queuert/advanced/postgres-internals/#vacuum-tuning) for details.
### SQLite
[Section titled “SQLite”](#sqlite)
SQLite does not reclaim space automatically. The vacuum step frees reclaimable pages via incremental vacuum. This requires `PRAGMA auto_vacuum = INCREMENTAL` to be set on the database before table creation. See [SQLite Internals](/queuert/advanced/sqlite-internals/#vacuum) for details.
## Customization Ideas
[Section titled “Customization Ideas”](#customization-ideas)
Since this is your own job type, you can adapt the logic freely:
* **Per-type retention** — filter by `typeName` and apply different cutoff dates
* **Archive instead of delete** — copy chain data to an archive table before deleting
* **Metrics** — emit the `deletedChainCount` to your observability system
* **Alerting** — fail the cleanup job if deletion count exceeds a threshold
See [examples/showcase-cleanup](https://github.com/kvet/queuert/tree/main/examples/showcase-cleanup) for a complete working example demonstrating automatic cleanup of completed chains.
## See Also
[Section titled “See Also”](#see-also)
* [Scheduling](/queuert/guides/scheduling/) — Deferred start and recurring job patterns
* [Chain Deletion](/queuert/guides/chain-deletion/) — Manual chain deletion and blocker safety
* [Slices](/queuert/guides/slices/) — Merging job type and processor registries
# Deduplication
> Prevent duplicate chains with deduplication keys.
Deduplication prevents duplicate chains from being created. When you start a chain with a deduplication key, Queuert checks if a chain with that key already exists and returns the existing chain instead of creating a new one.

```ts
// First call creates the chain
const chain1 = await withTransactionHooks(async (transactionHooks) =>
client.startChain({
transactionHooks,
typeName: "sync-user",
input: { userId: "123" },
deduplication: { key: "sync:user:123" },
}),
);
// Second call with same key returns existing chain
const chain2 = await withTransactionHooks(async (transactionHooks) =>
client.startChain({
transactionHooks,
typeName: "sync-user",
input: { userId: "123" },
deduplication: { key: "sync:user:123" },
}),
);
chain2.deduplicated; // true — returned existing chain
chain2.id === chain1.id; // true
```
## Deduplication Modes
[Section titled “Deduplication Modes”](#deduplication-modes)
The `scope` option controls what jobs to check for duplicates:
* **`incomplete`** (default) — Only dedup against incomplete chains (allows new chain after previous completes)
* **`any`** — Dedup against any existing chain with this key
```ts
// Only one active health check at a time, but can start new after completion
await withTransactionHooks(async (transactionHooks) =>
client.startChain({
transactionHooks,
typeName: "health-check",
input: { serviceId: "api-server" },
deduplication: {
key: "health:api-server",
scope: "incomplete",
},
}),
);
```
## Time-Windowed Deduplication
[Section titled “Time-Windowed Deduplication”](#time-windowed-deduplication)
Use `windowMs` to rate-limit job creation. Duplicates are prevented only within the time window.
```ts
// No duplicate syncs within 1 hour
await withTransactionHooks(async (transactionHooks) =>
client.startChain({
transactionHooks,
typeName: "sync-data",
input: { sourceId: "db-primary" },
deduplication: {
key: "sync:db-primary",
scope: "any",
windowMs: 60 * 60 * 1000, // 1 hour
},
}),
);
```
## Excluding Chains
[Section titled “Excluding Chains”](#excluding-chains)
Use `excludeChainIds` to skip specific chains during deduplication matching. This is essential for recurring jobs that self-schedule within a completion callback — the current chain is still incomplete at that point, so without exclusion the new chain would be deduplicated against it.
```ts
// Inside a processor's completion callback
return complete(async ({ sql, transactionHooks }) => {
await client.startChain({
sql,
transactionHooks,
typeName: "health-check",
input: { serviceId: job.input.serviceId },
schedule: { afterMs: 5 * 60 * 1000 },
deduplication: {
key: `health:${job.input.serviceId}`,
excludeChainIds: [job.chainId],
},
});
return { checkedAt: new Date().toISOString() };
});
```
See [examples/showcase-scheduling](https://github.com/kvet/queuert/tree/main/examples/showcase-scheduling) for a complete working example demonstrating deduplication with recurring jobs. See also [Scheduling](../scheduling/) and [Transaction Hooks](../transaction-hooks/).
# Error Handling
> Discriminated unions, compensation patterns, and rescheduling.
Queuert provides only job completion — there is no built-in “failure” state. This is intentional: you control how errors are represented in your job outputs.
## Discriminated Union
[Section titled “Discriminated Union”](#discriminated-union)
Return error information in your output type. The caller inspects the output to determine success or failure.
```ts
const jobTypes = defineJobTypes<{
"process-payment": {
entry: true;
input: { orderId: string };
output: { success: true; transactionId: string } | { success: false; error: string };
};
}>();
```
Tip
This is the simplest approach and works well for most jobs. Prefer it when the caller needs to react to the outcome, or when you want the error to be part of the chain’s permanent record.
## Compensation
[Section titled “Compensation”](#compensation)
For workflows that need rollback, continue to a compensation job that undoes previous steps.

```ts
const jobTypes = defineJobTypes<{
"charge-card": {
entry: true;
input: { orderId: string };
continueWith: { typeName: "ship-order" | "refund-charge" };
};
"ship-order": {
input: { orderId: string; chargeId: string };
output: { shipped: true };
continueWith: { typeName: "refund-charge" }; // Can continue to refund on failure
};
"refund-charge": {
input: { chargeId: string };
output: { refunded: true };
};
}>();
```
## Rescheduling
[Section titled “Rescheduling”](#rescheduling)
When a job throws an error, it’s automatically rescheduled with exponential backoff. For transient failures where you want explicit control over retry timing, use `rescheduleJob`:
```ts
import { rescheduleJob } from "queuert";
const worker = await createInProcessWorker({
client,
processors: createProcessors({
client,
jobTypes,
processors: {
"call-external-api": {
attemptHandler: async ({ job, prepare, complete }) => {
const response = await fetch(job.input.url);
if (response.status === 429) {
// Rate limited — retry after the specified delay
const retryAfter = parseInt(response.headers.get("Retry-After") || "60", 10);
rescheduleJob({ afterMs: retryAfter * 1000 });
}
if (!response.ok) {
// Other errors use default exponential backoff
throw new Error(`API error: ${response.status}`);
}
const data = await response.json();
return complete(() => ({ data }));
},
},
},
}),
});
const stop = await worker.start();
```
`rescheduleJob` throws a `RescheduleJobError` which the worker catches specially. Unlike regular errors that trigger exponential backoff based on attempt count, `rescheduleJob` uses your specified schedule exactly:
```ts
rescheduleJob({ afterMs: 30_000 }); // 30 seconds from now
rescheduleJob({ at: new Date("2026-06-15T09:00:00Z") }); // specific time
rescheduleJob({ afterMs: 60_000 }, originalError); // with cause for logging
```
## lastAttemptError
[Section titled “lastAttemptError”](#lastattempterror)
On retry, `job.lastAttemptError` contains the serialized error from the previous attempt. Use it for logging or to adjust retry behavior:
```ts
attemptHandler: async ({ job, complete }) => {
if (job.lastAttemptError != null) {
console.log(`Previous attempt failed: ${job.lastAttemptError}`);
}
// ...
},
```
| Thrown value | Stored as |
| -------------- | --------------------------------------------------------------------------- |
| `Error` object | Stack trace (includes message). Own enumerable properties appended as JSON. |
| Plain object | JSON-stringified |
| String | Stored as-is |
Values are truncated to 10,000 characters.
See [examples/showcase-error-handling](https://github.com/kvet/queuert/tree/main/examples/showcase-error-handling) for a complete working example demonstrating discriminated unions, compensation patterns, and explicit rescheduling. See also [Job Processing Reliability](../processing-reliability/) for engine-level safety guarantees (savepoints, automatic rollback), [Timeouts](../timeouts/), and [Job Processing Modes](../processing-modes/).
# Horizontal Scaling
> Deploy multiple workers sharing the same database.
Deploy multiple worker processes sharing the same database for horizontal scaling. Workers coordinate via database-level locking (`FOR UPDATE SKIP LOCKED`) — no external coordination required.

## Identical Workers
[Section titled “Identical Workers”](#identical-workers)
The simplest approach: deploy the same worker configuration on multiple machines or processes.
```ts
// Process A (e.g., machine-1)
const workerA = await createInProcessWorker({
client,
workerName: "worker-a",
concurrency: 10,
processors: createProcessors({ client, jobTypes, processors: { ... } }),
});
// Process B (e.g., machine-2)
const workerB = await createInProcessWorker({
client,
workerName: "worker-b",
concurrency: 10,
processors: createProcessors({ client, jobTypes, processors: { ... } }),
});
```
`workerName` is an optional human-readable label. The runtime always appends a random UUID, so two replicas sharing the same name still get distinct ids and cannot collide on lease ownership. Workers compete for available jobs — when one acquires a job, others skip it. The notify adapter (Redis, PostgreSQL LISTEN/NOTIFY, etc.) ensures workers wake up immediately when new jobs are queued.
## Specialized Workers
[Section titled “Specialized Workers”](#specialized-workers)
A worker only processes the job types in its processor registry. This lets you run different worker topologies optimized for different workloads — a worker that doesn’t define a processor for a job type simply ignores it. The same mechanism powers [prioritization](../prioritization/): reserve capacity for an urgent workload by giving it a worker of its own.
For CPU-heavy work, spawn each worker in its own thread so they get true parallelism. Each thread creates its own client, state adapter, and worker — they share nothing except the database:
image-worker-thread.ts
```ts
// Each thread runs independently with its own database connection
const stateAdapter = await createPgStateAdapter({ stateProvider });
const client = await createClient({
stateAdapter,
notifyAdapter,
jobTypes: imageJobTypes,
});
const worker = await createInProcessWorker({
client,
workerName: `image-worker-${threadId}`,
concurrency: 1,
processors: createProcessors({
client,
jobTypes,
processors: {
"images.resize": { attemptHandler: resizeHandler },
"images.transcode": { attemptHandler: transcodeHandler },
},
}),
});
```
main.ts
```ts
import { Worker } from "node:worker_threads";
// 10 threads for CPU-heavy image processing
for (let i = 0; i < 10; i++) {
new Worker("./image-worker-thread.ts");
}
// Lightweight async I/O — single worker in main thread, high concurrency
const notificationWorker = await createInProcessWorker({
client,
workerName: "notification-worker",
concurrency: 100,
processors: createProcessors({
client,
jobTypes,
processors: {
"notifications.send-email": { attemptHandler: emailHandler },
"notifications.send-sms": { attemptHandler: smsHandler },
},
}),
});
```
This works because chains are stored in the database, not in worker memory. A chain that starts with `images.resize` (picked up by an image worker thread) can `continueWith` to `notifications.send-email` (picked up by the notification worker in the main thread) — the handoff happens through the database.
You can also combine slices when a single worker should handle multiple domains:
```ts
const worker = await createInProcessWorker({
client,
processors: [orderProcessors, notificationProcessors],
});
```
See [Feature Slices](../slices/) for organizing job types and processors into independent modules.
## See Also
[Section titled “See Also”](#see-also)
* [examples/state-postgres-multi-worker](https://github.com/kvet/queuert/tree/main/examples/state-postgres-multi-worker) — multiple workers sharing a PostgreSQL database
* [Prioritization](../prioritization/) — reserving worker capacity for urgent workloads
* [In-Process Worker](/queuert/advanced/in-process-worker/) — worker lifecycle and configuration
* [State Adapters](/queuert/integrations/state-adapters/) — database adapter setup
# Job Blockers
> Fan-out/fan-in job dependencies.
Jobs can depend on other chains to complete before they start. A job with incomplete blockers starts as `blocked` and transitions to `pending` when all blockers complete.

```ts
const jobTypes = defineJobTypes<{
"fetch-data": {
entry: true;
input: { url: string };
output: { data: string };
};
"process-all": {
entry: true;
input: { ids: string[] };
output: { results: string[] };
blockers: [{ typeName: "fetch-data" }, ...{ typeName: "fetch-data" }[]]; // Wait for multiple fetches (tuple with rest)
};
}>();
// Start with blockers (transactionHooks required — see Transaction Hooks guide)
const fetchBlockers = await withTransactionHooks(async (transactionHooks) =>
client.startChains({
transactionHooks,
items: [
{ typeName: "fetch-data", input: { url: "/a" } },
{ typeName: "fetch-data", input: { url: "/b" } },
],
}),
);
await withTransactionHooks(async (transactionHooks) =>
client.startChain({
transactionHooks,
typeName: "process-all",
input: { ids: ["a", "b", "c"] },
blockers: fetchBlockers,
}),
);
// Access completed blockers in worker
const worker = await createInProcessWorker({
client,
processors: createProcessors({
client,
jobTypes,
processors: {
"process-all": {
attemptHandler: async ({ job, complete }) => {
const results = job.blockers.map((b) => b.output.data);
return complete(() => ({ results }));
},
},
},
}),
});
const stop = await worker.start();
```
## Blocker References
[Section titled “Blocker References”](#blocker-references)
The example above uses **nominal references** — `{ typeName: "fetch-data" }`. Blockers also support fixed tuple slots, variadic rest slots, and **structural references** (`{ input: {...} }`) that match any entry job type with a compatible input shape. Blocker outputs are fully typed in the processor based on the reference. See [Job Type References](/queuert/advanced/job-type-references/) for details and examples.
See [examples/showcase-blockers](https://github.com/kvet/queuert/tree/main/examples/showcase-blockers) for a complete working example demonstrating fan-out/fan-in and fixed blocker slots. See also [Transaction Hooks](../transaction-hooks/) and [Chain Patterns](../chain-patterns/).
# Job Attempt Middleware
> Wrap job attempts with cross-cutting logic — tracing, resource injection, audit, contextual logging.
`AttemptMiddleware` wraps a **job attempt** — the unit of work that includes the prepare phase, the handler, and the complete phase. Middleware lets you add cross-cutting logic (tracing spans, contextual loggers, audit trails, shared resources) without touching each individual handler.
A middleware has three optional hooks, each wrapping a different phase:
| Hook | Wraps | Injects ctx into |
| -------------- | ----------------------------------- | ------------------------- |
| `wrapHandler` | the whole attempt handler | `attemptHandler` options |
| `wrapPrepare` | the user-supplied prepare callback | prepare-callback options |
| `wrapComplete` | the user-supplied complete callback | complete-callback options |
All three accept a `next(ctx)` call that yields the inner layer. The object passed to `next` is merged into the callback options for that phase, and its type flows into the handler signature.
See the [Worker reference](/queuert/reference/queuert/worker/#attemptmiddleware) for the full type definition.
## When to use each hook
[Section titled “When to use each hook”](#when-to-use-each-hook)
### `wrapHandler` — cross-cutting around the whole attempt
[Section titled “wrapHandler — cross-cutting around the whole attempt”](#wraphandler--cross-cutting-around-the-whole-attempt)
Use for concerns that span the full attempt: tracing spans, contextual loggers, per-job resources, error classification.
```ts
const tracing: AttemptMiddleware = {
wrapHandler: async ({ job, next }) => {
const traceId = crypto.randomUUID();
console.log(`[${traceId}] start ${job.typeName}`);
try {
return await next({ traceId });
} finally {
console.log(`[${traceId}] end`);
}
},
};
```
Inside the handler, `traceId` is typed:
```ts
attemptHandler: async ({ traceId, complete }) => {
return complete(async () => ({
/* ... */
}));
};
```
### `wrapPrepare` — set up shared data inside the prepare transaction
[Section titled “wrapPrepare — set up shared data inside the prepare transaction”](#wrapprepare--set-up-shared-data-inside-the-prepare-transaction)
Use when you want to load a resource once per attempt and make it available to the handler. The middleware runs inside the prepare transaction (so DB reads are consistent with the rest of the attempt).
```ts
const loadUser: AttemptMiddleware = {
wrapPrepare: async ({ job, txCtx, next }) => {
const user = await userRepo.findById(job.input.userId, { txCtx });
return next({ user });
},
};
```
The handler invokes the prepare callback explicitly to receive the injected ctx:
```ts
attemptHandler: async ({ prepare, complete }) => {
const user = await prepare({ mode: "staged" }, async ({ user }) => user);
return complete(async () => ({
/* ... */
}));
};
```
### `wrapComplete` — inject helpers used during completion
[Section titled “wrapComplete — inject helpers used during completion”](#wrapcomplete--inject-helpers-used-during-completion)
Use to inject helpers that are only meaningful in the complete transaction — audit recorders, outbox inserters, post-commit notifiers.
```ts
const audit: AttemptMiddleware void }> = {
wrapComplete: async ({ job, txCtx, next }) =>
next({
audit: (event) => auditRepo.insert({ event, jobId: job.id, txCtx }),
}),
};
```
```ts
return complete(async ({ audit }) => {
audit("order-placed");
return {
/* ... */
};
});
```
## Composition and order
[Section titled “Composition and order”](#composition-and-order)
Multiple middlewares compose as an onion. The first middleware’s “before” runs outermost:
```ts
attemptMiddleware: [tracing, audit];
// tracing before → audit before → handler → audit after → tracing after
```
Each `next(ctx)` call accumulates ctx for inner layers. The handler’s final ctx is the intersection of all injected ctxs.
## Sharing middleware across registries
[Section titled “Sharing middleware across registries”](#sharing-middleware-across-registries)
Middleware is declared on the processor registry, not the worker:
```ts
const registry = createProcessors({
client,
jobTypes,
attemptMiddleware: [tracing, audit],
processors: {
/* ... */
},
});
```
To share a common set of middleware across multiple registries (e.g. multiple [slices](/queuert/guides/slices/) merged into one worker), list them inline at each call site:
```ts
const orderRegistry = createProcessors({
client,
jobTypes,
attemptMiddleware: [tracing, log, auditOrders],
processors: {
/* ... */
},
});
const notificationRegistry = createProcessors({
client,
jobTypes,
attemptMiddleware: [tracing, log, auditNotifications],
processors: {
/* ... */
},
});
```
Per slice, handler ctx types reflect the actual middleware list for that registry — so `auditOrders` ctx is visible in order handlers but not notification handlers. Inline literals narrow tuple inference automatically; no `as const` is required.
## See also
[Section titled “See also”](#see-also)
* [Showcase example](https://github.com/kvet/queuert/tree/main/examples/showcase-middleware) — runnable end-to-end demo of all three hooks
* [Worker reference](/queuert/reference/queuert/worker/#attemptmiddleware) — full API
* [Slices guide](/queuert/guides/slices/) — splitting workflows across registries
# Prioritization
> Reserve worker capacity for urgent workloads by partitioning job types across workers.
Queuert has no built-in `priority` field. Prioritization is a consequence of **partitioning workloads across workers**: each worker owns a subset of job types, and its capacity (concurrency slots) is reserved for those types only. Give an urgent workload its own worker and it can never wait behind a long or slow one.

## Workloads and Capacity
[Section titled “Workloads and Capacity”](#workloads-and-capacity)
A worker provides a fixed amount of capacity — up to `concurrency` jobs in flight at once. By default, every job type in its processor registry competes for those same slots. If one worker registers every type, a long-running bulk workload can occupy every slot and stall urgent work behind it.
The fix is to run multiple workers, each owning a different subset of job types. Each worker’s capacity is reserved for its own workload.
```ts
const jobTypes = defineJobTypes<{
"email.transactional": { entry: true; input: { to: string }; output: { at: number } };
"email.marketing": { entry: true; input: { to: string }; output: { at: number } };
}>();
const client = await createClient({ stateAdapter, notifyAdapter, jobTypes });
// Customer-facing workload (password resets, 2FA): reserved capacity.
const transactionalWorker = await createInProcessWorker({
client,
workerName: "email-transactional",
concurrency: 3,
processors: createProcessors({
client,
jobTypes,
processors: {
"email.transactional": { attemptHandler: sendTransactionalHandler },
},
}),
});
// Bulk workload (digests, newsletters): throttled, won't interfere with the other worker.
const marketingWorker = await createInProcessWorker({
client,
workerName: "email-marketing",
concurrency: 1,
processors: createProcessors({
client,
jobTypes,
processors: {
"email.marketing": { attemptHandler: sendMarketingHandler },
},
}),
});
```
Each worker’s acquisition query filters to its own `typeNames`, so the transactional worker never observes the marketing backlog and picks urgent work up the moment it’s enqueued. See [examples/showcase-multiworker-prioritization](https://github.com/kvet/queuert/tree/main/examples/showcase-multiworker-prioritization) for a runnable version.
## Tradeoffs vs. a Shared Pool
[Section titled “Tradeoffs vs. a Shared Pool”](#tradeoffs-vs-a-shared-pool)
Partitioning reserves capacity: a workload with its own worker always has slots available.
The cost is utilization. Idle slots on one worker cannot drain another worker’s backlog. If the reserved workload is bursty and rare, its slots sit unused while other work piles up elsewhere. A single worker with adequate concurrency is simpler and has higher utilization — partition only when a specific workload’s latency matters enough to justify reserving capacity for it.
Start with one worker. Split when you have evidence that a specific workload is being delayed by others.
## Interactions
[Section titled “Interactions”](#interactions)
### Chains
[Section titled “Chains”](#chains)
A chain’s `continueWith` can target any job type, so a single chain can start on one worker and continue on another. The handoff happens through the database:
```ts
const jobTypes = defineJobTypes<{
"alert.dispatch": {
entry: true;
input: { alertId: string };
continueWith: { typeName: "alert.archive" };
};
"alert.archive": {
input: { alertId: string };
output: { archivedAt: number };
};
}>();
```
With `alert.dispatch` on the urgent worker and `alert.archive` on the bulk worker, the time-sensitive step runs under reserved capacity and the follow-up is deferred to cheaper bulk capacity.
### Blockers
[Section titled “Blockers”](#blockers)
[Blockers](../job-blockers/) are cross-chain, so they work regardless of which worker the blocking chain runs on — a bulk job can block on urgent prerequisites, or the reverse. The job type decides which worker eventually picks up the blocked job once its blockers complete.
### Deduplication
[Section titled “Deduplication”](#deduplication)
[Deduplication](../deduplication/) keys are scoped by chain type. If you model the same logical work as two separate job types (one per workload), submitting the same key to each will not dedup across them:
```ts
// Two chains — the key is namespaced by typeName, so these don't collide.
await client.startChain({ typeName: "sync.transactional", deduplication: { key: "sync:user:42" }, ... });
await client.startChain({ typeName: "sync.marketing", deduplication: { key: "sync:user:42" }, ... });
```
Decide which workload a job belongs to before enqueueing, then submit to exactly one type. Don’t rely on the dedup key alone to collapse duplicates across workloads.
## One Client vs. Multiple Clients
[Section titled “One Client vs. Multiple Clients”](#one-client-vs-multiple-clients)
One `createClient` owns one `jobTypes`. Two ways to split workloads across workers:
* **One client, multiple workers** — the default. Each worker subsets the shared registry via its own `Processors`. Use when workloads share the same database and notify adapter.
* **Multiple clients** — one client per workload, each with its own registry, adapters, and connection pool. Reach for this when workloads need different infrastructure: separate connection pools to cap each workload’s DB load, different notify channels, or notify adapters that scale independently.
Start with one client. Split only when a concrete resource constraint forces it.
## See Also
[Section titled “See Also”](#see-also)
* [examples/showcase-multiworker-prioritization](https://github.com/kvet/queuert/tree/main/examples/showcase-multiworker-prioritization) — urgent workload overtaking a bulk backlog; cross-worker chain handoff
* [Horizontal Scaling](../horizontal-scaling/) — worker topologies and when to specialize
* [Feature Slices](../slices/) — organizing job types and processors by domain
# Job Processing Modes
> Choosing between atomic and staged modes, auto-setup defaults, and common anti-patterns.
## Atomic Mode
[Section titled “Atomic Mode”](#atomic-mode)

Most jobs don’t need `prepare`. Call `complete` directly and you get atomic mode automatically — one transaction for all reads and writes:
```ts
'reserve-inventory': {
attemptHandler: async ({ job, complete }) => {
return complete(async ({ sql }) => {
const [item] = await sql`SELECT stock FROM items WHERE id = ${job.input.id}`;
if (item.stock < 1) throw new Error("Out of stock");
await sql`UPDATE items SET stock = stock - 1 WHERE id = ${job.input.id}`;
return { reserved: true };
});
},
}
```
This is the default path. If you’re not sure which mode to use, start here.
## Staged Mode
[Section titled “Staged Mode”](#staged-mode)

Use staged mode when you need to do work **between** two transactions — typically external API calls that shouldn’t hold a database transaction open:
```ts
'charge-payment': {
attemptHandler: async ({ job, prepare, complete }) => {
// Phase 1: Read state (transaction)
const order = await prepare({ mode: "staged" }, async ({ sql }) => {
const [row] = await sql`SELECT * FROM orders WHERE id = ${job.input.id}`;
return row;
});
// Transaction closed, lease renewal active
// Phase 2: External API call (no transaction)
const { paymentId } = await paymentAPI.charge(order.amount);
// Phase 3: Write results (new transaction)
return complete(async ({ sql }) => {
await sql`UPDATE orders SET payment_id = ${paymentId} WHERE id = ${order.id}`;
return { paymentId };
});
},
}
```
## When to Use What
[Section titled “When to Use What”](#when-to-use-what)
```plaintext
Do you need to call an external API or do long-running
work between reading and writing?
├── No → Just call complete() directly (auto-setup atomic)
└── Yes → Use prepare({ mode: "staged" })
Read in prepare, do external work, write in complete
```
In practice, explicit `prepare` with a fixed mode is rarely needed. `prepare({ mode: "atomic" })` does the same thing as calling `complete` directly but with extra ceremony. The main reason to use explicit `prepare` is when the mode is **dynamic** — determined at runtime based on job input or application state.
## Auto-Setup
[Section titled “Auto-Setup”](#auto-setup)
When you skip `prepare`, Queuert infers the mode from how you call `complete`:
| Pattern | Mode | What happens |
| --------------------------------------- | ------ | -------------------------------------------------- |
| `return complete(...)` (synchronous) | Atomic | Single transaction wraps everything |
| `await something; return complete(...)` | Staged | Lease renewal runs between async work and complete |
This means even without `prepare`, you can get staged behavior by doing async work before calling `complete`:
```ts
'send-notification': {
attemptHandler: async ({ job, complete }) => {
await emailService.send(job.input.to, job.input.body);
return complete(async ({ sql }) => {
await sql`UPDATE notifications SET sent = true WHERE id = ${job.input.id}`;
return { sentAt: new Date().toISOString() };
});
},
}
```
## Anti-Patterns
[Section titled “Anti-Patterns”](#anti-patterns)
Using staged mode with nothing between prepare and complete
Staged mode adds a round-trip and loses read consistency for no benefit. Put everything in `complete()` instead.
```ts
attemptHandler: async ({ job, prepare, complete }) => {
const data = await prepare({ mode: "staged" }, async ({ sql }) => {
return (await sql`SELECT * FROM items WHERE id = ${job.input.id}`)[0];
});
return complete(async ({ sql }) => {
await sql`UPDATE items SET status = 'done' WHERE id = ${data.id}`;
return { done: true };
});
};
```
Using prepare with atomic mode when complete alone suffices
This is the same as calling `complete()` directly, but with extra ceremony.
```ts
attemptHandler: async ({ job, prepare, complete }) => {
const item = await prepare({ mode: "atomic" }, async ({ sql }) => {
return (await sql`SELECT stock FROM items WHERE id = ${job.input.id}`)[0];
});
return complete(async ({ sql }) => {
await sql`UPDATE items SET stock = stock - 1 WHERE id = ${job.input.id}`;
return { reserved: true };
});
};
```
The exception is dynamic handlers where the mode is determined at runtime — explicit `prepare` is the right choice there since auto-setup can’t express conditional logic.
## See Also
[Section titled “See Also”](#see-also)
See [examples/showcase-processing-modes](https://github.com/kvet/queuert/tree/main/examples/showcase-processing-modes) for a complete working example. See also [Job Processing Reliability](../processing-reliability/), [Error Handling](../error-handling/), [Timeouts](../timeouts/), and [Job Processing](/queuert/advanced/job-processing/) reference.
# Job Processing Reliability
> How Queuert keeps jobs safe when errors occur — savepoints, transaction poisoning protection, automatic rollback, and rescheduling.
When your code throws during job processing, the engine catches the error, rolls back any partial work, and reschedules the job with backoff. This happens automatically — no defensive error handling is needed inside your callbacks.
This guide covers the engine’s safety guarantees. For user-level error strategies (discriminated unions, compensation, rescheduling), see [Error Handling](../error-handling/). For the architectural overview of savepoints and transaction poisoning, see [Job Processing](/queuert/advanced/job-processing/#error-recovery-and-savepoints).
## The Short Version
[Section titled “The Short Version”](#the-short-version)
1. Both `prepare` and `complete` callbacks run inside **database savepoints**.
2. If a callback throws, the savepoint **rolls back** any partial SQL it executed.
3. The outer transaction stays healthy, so the engine can **reschedule** the job with exponential backoff.
4. This works regardless of *where* the error occurs — in `prepare`, between phases, in `complete`, or after `complete` returns.
The rest of this page walks through each scenario with code examples.
## Error in Prepare Callback
[Section titled “Error in Prepare Callback”](#error-in-prepare-callback)
The `prepare` callback runs inside a savepoint. If it throws, the savepoint rolls back and the job is rescheduled using the processor’s `backoffConfig` (or the default exponential backoff).
```ts
'charge-payment': {
backoffConfig: { initialDelayMs: 1000, multiplier: 2, maxDelayMs: 60_000 },
attemptHandler: async ({ job, prepare, complete }) => {
const order = await prepare({ mode: "staged" }, async ({ sql }) => {
// If this throws (constraint violation, missing row, etc.),
// the savepoint rolls back and the job retries after backoff
const [row] = await sql`SELECT * FROM orders WHERE id = ${job.input.orderId}`;
if (!row) throw new Error("Order not found");
return row;
});
const { paymentId } = await paymentAPI.charge(order.amount);
return complete(async ({ sql }) => {
await sql`UPDATE orders SET payment_id = ${paymentId} WHERE id = ${order.id}`;
return { paymentId };
});
},
}
```
In **atomic mode**, the prepare savepoint rolls back within the same transaction that acquired the job, and the reschedule commits in that transaction. In **staged mode**, the behavior is the same — the prepare transaction has not committed yet, so the rollback + reschedule happen in one transaction.
## Error in Complete Callback
[Section titled “Error in Complete Callback”](#error-in-complete-callback)
The `complete` callback also runs inside a savepoint. If it throws, the savepoint rolls back — undoing any SQL the callback executed, the `completeJob` call, and any continuation jobs created via `continueWith` — and the job is rescheduled with backoff.
```ts
'transfer-funds': {
attemptHandler: async ({ job, complete }) => {
return complete(async ({ sql }) => {
// If the CHECK constraint fires, the savepoint rolls back
// and the job is rescheduled — no corrupted state
await sql`UPDATE accounts SET balance = balance - ${job.input.amount}
WHERE id = ${job.input.fromId}`;
await sql`UPDATE accounts SET balance = balance + ${job.input.amount}
WHERE id = ${job.input.toId}`;
return { transferred: true };
});
},
}
```
> **Tip:** The outer transaction — which holds the job lease — commits successfully with the reschedule, even though the savepoint rolled back. The job returns to pending status and retries after backoff.
## Error Between Prepare and Complete
[Section titled “Error Between Prepare and Complete”](#error-between-prepare-and-complete)
In **staged mode**, if an error occurs after `prepare` commits but before `complete` runs (typically a failed external API call), the job is rescheduled with backoff. Since prepare already committed, its side-effects persist — the complete phase retries in a fresh transaction on the next attempt.
```ts
'sync-external': {
attemptHandler: async ({ job, prepare, complete }) => {
const data = await prepare({ mode: "staged" }, async ({ sql }) => {
return (await sql`SELECT * FROM items WHERE id = ${job.input.id}`)[0];
});
// Prepare committed. If the API call below throws, the job retries
// and prepare runs again in a new transaction.
const externalId = await externalAPI.sync(data); // may throw
return complete(async ({ sql }) => {
await sql`UPDATE items SET external_id = ${externalId} WHERE id = ${data.id}`;
return { externalId };
});
},
}
```
In **atomic mode**, prepare and complete share the same transaction, so any error between them rolls back the entire transaction (including prepare’s work) and reschedules.
## Error After Complete
[Section titled “Error After Complete”](#error-after-complete)
The `complete` savepoint is only released when the handler returns successfully. If you `await complete()` and then throw, the completion — including `completeJob`, `unblockJobs`, continuation jobs, and any SQL you ran inside the callback — is atomically rolled back. The job is rescheduled as if `complete` never happened.
> **Note:** In **staged mode**, prepare’s committed work persists across retries. Design your staged handlers so that prepare’s side-effects are safe to keep when the complete phase retries.
## What This Means in Practice
[Section titled “What This Means in Practice”](#what-this-means-in-practice)
* **Any unhandled error → reschedule with backoff.** Whether the error occurs in `prepare`, between phases, in `complete`, or after `complete` — the job is always rescheduled. Backoff follows the processor’s `backoffConfig` or the default (10s → 20s → 40s → … → 300s cap).
* **No corrupted state.** Savepoints ensure that partial SQL work inside callbacks is never committed when an error occurs.
* **No orphaned continuations.** If `continueWith` was called inside `complete` and the handler throws afterward, both the continuation job and the completion are rolled back.
* **Blocked jobs stay blocked.** If a blocker job’s completion is rolled back, dependent jobs remain correctly blocked.
* **No defensive `try/catch` needed.** Let exceptions propagate naturally inside `prepare` and `complete` callbacks — the engine handles them.
* **Jobs retry indefinitely.** There is no maximum retry count. Use [discriminated unions or compensation patterns](../error-handling/) to handle permanently failing jobs.
## See Also
[Section titled “See Also”](#see-also)
See [examples/showcase-error-recovery](https://github.com/kvet/queuert/tree/main/examples/showcase-error-recovery) for a complete working example. See also [Error Handling](../error-handling/) for user-level error strategy, [Processing Modes](../processing-modes/) for atomic vs. staged mode details, and [Job Processing](/queuert/advanced/job-processing/) reference.
# Job & Chain Queries
> Read-only methods for inspecting jobs and chains.
The client provides read-only methods for inspecting chains and jobs. All query methods accept an optional transaction context and don’t require `transactionHooks`.
```ts
// Look up a single chain or job by ID
const chain = await client.getChain({ id: chainId });
const job = await client.getJob({ id: jobId });
// Paginated lists with filters
const chains = await client.listChains({
filter: { typeName: ["send-email"], status: ["running"] },
limit: 20,
});
const jobs = await client.listJobs({
filter: { chainId: [chainId], status: ["completed"] },
});
// Cursor-based pagination
const nextPage = await client.listChains({
filter: { typeName: ["send-email"] },
cursor: chains.nextCursor,
});
// Jobs within a specific chain, ordered by chain index
const chainJobs = await client.listChainJobs({ chainId });
// Blocker relationships
const blockers = await client.getJobBlockers({ jobId });
const blockedJobs = await client.listBlockedJobs({ chainId });
```
All lookup methods accept an optional `typeName` for type narrowing — the return type narrows to the specified type. If the entity exists but has a different type, `JobTypeMismatchError` is thrown.
See [examples/showcase-queries](https://github.com/kvet/queuert/tree/main/examples/showcase-queries) for a complete working example demonstrating single lookups, paginated lists, chain job listing, and blocker queries. See also [Client API](/queuert/reference/queuert/client/) reference and [Dashboard](/queuert/integrations/dashboard/).
## Performance considerations
[Section titled “Performance considerations”](#performance-considerations)
`listChains` joins each root row with the last job in the chain to resolve chain status. Filtering by `status` is not optimized — it applies to the joined last job and cannot use an index. Always provide a `typeName` or date range (`from`/`to`) filter to narrow the scan:
```ts
// Expensive — status filter alone still scans every root row
const all = await client.listChains({
filter: { status: ["running"] },
});
// Efficient — typeName narrows the scan via a partial index
const filtered = await client.listChains({
filter: { typeName: ["send-email"], status: ["running"] },
});
```
On PostgreSQL, long-running unfiltered scans hold MVCC snapshots that prevent autovacuum from reclaiming dead tuples, causing table bloat over time. See [PostgreSQL Internals](/queuert/advanced/postgres-internals/#listing-queries-and-vacuum) for details.
# Runtime Validation
> Add runtime validation with Zod, Valibot, TypeBox, or ArkType.
`defineJobTypes` gives you compile-time type safety with zero runtime cost. When job inputs come from outside your program — HTTP handlers, dashboards, cross-service cron payloads — TypeScript can’t reject a malformed value before your handler runs. `createJobTypes` closes that gap: it accepts validation callbacks that run at every boundary the library touches (entry, input, output, continuation, blockers).
## When to use it
[Section titled “When to use it”](#when-to-use-it)
Reach for `createJobTypes` when inputs cross a trust boundary, or when you already depend on a schema library (Zod, Valibot, TypeBox, ArkType) and want the same schemas to guard your jobs. Stick with `defineJobTypes` when every caller is internal code TypeScript already checks.
## Usage
[Section titled “Usage”](#usage)
You typically don’t call `createJobTypes` directly — you go through a thin schema-library adapter that infers `TJobTypeDefinitions` from your schemas and wires them into the validation callbacks. The Zod version looks like this:
```ts
import { createClient } from "queuert";
import { z } from "zod";
import { createZodJobTypes } from "./zod-adapter.js";
const jobTypes = createZodJobTypes({
"send-email": {
entry: true,
input: z.object({ to: z.string(), subject: z.string(), body: z.string() }),
output: z.object({ messageId: z.string() }),
},
});
const client = await createClient({ stateAdapter, notifyAdapter, jobTypes });
```
Handlers keep full type inference — `job.input` is typed from the Zod schema. The adapter itself is \~60 lines; copy it from [examples/validation-zod](https://github.com/kvet/queuert/tree/main/examples/validation-zod) or pick another library from the integration page.
## How errors surface
[Section titled “How errors surface”](#how-errors-surface)
A failed validation throws `JobTypeValidationError`. A `code` identifies which boundary rejected the value, and `typeName` identifies the job type:
```ts
import { JobTypeValidationError } from "queuert";
try {
await stateAdapter.withTransaction((ctx) =>
client.startChain({ ...ctx, transactionHooks, typeName: "send-email", input: untrusted }),
);
} catch (err) {
if (err instanceof JobTypeValidationError && err.code === "invalid_input") {
// 400 to the caller — the payload was malformed
}
}
```
Errors thrown by the underlying schema library (`ZodError`, `ValiError`, `TypeBoxError`, …) are caught and wrapped, so callers always handle a single error type regardless of which library the adapter uses. The five codes are `not_entry_point`, `invalid_input`, `invalid_output`, `invalid_continuation`, and `invalid_blockers`.
## See also
[Section titled “See also”](#see-also)
* [Validation Adapters](/queuert/integrations/validation-adapters/) — the adapter pattern, the six-method contract, and ready-to-copy adapters for Zod, Valibot, TypeBox, and ArkType
* [Custom Adapters](/queuert/advanced/custom-adapters/) — building and conformance-testing your own validation adapter
* [Error Handling](/queuert/guides/error-handling/) — how `JobTypeValidationError` interacts with retries and chain failure
# Scheduling
> Deferred start and recurring job patterns.
## Deferred Start
[Section titled “Deferred Start”](#deferred-start)
Jobs can be scheduled to start at a future time using the `schedule` option. The job is created transactionally but won’t be processed until the specified time.
* Relative delay (afterMs)
```ts
await withTransactionHooks(async (transactionHooks) =>
client.startChain({
transactionHooks,
typeName: "send-reminder",
input: { userId: "123" },
schedule: { afterMs: 5 * 60 * 1000 }, // 5 minutes from now
}),
);
```
* Specific time (at)
```ts
await withTransactionHooks(async (transactionHooks) =>
client.startChain({
transactionHooks,
typeName: "send-reminder",
input: { userId: "123" },
schedule: { at: scheduledDate },
}),
);
```
The same `schedule` option works with `continueWith` for deferred continuations:
```ts
return complete(async ({ continueWith }) =>
continueWith({
typeName: "follow-up",
input: { userId: job.input.userId },
schedule: { afterMs: 24 * 60 * 60 * 1000 }, // 24 hours later
}),
);
```
Tip
Combine `schedule` with `deduplication: { key }` to prevent duplicate future jobs — for example, ensuring only one reminder is queued per user even if the trigger fires multiple times. See [Deduplication](../deduplication/).
## Triggering Scheduled Jobs Early
[Section titled “Triggering Scheduled Jobs Early”](#triggering-scheduled-jobs-early)
A scheduled job is just a pending job with a future `scheduledAt`. Use `triggerJob` (or `triggerJobs` for a batch) to override the schedule and run it immediately — useful for admin “run now” actions or manually advancing a queued reminder.
```ts
await withTransactionHooks(async (transactionHooks) =>
client.triggerJob({
transactionHooks,
id: jobId,
}),
);
```
`triggerJob` throws `JobNotFoundError` if the job does not exist and `JobNotTriggerableError` if it is not `pending` (e.g. already running, completed, or blocked).
`triggerJobs` validates atomically — if any id in the batch is missing or not pending, the entire call fails and no job is triggered. Both methods are mutating and require `transactionHooks` + a transaction context.
## Recurring Jobs
[Section titled “Recurring Jobs”](#recurring-jobs)
For periodic tasks like daily digests, health checks, or billing cycles, start a new independent chain from within the handler instead of using `continueWith`. This keeps each execution as its own short-lived chain rather than building an ever-growing chain history.
```ts
const jobTypes = defineJobTypes<{
'daily-digest': {
entry: true;
input: { userId: string };
output: { sentAt: string };
};
}>();
// In processor — start a new chain with a scheduled delay
'daily-digest': {
attemptHandler: async ({ job, complete }) => {
await sendDigestEmail(job.input.userId);
return complete(async ({ sql, transactionHooks }) => {
if (userStillSubscribed) {
await client.startChain({
sql,
transactionHooks,
typeName: 'daily-digest',
input: { userId: job.input.userId },
schedule: { afterMs: 24 * 60 * 60 * 1000 }, // Run again tomorrow
deduplication: {
key: `digest:${job.input.userId}`,
excludeChainIds: [job.chainId], // Skip the completing chain
},
});
}
return { sentAt: new Date().toISOString() };
});
},
}
```
See [examples/showcase-scheduling](https://github.com/kvet/queuert/tree/main/examples/showcase-scheduling) for a complete working example demonstrating recurring jobs with scheduling and deduplication. See also [Deduplication](../deduplication/) and [Transaction Hooks](../transaction-hooks/).
# Feature Slices
> Organize job types and processors into independent feature modules.
As your application grows, defining all job types and processors in a single file becomes unwieldy. Feature slices let you split them by domain — each slice owns its type definitions and processor handlers, composed together at the application level.
## Defining a Slice
[Section titled “Defining a Slice”](#defining-a-slice)
A slice consists of two files: definitions and processors.
* src/
* **slice-orders-definitions.ts**
* **slice-orders-processors.ts**
* slice-notifications-definitions.ts
* slice-notifications-processors.ts
* client.ts
* index.ts
**Definitions** declare the job types for a feature:
slice-orders-definitions.ts
```ts
import { defineJobTypes } from "queuert";
export const orderJobTypes = defineJobTypes<{
"orders.create": { entry: true; input: { userId: string }; output: { orderId: string } };
"orders.fulfill": { input: { orderId: string }; output: { fulfilled: boolean } };
}>();
```
**Processors** implement the handlers, typed against the slice’s definitions:
slice-orders-processors.ts
```ts
import { createProcessors } from "queuert";
import { client } from "./client.js";
import { orderJobTypes } from "./slice-orders-definitions.js";
export const orderProcessors = createProcessors({
client,
jobTypes: orderJobTypes,
processors: {
"orders.create": {
attemptHandler: async ({ job, complete }) =>
complete(async ({ continueWith }) =>
continueWith({ typeName: "orders.fulfill", input: { orderId: "123" } }),
),
},
"orders.fulfill": {
attemptHandler: async ({ job, complete }) => complete(async () => ({ fulfilled: true })),
},
},
});
```
`createProcessors` type-checks each handler against the slice’s own definitions (plus any external defs it declares), then returns a `Processors` that’s plugged into `createInProcessWorker`.
## Composing Slices
[Section titled “Composing Slices”](#composing-slices)
At the application level, pass arrays of slices directly to `createClient` and `createInProcessWorker`:
```ts
import { createClient, createInProcessWorker } from "queuert";
import { orderJobTypes } from "./slice-orders-definitions.js";
import { orderProcessors } from "./slice-orders-processors.js";
import { notificationJobTypes } from "./slice-notifications-definitions.js";
import { notificationProcessors } from "./slice-notifications-processors.js";
const client = await createClient({
stateAdapter,
notifyAdapter,
jobTypes: [orderJobTypes, notificationJobTypes],
});
const worker = await createInProcessWorker({
client,
processors: [orderProcessors, notificationProcessors],
});
```
Both fields accept a single slice or an array of slices. When an array is passed, duplicate type/processor keys are detected:
* **`createClient` / `jobTypes`** — overlapping type names produce a TypeScript error at compile time; validated registries with overlapping `getTypeNames()` throw `DuplicateJobTypeError` at runtime.
* **`createInProcessWorker` / `processors`** — overlapping processor keys produce a TypeScript error at compile time and throw `DuplicateJobTypeError` at runtime.
## Cross-Slice References
[Section titled “Cross-Slice References”](#cross-slice-references)
When a slice needs to reference job types from another slice — for example, declaring a blocker from the notifications domain — use the optional `TExternal` type parameter on `defineJobTypes`:
slice-orders-definitions.ts
```ts
import { type JobTypeDefinitions, defineJobTypes } from "queuert";
import { type notificationJobTypes } from "./slice-notifications-definitions.js";
export const orderJobTypes = defineJobTypes<
{
"orders.place": {
entry: true;
input: { userId: string };
continueWith: { typeName: "orders.confirm" };
};
"orders.confirm": {
input: { orderId: string };
output: { confirmed: boolean };
blockers: [{ typeName: "notifications.send" }];
};
},
// External types — available for blocker reference validation, not owned by this slice
JobTypeDefinitions
>();
```
* `T` (first parameter) = owned definitions — these become the registry’s phantom type
* `TExternal` (second parameter) = read-only reference context, defaults to `Record`
* `blockers` validates against entry types in `T & TExternal`
* The registry’s phantom type remains `T` only — `TExternal` types are not included
This eliminates the need for “workflow slices” that duplicate type definitions just to make blocker references type-check. When slices are passed as an array to `createClient`, all references resolve against the full set of definitions.
When writing processors that reference types from another slice, nothing special is needed — the client already exposes every slice’s types, so `continueWith` and blockers resolve against the full set.
## Naming Convention
[Section titled “Naming Convention”](#naming-convention)
Note
Prefix job type names with the slice name to avoid collisions and make logs and dashboards easy to scan by feature.
```plaintext
orders.create-order
orders.fulfill-order
notifications.send-notification
```
## See Also
[Section titled “See Also”](#see-also)
* [Utilities](/queuert/reference/queuert/utilities/) — API reference for `defineJobTypes`, `createJobTypes`, `createProcessors`
* [Chain Patterns](../chain-patterns/) — continuation references and patterns
* [showcase-slices example](https://github.com/kvet/queuert/blob/main/examples/showcase-slices/src/index.ts) — full runnable example
# Timeouts
> Cooperative and hard timeouts for job processing.
For cooperative timeouts, combine `AbortSignal.timeout()` with the provided `signal`:
```ts
const worker = await createInProcessWorker({
client,
processors: createProcessors({
client,
jobTypes,
processors: {
"fetch-data": {
attemptHandler: async ({ signal, job, complete }) => {
const timeout = AbortSignal.timeout(30_000); // 30 seconds
const combined = AbortSignal.any([signal, timeout]);
// Use combined signal for cancellable operations
const response = await fetch(job.input.url, { signal: combined });
const data = await response.json();
return complete(() => ({ data }));
},
},
},
}),
});
const stop = await worker.start();
```
For hard timeouts, configure `leaseConfig` in the job type processor — if a job doesn’t complete or renew its lease in time, the reaper reclaims it for retry:
```ts
const worker = await createInProcessWorker({
client,
processors: createProcessors({
client,
jobTypes,
processors: {
'long-running-job': {
leaseConfig: { leaseMs: 300_000, renewIntervalMs: 60_000 }, // 5 min lease
attemptHandler: async ({ job, complete }) => { ... },
},
},
}),
});
```
See [examples/showcase-timeouts](https://github.com/kvet/queuert/tree/main/examples/showcase-timeouts) for a complete working example demonstrating cooperative timeouts and hard timeouts via lease. See also [Error Handling](../error-handling/) and [In-Process Worker](/queuert/advanced/in-process-worker/) reference.
# Transaction Hooks
> Buffer side effects during database transactions.
`withTransactionHooks` buffers side effects (like notify events) during a transaction and flushes them only after the callback returns successfully. On error, all buffered side effects are discarded.
* Callback (recommended)
Pass a callback to `withTransactionHooks`. Flush and discard are managed automatically — no manual cleanup needed.
```ts
await withTransactionHooks(async (transactionHooks) =>
sql.begin(async (sql) => {
await client.startChain({ sql, transactionHooks, typeName: "send-email", input });
// If the transaction rolls back, no notifications are sent
}),
);
```
* Manual
Use `createTransactionHooks` directly when your database client uses explicit `BEGIN`/`COMMIT`/`ROLLBACK` rather than a callback-style transaction.
Caution
You are responsible for calling `flush()` after a successful commit and `discard()` on error. Forgetting either will cause side effects to leak or accumulate indefinitely.
```ts
const { transactionHooks, flush, discard } = createTransactionHooks();
const connection = await db.connect();
try {
await connection.query("BEGIN");
const result = await client.startChain({
connection,
transactionHooks,
typeName: "send-email",
input,
});
await connection.query("COMMIT");
await flush(); // Side effects fire only after commit
return result;
} catch (error) {
await connection.query("ROLLBACK").catch(() => {});
await discard(); // Side effects discarded on error
throw error;
} finally {
connection.release();
}
```
## How It Works
[Section titled “How It Works”](#how-it-works)

`TransactionHooks` is a generic container for named hooks with mutable state. It knows nothing about Queuert itself — consumers (client, worker) register their own hooks using symbol keys.
A hook definition (`HookDefinition`) contains mutable state, a flush function, an optional discard function, and an optional checkpoint function. Multiple hooks can be registered on the same `TransactionHooks` instance. During the transaction, code mutates hook state freely. After the outer callback completes successfully, each hook’s flush function is called with its accumulated state. If the callback throws, each hook’s discard function is called instead — no flush occurs.
Hooks flush (and discard) concurrently — cross-hook execution order is not guaranteed. If your hook records ordered events, register every event under a single hook key and serialize the work inside `flush`/`discard` (e.g. iterate the accumulated state with `for…of await`).
## Savepoints
[Section titled “Savepoints”](#savepoints)
`TransactionHooks` supports savepoints for partial rollback of buffered side effects. This is useful when a sub-operation within a transaction may fail without invalidating the entire transaction.
* Callback (recommended)
`withSavepoint` runs a function and automatically rolls back hook state on error:
```ts
await transactionHooks.withSavepoint(async (transactionHooks) => {
// buffer side effects here
// if this throws, only side effects buffered inside this callback are rolled back
});
```
* Manual
`createSavepoint` returns a handle for fine-grained control:
```ts
const sp = transactionHooks.createSavepoint();
try {
// buffer side effects
sp.release(); // keep changes
} catch {
sp.rollback(); // discard changes since the savepoint
}
```

Savepoints rely on the `checkpoint` callback in `HookDefinition`. When a savepoint is created, each registered hook’s `checkpoint` is called to capture its current state. On rollback, the returned function restores the hook state to that point.
Hooks are registered lazily via `getOrInsert`. This avoids a separate registration step — the hook is created on first access and reused on subsequent accesses within the same transaction.
`withTransactionHooks` manages this lifecycle automatically: it creates the `TransactionHooks` instance, passes it to the callback, and calls flush on success or discard on error. `createTransactionHooks` exposes the same lifecycle for manual control — the caller is responsible for calling `flush()` after commit and `discard()` on error.
# Completing Without a Worker
> Complete jobs without a worker for approval workflows.
Jobs can be completed without a worker using `completeChain`. This enables approval workflows, webhook-triggered completions, and patterns where jobs wait for external events. Deferred start pairs well with this — schedule a job to auto-reject after a timeout, but allow early completion based on user action.
```ts
const jobTypes = defineJobTypes<{
"await-approval": {
entry: true;
input: { requestId: string };
output: { rejected: true };
continueWith: { typeName: "process-request" };
};
"process-request": {
input: { requestId: string };
output: { processed: true };
};
}>();
// Start a job that auto-rejects in 2 hours if not handled
const chain = await withTransactionHooks(async (transactionHooks) =>
client.startChain({
transactionHooks,
typeName: "await-approval",
input: { requestId: "123" },
schedule: { afterMs: 2 * 60 * 60 * 1000 }, // 2 hours
}),
);
// The worker handles the timeout case (auto-reject) and processes approved requests
const worker = await createInProcessWorker({
client,
processors: createProcessors({
client,
jobTypes,
processors: {
"await-approval": {
attemptHandler: async ({ complete }) => complete(() => ({ rejected: true })),
},
"process-request": {
attemptHandler: async ({ job, complete }) => {
await doSomethingWith(job.input.requestId);
return complete(() => ({ processed: true }));
},
},
},
}),
});
const stop = await worker.start();
// The job can be completed early without a worker (e.g., via API call)
await withTransactionHooks(async (transactionHooks) =>
client.completeChain({
transactionHooks,
...chain,
complete: async ({ job, complete }) => {
if (job.typeName !== "await-approval") {
return; // Already past approval stage
}
// If approved, continue to process-request; otherwise just reject
if (userApproved) {
await complete(job, ({ continueWith }) =>
continueWith({
typeName: "process-request",
input: { requestId: job.input.requestId },
}),
);
} else {
await complete(job, () => ({ rejected: true }));
}
},
}),
);
```
This pattern lets you interweave external actions with your chains — waiting for user input, third-party callbacks, or manual approval steps.
See [examples/showcase-workerless](https://github.com/kvet/queuert/tree/main/examples/showcase-workerless) for a complete working example demonstrating approval workflows and deferred start with early completion. See also [Transaction Hooks](../transaction-hooks/) and [Scheduling](../scheduling/) (deferred start).
## How It Works
[Section titled “How It Works”](#how-it-works)
The `completeChain` method receives the current job and a `complete` function. Inside `complete`, the caller can return an output to finish the chain or call `continueWith` to add the next job — the same interface as the worker’s prepare/complete pattern.
Internally, `complete` uses `FOR UPDATE` to lock the current job, preventing concurrent completion by a worker or another caller. The completed job has `completedBy: null` (no worker identity), distinguishing it from worker-completed jobs.
If a worker is already processing the job when `completeChain` runs, the worker detects the external completion via `JobAlreadyCompletedError`. The worker’s abort signal fires with reason `"already_completed"`, and the worker abandons its attempt gracefully.
# Dashboard
> Embeddable web UI for observing chains and jobs.
`@queuert/dashboard` provides an embeddable web UI for observing chains and jobs. It mounts as a single `fetch` handler on your existing server — no external build steps or runtime dependencies beyond `queuert`.
Experimental
API may change between minor versions.
## Quick start
[Section titled “Quick start”](#quick-start)
1. Install the package:
```bash
npm install @queuert/dashboard
```
2. Create the dashboard with your Queuert client:
```ts
import { createDashboard } from "@queuert/dashboard";
const dashboard = await createDashboard({ client });
```
3. Mount it on your server:
```ts
// Use with any server that accepts a fetch handler
serve({ fetch: dashboard.fetch, port: 3000 });
```
When mounting at a sub-path, set `basePath`:
```ts
const dashboard = await createDashboard({
client,
basePath: "/internal/queuert",
});
```
`createDashboard` accepts a Queuert `client` (created via `createClient`) and returns `{ fetch }` — a standard web `fetch` handler. Pass it to any server runtime (Node.js, Bun, Deno, etc.). The handler serves both API routes and the pre-built frontend.
The dashboard provides:
* **Chain list** — Browse chains with status badges, type filtering, and ID search
* **Chain detail** — Full job sequence, blocker relationships, and blocking chains
* **Job list** — Cross-chain job view with status/type filtering
* **Job detail** — Input/output data, error messages, lease info, continuation links
Supports a small set of mutations (triggering a blocked job, deleting a chain) in addition to read queries. Add authentication middleware before the dashboard handler to restrict access.
Performance on large tables
Chain listing joins each root row with the last job in the chain. Filtering by status alone is not optimized. Always use the type name filter when browsing large tables — see [Performance considerations](/queuert/guides/queries/#performance-considerations).
## UI views
[Section titled “UI views”](#ui-views)
### Chain list
[Section titled “Chain list”](#chain-list)
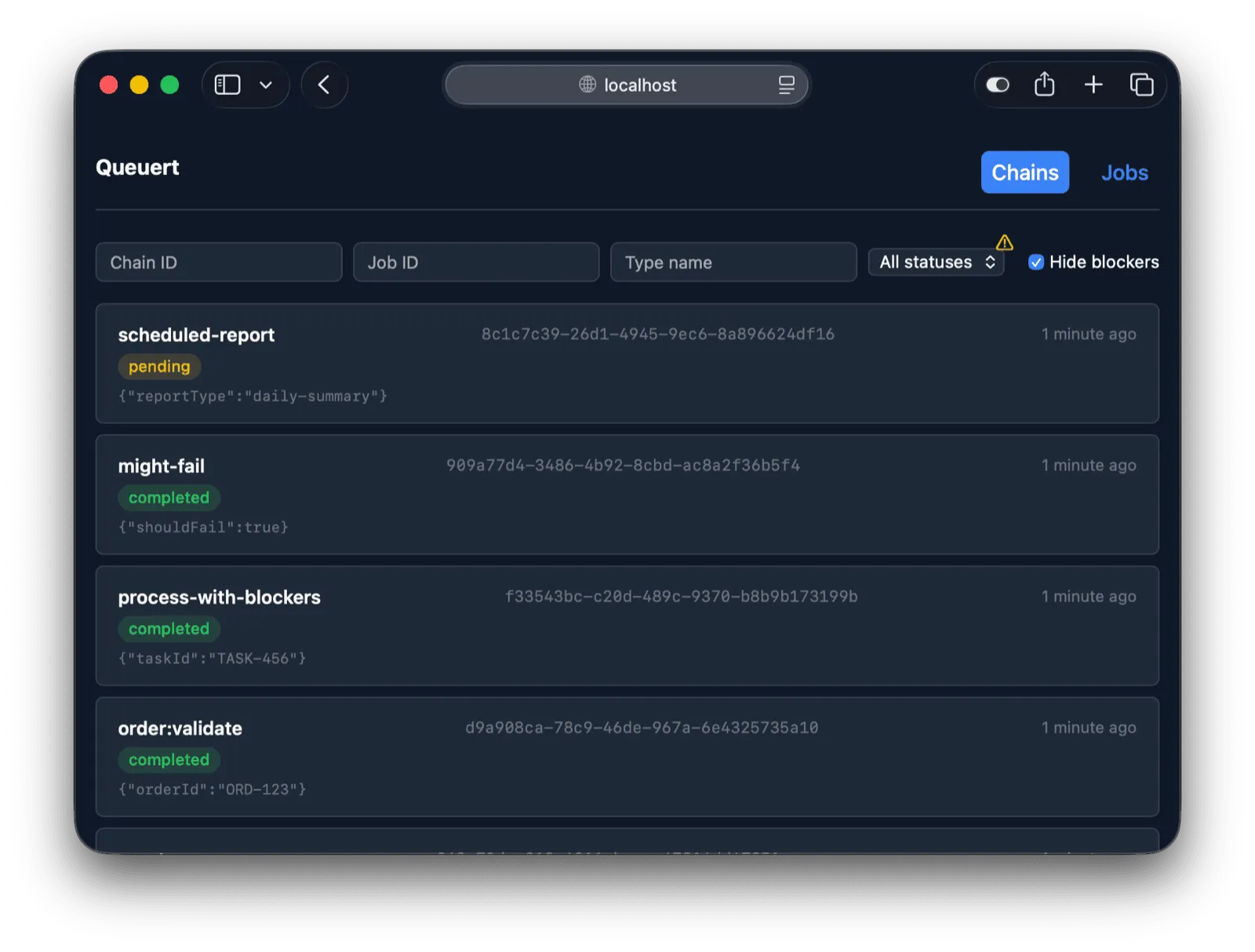
The primary view. Lists chains ordered by creation time (newest first) with inline previews. Each row shows the chain type name, chain ID, status badge, last job type (if the chain has continuations), attempt count (for blocked chains), creation time, and input preview.
Filtering supports searching by chain or job ID and by type name. Filter buttons next to type names and IDs let you quickly narrow results. A “Hide blockers” toggle filters out chains that are blockers for other chains. Pagination is cursor-based with a “Load more” button.
Clicking a row navigates to the chain detail view.
### Chain detail
[Section titled “Chain detail”](#chain-detail)
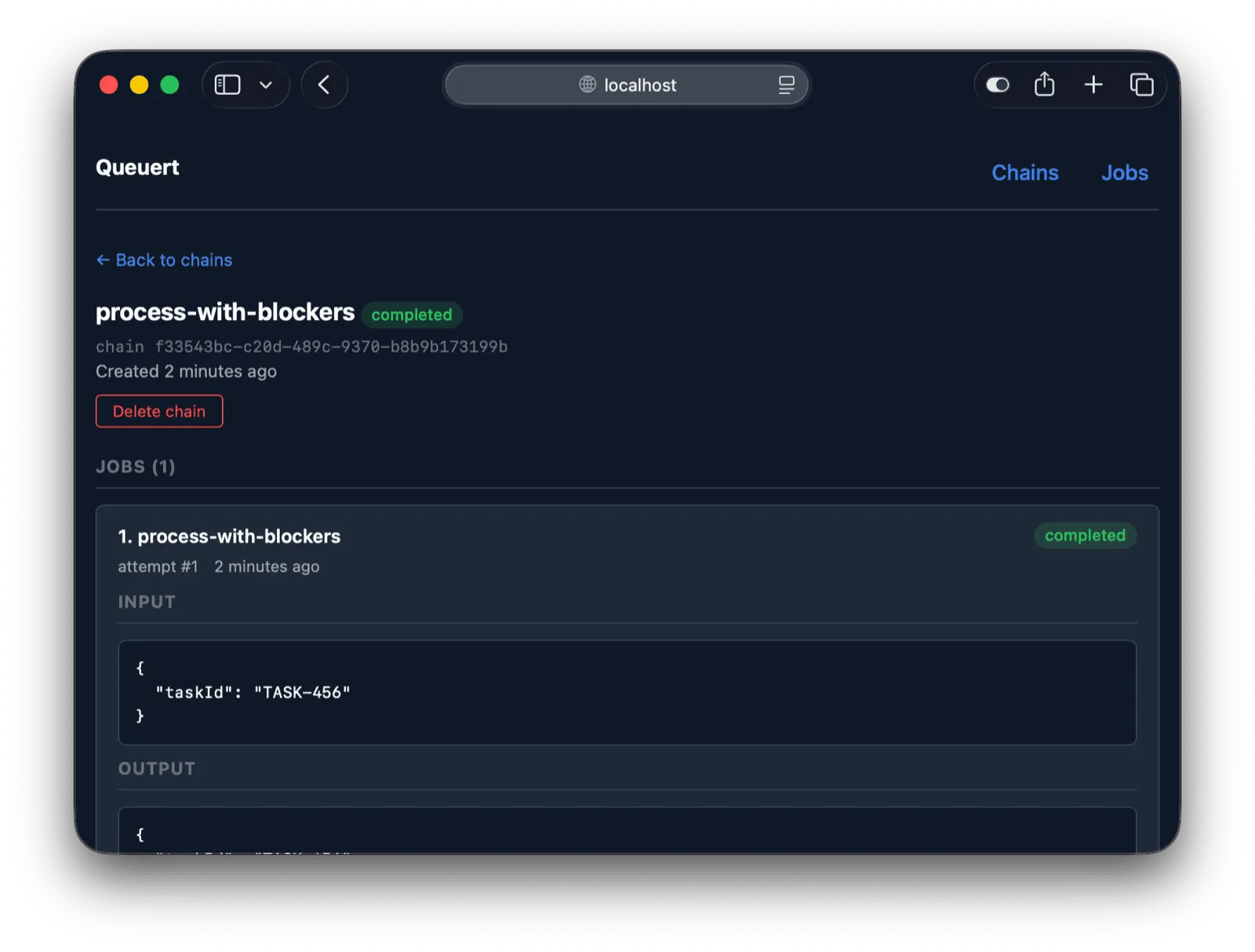
Shows a specific chain with its full job sequence and blocker relationships.
* **Jobs section**: All jobs in the chain, ordered by creation. Each job is a clickable card. Completed jobs show input and output. Running jobs show lease info and the worker processing them. Failed attempts show the error.
* **Blockers**: Shown per-job — only jobs that have blockers display a blockers subsection with chain links and status.
* **Blocking section**: Lists jobs from other chains that depend on this chain as a blocker.
### Job list
[Section titled “Job list”](#job-list)
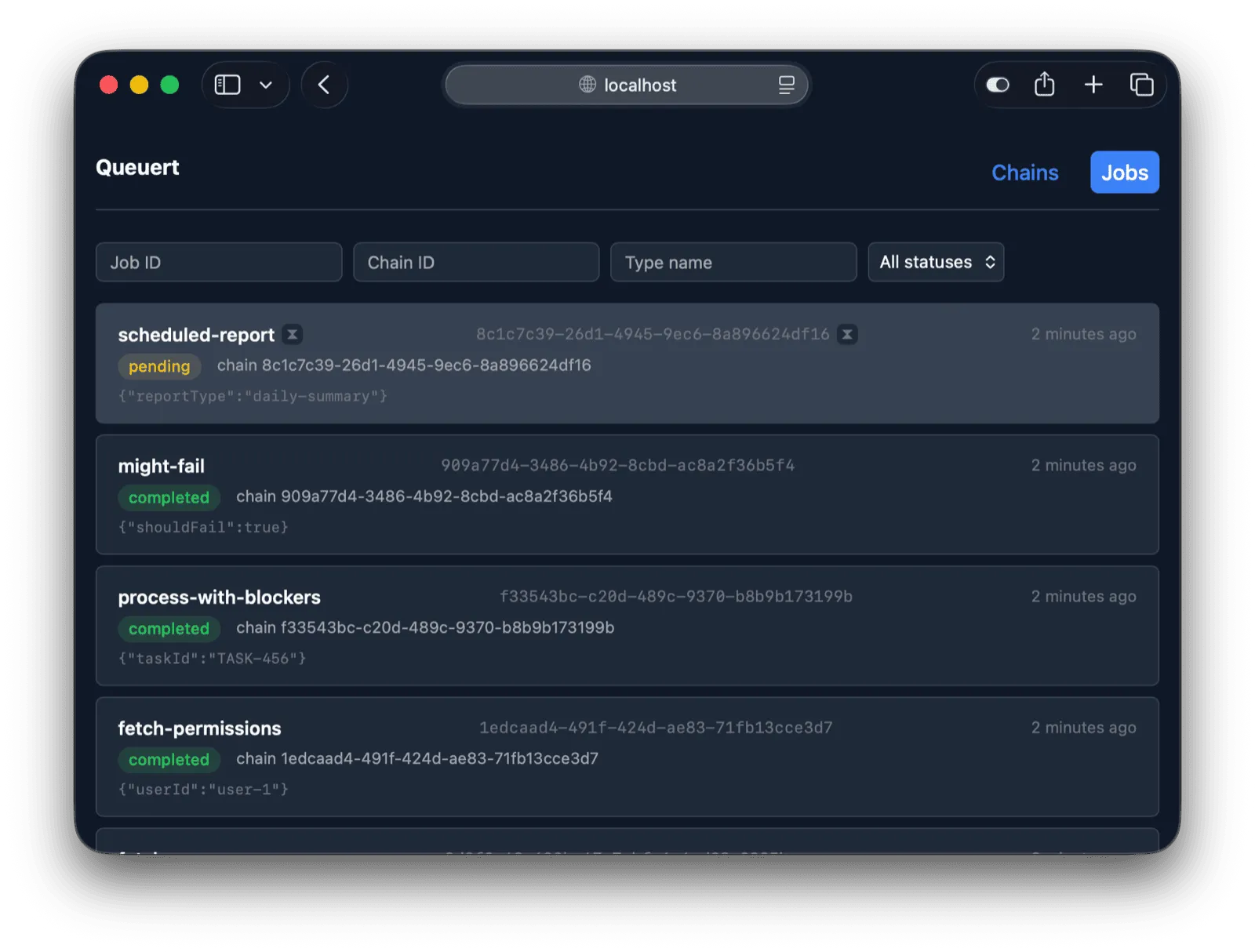
A cross-chain job view with the same layout as the chain list, but each row represents an individual job with a link to its parent chain. Supports filtering by job or chain ID, type name, and status.
### Job detail
[Section titled “Job detail”](#job-detail)
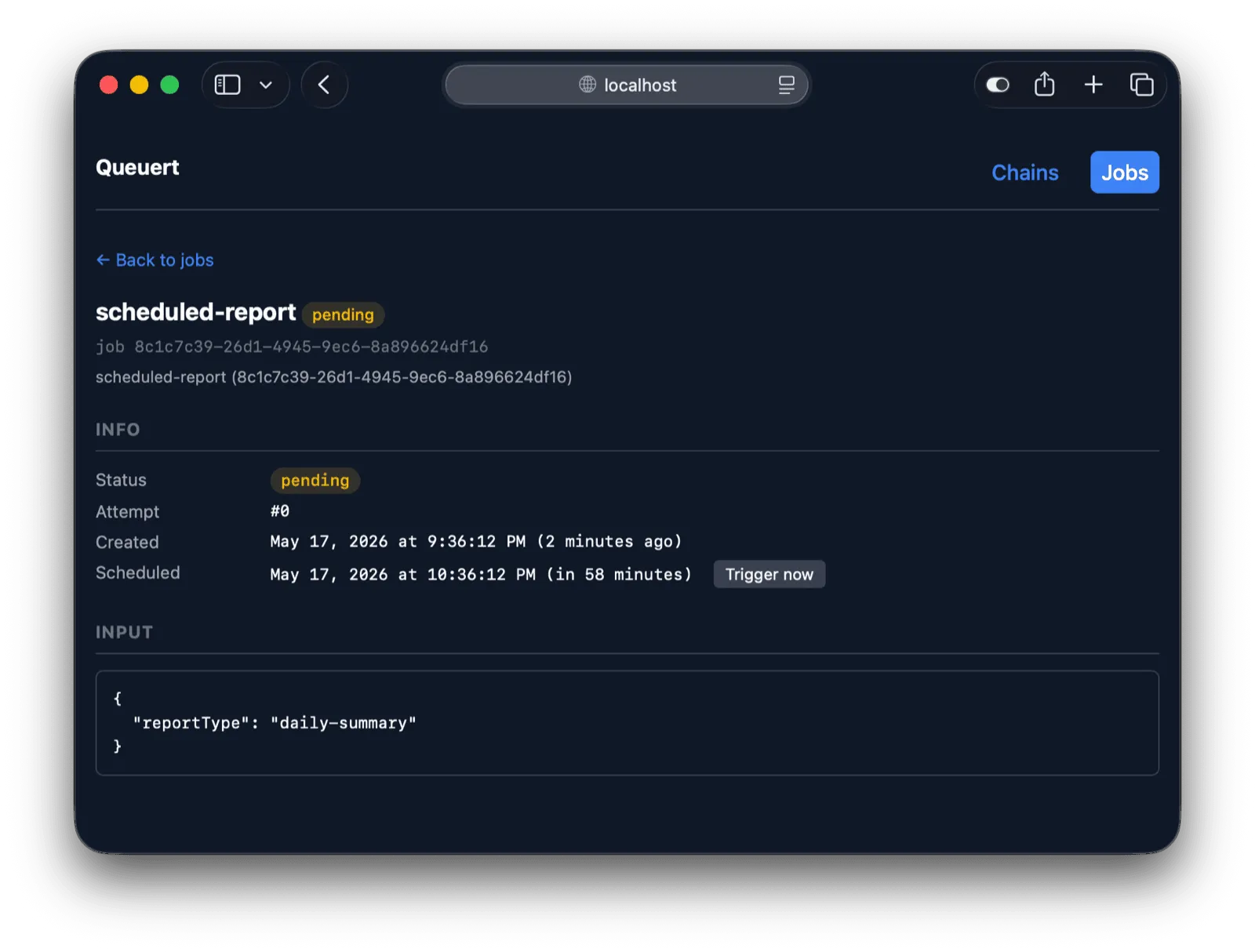
Full job inspection. Shown as a dedicated view when navigating from the job list, or inline-expanded in the chain detail view. Sections appear conditionally based on job state:
* **Info** — Status, attempt count, created/scheduled/completed timestamps, worker ID, and lease expiry.
* **Blockers** — Only when the job has blockers. Shows each blocker chain with its status.
* **Input** — The job’s input data as JSON.
* **Output** or **Continued with** (mutually exclusive) — Output shows the result JSON for terminal jobs. Continued with shows a link to the next job in the chain with its status.
* **Error** — When the job has a `lastAttemptError` from a previous failed attempt.
## Architecture
[Section titled “Architecture”](#architecture)
The dashboard is a self-contained package with two layers:
* **Backend**: A standard `fetch` handler powered by Hono (bundled internally). Serves API routes that query the Queuert client’s state adapter directly.
* **Frontend**: A SolidJS single-page application, pre-built as static JS/CSS and shipped within the package. No external build steps required at deploy time.
The dashboard works with the PostgreSQL and SQLite state adapters, which implement the required listing methods.
## Authentication
[Section titled “Authentication”](#authentication)
The dashboard does not include authentication or authorization. To restrict access, add middleware before the dashboard handler:
```ts
const server = serve({
fetch: (request) => {
if (!isAuthenticated(request)) {
return new Response("Unauthorized", { status: 401 });
}
return dashboard.fetch(request);
},
port: 3000,
});
```
See [dashboard](https://github.com/kvet/queuert/tree/main/examples/dashboard) for a complete example.
## See Also
[Section titled “See Also”](#see-also)
* [Job & Chain Queries](/queuert/guides/queries/) — Client query methods used by the dashboard
# Notify Adapters
> Redis, NATS, and PostgreSQL notification adapters.
Notify adapters handle pub/sub notifications for efficient job scheduling. When a job is created, workers are notified immediately instead of polling. This reduces latency from seconds to milliseconds.
* Redis
**Package:** `@queuert/redis`
Recommended for production. Uses Redis pub/sub for broadcasting job notifications to workers. Includes a hint-based optimization using Lua scripts for atomic decrement, preventing thundering herd when many workers are idle — only as many workers as there are new jobs will query the database.
```bash
npm install @queuert/redis
```
### Supported clients
[Section titled “Supported clients”](#supported-clients)
| Client | Example |
| ------------------ | --------------------------------------------------------------------------------------------------------------------- |
| node-redis | [notify-redis-redis](https://github.com/kvet/queuert/tree/main/examples/notify-redis-redis) |
| ioredis | [notify-redis-ioredis](https://github.com/kvet/queuert/tree/main/examples/notify-redis-ioredis) |
| node-redis cluster | [notify-redis-cluster-node-redis](https://github.com/kvet/queuert/tree/main/examples/notify-redis-cluster-node-redis) |
| ioredis cluster | [notify-redis-cluster-ioredis](https://github.com/kvet/queuert/tree/main/examples/notify-redis-cluster-ioredis) |
* NATS
**Package:** `@queuert/nats` Experimental
Uses NATS pub/sub for job notifications. When JetStream KV is available, supports revision-based CAS operations for hint-based optimization.
```bash
npm install @queuert/nats
```
| Client | Example |
| ------ | --------------------------------------------------------------------------------------- |
| nats | [notify-nats-nats](https://github.com/kvet/queuert/tree/main/examples/notify-nats-nats) |
* PostgreSQL LISTEN/NOTIFY
**Package:** `@queuert/postgres`
Uses PostgreSQL’s built-in `LISTEN`/`NOTIFY` mechanism. No additional infrastructure beyond your existing PostgreSQL database. All listeners query the database on notification (no hint-based optimization).
```bash
npm install @queuert/postgres
```
### Supported drivers
[Section titled “Supported drivers”](#supported-drivers)
| Driver | Example |
| ----------- | ------------------------------------------------------------------------------------------------------------- |
| pg | [notify-postgres-pg](https://github.com/kvet/queuert/tree/main/examples/notify-postgres-pg) |
| postgres.js | [notify-postgres-postgres-js](https://github.com/kvet/queuert/tree/main/examples/notify-postgres-postgres-js) |
* In-process
**Built-in** — no extra package. Imported from `queuert`.
Delivers job-arrival signals via in-memory subscriptions. Useful whenever publisher and subscriber run in the same process. Single-process only — workers in other processes won’t receive notifications.
```ts
import { createInProcessNotifyAdapter } from "queuert";
const notifyAdapter = await createInProcessNotifyAdapter();
```
* None (polling)
The default when no notify adapter is configured. Workers poll the database on a configurable interval to check for new jobs. No additional packages or infrastructure required.
Tip
Polling is a perfectly valid choice for low-throughput workloads where millisecond latency is not critical. It eliminates an entire infrastructure dependency and simplifies local development.
## Notify Provider
[Section titled “Notify Provider”](#notify-provider)
A Notify Provider bridges your pub/sub client (Redis, NATS, PostgreSQL, etc.) with the notify adapter. You implement an interface for publishing messages and subscribing to channels:
* **`publish`** — Sends a message to a named channel.
* **`subscribe`** — Listens on a channel and invokes a callback when messages arrive. Returns a dispose function to unsubscribe.
The provider maintains a dedicated connection for subscriptions and acquires/releases connections for publish operations automatically. Each example linked above demonstrates a complete Notify Provider implementation for its corresponding client.
You’re not limited to the clients listed here — you can write a provider for any pub/sub client that supports the same semantics, or implement the `NotifyAdapter` interface from scratch for an entirely different message broker. See [Custom Adapters](/queuert/advanced/custom-adapters/) for a walkthrough.
## Verify your provider
[Section titled “Verify your provider”](#verify-your-provider)
Queuert ships a conformance runner that exercises the full notify adapter suite against any provider you build. Embed it in a single `test()` block from your test framework to validate correctness:
```ts
import { runNotifyAdapterConformance } from "queuert/conformance";
test("my provider passes notify adapter conformance", async () => {
await runNotifyAdapterConformance(async () => ({
notifyAdapter,
dispose: async () => { /* close connections */ },
}));
}, 60_000);
```
Every example’s `src/provider.spec.ts` is a working template. See the [Custom Adapters](/queuert/advanced/custom-adapters/) guide for a full walkthrough and the [Conformance reference](/queuert/reference/queuert/conformance/) for the complete API.
## See Also
[Section titled “See Also”](#see-also)
* [Adapter Architecture](/queuert/advanced/adapters/) — NotifyAdapter design and broadcast semantics
* [Horizontal Scaling](/queuert/guides/horizontal-scaling/) — Multi-worker coordination via notifications
# Observability
> OpenTelemetry metrics and tracing for Queuert job chains.
Queuert provides an OpenTelemetry adapter for metrics collection. Configure your OTEL SDK with desired exporters (Prometheus, OTLP, Jaeger, etc.) before using this adapter.
1. Install the package:
```bash
npm install @queuert/otel
```
2. Create the observability adapter with your OTEL meter and tracer:
```ts
import { createOtelObservabilityAdapter } from "@queuert/otel";
import { metrics, trace } from "@opentelemetry/api";
const observabilityAdapter = await createOtelObservabilityAdapter({
meter: metrics.getMeter("my-app"), // Optional — metrics disabled if omitted
tracer: trace.getTracer("my-app"), // Optional — tracing disabled if omitted
});
```
3. Pass the adapter when creating your client:
```ts
const client = await createClient({
stateAdapter,
jobTypes,
observabilityAdapter,
log: createConsoleLog(),
});
```
The adapter emits:
* **Counters:** worker lifecycle, job attempts, completions, errors
* **Histograms:** job duration, chain duration, attempt duration
* **Gauges:** idle workers per job type, jobs being processed
## Adapter architecture
[Section titled “Adapter architecture”](#adapter-architecture)
The `ObservabilityAdapter` interface provides pluggable observability with two mechanisms:
* **Metrics** — Counters, histograms, and gauges for quantitative monitoring. All methods accept primitive data types (strings, numbers, booleans) rather than domain objects, decoupling observability from internal types and ensuring stability across versions.
* **Tracing** — Distributed spans for end-to-end visibility into chain execution. Uses a handle-based lifecycle: `startJobSpan` and `startAttemptSpan` return handles for managing span lifecycle. Spans follow OpenTelemetry messaging conventions with PRODUCER spans for job creation and CONSUMER spans for processing.
When no adapter is provided, a noop implementation is used automatically, making observability fully opt-in.
## Transactional guarantees
[Section titled “Transactional guarantees”](#transactional-guarantees)
Note
Observability events emitted inside database transactions are buffered and only flushed after the transaction commits. If the transaction rolls back, buffered events are discarded — no misleading metrics or spans leak out. This uses the same `TransactionHooks` mechanism that guards notify events.
See [observability-otel](https://github.com/kvet/queuert/tree/main/examples/observability-otel) for a complete example.
## See Also
[Section titled “See Also”](#see-also)
* [OTEL Metrics](/queuert/advanced/otel-metrics/) — Full list of counters, histograms, and gauges
* [OTEL Tracing](/queuert/advanced/otel-tracing/) — Span hierarchy and attributes
* [OTEL Internals](/queuert/advanced/otel-internals/) — Adapter architecture, W3C context propagation, and transactional buffering
* [Transaction Hooks](/queuert/guides/transaction-hooks/) — How buffering works
# State Adapters
> PostgreSQL and SQLite database adapters.
State adapters abstract database operations for job persistence. They handle job creation, status transitions, leasing, and queries. Queuert ships three options: PostgreSQL for production workloads, SQLite for lightweight or embedded use cases, and an in-process adapter for single-process apps that don’t need persistence.
* PostgreSQL
**Package:** `@queuert/postgres`
Recommended for production. Supports horizontal scaling with database-level locking (`FOR UPDATE SKIP LOCKED`), writeable CTEs for atomic batch operations, and all Queuert features including concurrent multi-worker deployments.
```bash
npm install @queuert/postgres
```
### Supported ORMs and drivers
[Section titled “Supported ORMs and drivers”](#supported-orms-and-drivers)
| ORM / Driver | Example |
| ------------ | ----------------------------------------------------------------------------------------------------------- |
| Raw pg | [state-postgres-pg](https://github.com/kvet/queuert/tree/main/examples/state-postgres-pg) |
| postgres.js | [state-postgres-postgres-js](https://github.com/kvet/queuert/tree/main/examples/state-postgres-postgres-js) |
| Prisma | [state-postgres-prisma](https://github.com/kvet/queuert/tree/main/examples/state-postgres-prisma) |
| Drizzle | [state-postgres-drizzle](https://github.com/kvet/queuert/tree/main/examples/state-postgres-drizzle) |
| Kysely | [state-postgres-kysely](https://github.com/kvet/queuert/tree/main/examples/state-postgres-kysely) |
* SQLite
**Package:** `@queuert/sqlite` Experimental
Suitable for local development, CLI tools, and embedded applications. SQLite’s exclusive transaction locking model serializes all writes, so batch operations use sequential queries within a single transaction rather than writeable CTEs.
```bash
npm install @queuert/sqlite
```
### Supported drivers
[Section titled “Supported drivers”](#supported-drivers)
| Driver | Example |
| -------------- | ------------------------------------------------------------------------------------------------------------- |
| node:sqlite | [state-sqlite-node](https://github.com/kvet/queuert/tree/main/examples/state-sqlite-node) |
| bun:sqlite | [state-sqlite-bun](https://github.com/kvet/queuert/tree/main/examples/state-sqlite-bun) |
| better-sqlite3 | [state-sqlite-better-sqlite3](https://github.com/kvet/queuert/tree/main/examples/state-sqlite-better-sqlite3) |
| Prisma | [state-sqlite-prisma](https://github.com/kvet/queuert/tree/main/examples/state-sqlite-prisma) |
| Drizzle | [state-sqlite-drizzle](https://github.com/kvet/queuert/tree/main/examples/state-sqlite-drizzle) |
| Kysely | [state-sqlite-kysely](https://github.com/kvet/queuert/tree/main/examples/state-sqlite-kysely) |
* In-process
**Built-in** — no extra package. Imported from `queuert`.
All state is held in memory and lost on process exit. Serializable transactions via an internal lock (same isolation model as SQLite), with per-type ordered sets and per-chain maps so acquisition and chain lookups work against type/chain-scoped collections rather than scanning all jobs. Single-process only — not for multi-worker deployments.
```ts
import { createInProcessStateAdapter } from "queuert";
const stateAdapter = await createInProcessStateAdapter();
```
## State Provider
[Section titled “State Provider”](#state-provider)
A State Provider bridges your database client (Kysely, Drizzle, Prisma, raw drivers, etc.) with the state adapter. You implement a simple interface that provides transaction handling and SQL execution:
* **`withTransaction`** — Manages connection acquisition and transaction lifecycle. The callback receives a transaction context representing an active transaction.
* **`executeSql`** — Executes SQL statements. When a transaction context is provided, uses that connection; when omitted, acquires and releases its own connection from the pool.
Each example linked above demonstrates a complete State Provider implementation for its corresponding ORM or driver.
You’re not limited to the ORMs and drivers listed here — you can write a provider for any database client that supports the same semantics, or implement the `StateAdapter` interface from scratch for an entirely different database engine. See [Custom Adapters](/queuert/advanced/custom-adapters/) for a walkthrough.
## Verify your provider
[Section titled “Verify your provider”](#verify-your-provider)
Queuert ships a conformance runner that exercises the full state adapter suite against any provider you build. Embed it in a single `test()` block from your test framework to validate correctness:
```ts
import { runStateAdapterConformance } from "queuert/conformance";
test("my provider passes state adapter conformance", async () => {
await runStateAdapterConformance(async () => ({
stateAdapter,
poisonTransaction,
reset: async () => { /* truncate tables */ },
dispose: async () => { /* close connections */ },
}));
}, 300_000);
```
Every example’s `src/provider.spec.ts` is a working template. See the [Custom Adapters](/queuert/advanced/custom-adapters/) guide for a full walkthrough and the [Conformance reference](/queuert/reference/queuert/conformance/) for the complete API.
## Multi-worker deployment
[Section titled “Multi-worker deployment”](#multi-worker-deployment)
For horizontal scaling, multiple worker processes can share the same PostgreSQL database. Workers coordinate via `FOR UPDATE SKIP LOCKED` — no external coordination required.
See [state-postgres-multi-worker](https://github.com/kvet/queuert/tree/main/examples/state-postgres-multi-worker) for an example spawning multiple worker processes sharing a PostgreSQL database.
## See Also
[Section titled “See Also”](#see-also)
* [Adapter Architecture](/queuert/advanced/adapters/) — StateAdapter design, context architecture, and provider interfaces
* [Horizontal Scaling](/queuert/guides/horizontal-scaling/) — Multi-worker deployment guide
# Validation Adapters
> Schema-agnostic runtime validation with Zod, Valibot, TypeBox, or ArkType.
Queuert’s runtime validation follows an adapter pattern. The core provides `createJobTypes`, which accepts raw validation functions. Schema-specific adapters (Zod, Valibot, TypeBox, ArkType) are implemented in user-land, wrapping their respective schema libraries into the `JobTypes` interface.
Each adapter:
1. Accepts schema definitions in the library’s native format
2. Infers `TJobTypeDefinitions` from the schemas (providing the same compile-time safety as `defineJobTypes`)
3. Calls `createJobTypes` with validation functions that delegate to the schema library
## `defineJobTypes` vs `createJobTypes`
[Section titled “defineJobTypes vs createJobTypes”](#definejobtypes-vs-createjobtypes)
`defineJobTypes` is a lightweight type-only helper. It provides compile-time type inference with zero runtime cost — no validation functions are executed. Use it when your inputs come from trusted internal code.
`createJobTypes` adds runtime validation on top of compile-time types. It accepts validation functions for entry checks, input/output parsing, continuation validation, and blocker validation. Use it when your job inputs originate from external sources (APIs, webhooks, user input) where compile-time guarantees alone are insufficient.
## `JobTypes` Interface
[Section titled “JobTypes Interface”](#jobtypes-interface)
The `JobTypes` object validates at each boundary:
| Job Type Definition | Method | Purpose |
| -------------------------- | ---------------------- | -------------------------------------------- |
| *(all)* | `getTypeNames` | Returns known type names (for merge/routing) |
| `entry?: boolean` | `validateEntry` | Validates job type can start a chain |
| `input: unknown` | `parseInput` | Parses and validates job input |
| `output?: unknown` | `parseOutput` | Parses and validates job output |
| `continueWith?: Reference` | `validateContinueWith` | Validates continuation target |
| `blockers?: Reference[]` | `validateBlockers` | Validates blocker references |
## Error Handling
[Section titled “Error Handling”](#error-handling)
All validation errors throw `JobTypeValidationError` with:
* `code`: Error type (`'invalid_input'`, `'invalid_output'`, `'invalid_continuation'`, `'invalid_blockers'`, `'not_entry_point'`)
* `typeName`: The job type that failed validation
* `message`: Human-readable error message
* `details`: Additional context (original error, input value, etc.)
Note
Errors thrown by the underlying schema library are caught by `createJobTypes` and wrapped in `JobTypeValidationError` with the appropriate error code, so consumers always handle a single error type regardless of which validation library is used.
## Example Adapters
[Section titled “Example Adapters”](#example-adapters)
Complete adapter implementations for each library:
* [Zod](https://github.com/kvet/queuert/tree/main/examples/validation-zod)
* [Valibot](https://github.com/kvet/queuert/tree/main/examples/validation-valibot)
* [TypeBox](https://github.com/kvet/queuert/tree/main/examples/validation-typebox)
* [ArkType](https://github.com/kvet/queuert/tree/main/examples/validation-arktype)
## Conformance Testing
[Section titled “Conformance Testing”](#conformance-testing)
Custom validation adapters can be validated against Queuert’s conformance suite via `runValidationAdapterConformance` from `queuert/conformance`. The suite combines runtime checks (six-method contract, error wrapping) with type-level checks (schema-to-shape inference) — the fixture’s builder return types enforce the type contract at the call site, so inference bugs surface as compile errors before the runtime suite runs. See [Custom Adapters](/queuert/advanced/custom-adapters/) for the full pattern.
## See Also
[Section titled “See Also”](#see-also)
* [Runtime Validation Guide](/queuert/guides/runtime-validation/) — When to use runtime validation
* [Chain Patterns](/queuert/guides/chain-patterns/) — Continuation references and patterns
* [Custom Adapters](/queuert/advanced/custom-adapters/) — Building and validating a custom validation adapter
* [Conformance Reference](/queuert/reference/queuert/conformance/) — Runner API and fixture types
# @queuert/dashboard
> Web dashboard for monitoring Queuert.
Caution
This package is experimental and may change without notice.

## createDashboard
[Section titled “createDashboard”](#createdashboard)
```typescript
const dashboard = await createDashboard({
client: Client, // Queuert client from createClient()
basePath?: string, // Mount prefix without trailing slash (e.g. '/internal/queuert')
});
// Returns:
// {
// fetch: (request: Request) => Response | Promise
// }
```
The `fetch` handler serves both API routes and the pre-built SolidJS frontend. Mount it on any server runtime that accepts a standard `fetch` handler (Node.js, Bun, Deno).
The state adapter must implement dashboard listing methods (`listChains`, `listJobs`, `listBlockedJobs`). The PostgreSQL and SQLite adapters support these.
### options.basePath
[Section titled “options.basePath”](#optionsbasepath)
Mount prefix for sub-path deployments. Set this when the dashboard is served behind a reverse proxy or framework router at a path other than `/`. The value should not include a trailing slash.
```typescript
const dashboard = await createDashboard({
client,
basePath: "/internal/queuert",
});
```
## Performance
[Section titled “Performance”](#performance)
Chain listing joins each root row with the last job in the chain. Filtering by `status` is not optimized — always pass `typeName` to narrow the scan. See [Performance considerations](/queuert/guides/queries/#performance-considerations).
## See Also
[Section titled “See Also”](#see-also)
* [Dashboard](/queuert/integrations/dashboard/) — Integration guide for the dashboard
# @queuert/nats
> NATS notify adapter.
Caution
This package is experimental and may change without notice.
## createNatsNotifyAdapter
[Section titled “createNatsNotifyAdapter”](#createnatsnotifyadapter)
```typescript
const notifyAdapter = await createNatsNotifyAdapter({
nc: NatsConnection, // NATS connection from the 'nats' package
kv?: KV, // Optional JetStream KV for thundering herd optimization (see below)
subjectPrefix?: string, // Subject prefix (default: "queuert")
});
```
Returns `Promise`.
No provider type is exported — NATS accepts the `NatsConnection` directly. There is only one NATS client in the Node.js ecosystem, so no adapter layer is needed.
When **kv** is provided, the adapter uses a JetStream KV store to deduplicate notifications so that only one worker wakes up per scheduled job instead of all workers simultaneously (thundering herd prevention).
## See Also
[Section titled “See Also”](#see-also)
* [Notify Adapters](/queuert/integrations/notify-adapters/) — Integration guide for notify adapters
* [Adapter Architecture](/queuert/advanced/adapters/) — Design philosophy and context management
# @queuert/otel
> OpenTelemetry observability adapter.
## createOtelObservabilityAdapter
[Section titled “createOtelObservabilityAdapter”](#createotelobservabilityadapter)
```typescript
const observabilityAdapter = await createOtelObservabilityAdapter({
meter?: Meter, // From @opentelemetry/api — metrics disabled if omitted
tracer?: Tracer, // From @opentelemetry/api — tracing disabled if omitted
});
```
Returns `Promise`.
Both parameters are optional. When neither is provided, all observability operations are noops. Provide `meter` for metrics, `tracer` for distributed tracing, or both.
## See Also
[Section titled “See Also”](#see-also)
* [Observability](/queuert/integrations/observability/) — Integration guide for observability
* [OTEL Metrics](/queuert/advanced/otel-metrics/) — Counters, histograms, and gauges
* [OTEL Tracing](/queuert/advanced/otel-tracing/) — Span hierarchy and messaging conventions
* [OTEL Internals](/queuert/advanced/otel-internals/) — Adapter architecture, W3C context propagation, and transactional buffering
# @queuert/postgres
> PostgreSQL state and notify adapters.
## createPgStateAdapter
[Section titled “createPgStateAdapter”](#createpgstateadapter)
```typescript
const stateAdapter = await createPgStateAdapter({
stateProvider: PgStateProvider, // You implement this
schema?: string, // PostgreSQL schema name (default: "public")
tablePrefix?: string, // Table name prefix (default: "queuert_")
idType?: string, // SQL type for job IDs (default: "uuid")
generateId?: () => string, // Generates new IDs in JS (default: () => crypto.randomUUID())
validateId?: (id: string) => boolean, // Optional predicate; runs on generated and caller-supplied IDs
});
```
Returns `Promise`.
## PgStateAdapter
[Section titled “PgStateAdapter”](#pgstateadapter)
**PgStateAdapter** — `StateAdapter` extended with migration support:
```typescript
type PgStateAdapter = StateAdapter & {
migrateToLatest: () => Promise;
};
```
## PgStateProvider
[Section titled “PgStateProvider”](#pgstateprovider)
**PgStateProvider** — you implement this to bridge your PostgreSQL client:
```typescript
type PgStateProvider = {
withTransaction: (fn: (txCtx: TTxContext) => Promise) => Promise;
withSavepoint?: (txCtx: TTxContext, fn: (txCtx: TTxContext) => Promise) => Promise;
executeSql: (options: {
txCtx?: TTxContext;
id?: string; // Stable cache key for prepared statements; unique per resolved SQL (omitted for one-off SQL)
sql: string;
params: unknown[];
paramTypes: Record; // Positional param runtime types
columnTypes: Record; // Column runtime types for result rows
readOnly: boolean; // true for pure SELECTs (no FOR UPDATE)
}) => Promise;
close?: () => Promise; // Optional. Pass-through providers can omit it; when defined, must be idempotent.
};
```
`withSavepoint` is optional. When not provided, the adapter uses raw `SAVEPOINT` SQL via `executeSql`. Override it when your driver tracks transaction state client-side (e.g. `postgres.js` — use `txCtx.sql.savepoint()`).
`id` is a stable cache key — the adapter folds template variants (e.g. `schema`, `tablePrefix`) into the suffix, so it uniquely identifies the resolved SQL within a provider instance. Providers MAY use it directly as the prepared-statement name (`pg`: `query.name = id`) or as a flag to opt into driver-level caching (`postgres.js`: `prepare: true`). When omitted, the provider must execute the statement unprepared.
`paramTypes` / `columnTypes` are type hints for drivers that don’t auto-serialize/parse (e.g. `postgres.js` `unsafe()`). Drivers that handle these natively (e.g. `pg`) can ignore them.
`readOnly` lets providers route to a read replica or a separate reader pool. The built-in pool / `postgres.js` providers ignore it.
## RuntimeType
[Section titled “RuntimeType”](#runtimetype)
Runtime tag describing each parameter or column type. Providers use it to drive serialization (for parameters) and parsing (for columns). Optional variants (`string?`, `uuid?`, etc.) accept `null`:
```typescript
type RuntimeType =
| "string"
| "number"
| "boolean"
| "uuid"
| "json"
| "array"
| "jsonArray"
| "string?"
| "number?"
| "boolean?"
| "uuid?"
| "json?"
| "date?";
```
## createPgNotifyAdapter
[Section titled “createPgNotifyAdapter”](#createpgnotifyadapter)
```typescript
const notifyAdapter = await createPgNotifyAdapter({
notifyProvider: PgNotifyProvider, // You implement this
channelPrefix?: string, // Channel prefix (default: "queuert")
});
```
Returns `Promise`.
## PgNotifyProvider
[Section titled “PgNotifyProvider”](#pgnotifyprovider)
**PgNotifyProvider** — you implement this to bridge your PostgreSQL client:
```typescript
type PgNotifyProvider = {
publish: (channel: string, message: string) => Promise;
subscribe: (
channel: string,
onMessage: (message: string) => void,
) => Promise<() => Promise>;
close?: () => Promise; // Optional. Pass-through providers can omit it; when defined, must be idempotent.
};
```
## MigrationResult
[Section titled “MigrationResult”](#migrationresult)
```typescript
type MigrationResult = {
applied: string[]; // Migrations applied in this run
skipped: string[]; // Already-applied migrations
unrecognized: string[]; // Unknown migrations found in the database
};
```
## See Also
[Section titled “See Also”](#see-also)
* [State Adapters](/queuert/integrations/state-adapters/) — Integration guide for state adapters
* [Notify Adapters](/queuert/integrations/notify-adapters/) — Integration guide for notify adapters
* [Adapter Architecture](/queuert/advanced/adapters/) — Design philosophy and context management
# Client
> Client API, mutating/read-only methods, and client-related types for the queuert core package.
## createClient
[Section titled “createClient”](#createclient)
```typescript
const client = await createClient({
stateAdapter: StateAdapter,
notifyAdapter?: NotifyAdapter,
observabilityAdapter?: ObservabilityAdapter,
jobTypes: JobTypes,
log?: Log,
});
```
Returns `Promise`.
* **stateAdapter** — database adapter for job persistence
* **notifyAdapter** — optional pub/sub adapter for real-time notifications between client and workers
* **observabilityAdapter** — optional adapter for metrics and tracing
* **jobTypes** — job type registry created by `defineJobTypes()` or `createJobTypes()`
* **log** — optional structured logger
## Client — Mutating Methods
[Section titled “Client — Mutating Methods”](#client--mutating-methods)
All mutating methods require `transactionHooks` and a transaction context (`tx`). Side effects are buffered via hooks and flushed after commit.
### startChain
[Section titled “startChain”](#startchain)
```typescript
const chain = await client.startChain({
typeName: "send-email",
input: { to: "alice@..." },
transactionHooks,
tx,
id?: JobId,
deduplication?: DeduplicationOptions,
schedule?: ScheduleOptions,
blockers?: Chain[],
});
```
Returns `Chain & { deduplicated: boolean }`.
### startChains
[Section titled “startChains”](#startchains)
```typescript
const chains = await client.startChains({
items: [
{ typeName: "send-email", input: { to: "alice@..." } },
{ typeName: "send-email", id: "explicit-id", input: { to: "bob@..." } },
],
transactionHooks,
tx,
});
```
Returns `Array`.
### deleteChain
[Section titled “deleteChain”](#deletechain)
```typescript
const deleted = await client.deleteChain({
id: chainId,
cascade?: boolean,
transactionHooks,
tx,
});
```
Returns `Chain | undefined`.
Deletes a single chain by ID. Returns the deleted chain, or `undefined` if no chain with that ID exists. When **cascade** is `true`, transitive dependencies are included (default: `false`). Throws `BlockerReferenceError` if external jobs depend on it.
### deleteChains
[Section titled “deleteChains”](#deletechains)
```typescript
const deleted = await client.deleteChains({
ids: [chainId1, chainId2],
cascade?: boolean,
transactionHooks,
tx,
});
```
Returns `Chain[]`.
Deletes the specified chains. Missing IDs are silently skipped (use `deleteChain` for strict lookup). When **cascade** is `true`, transitive dependencies are included (default: `false`). Throws `BlockerReferenceError` if external jobs depend on the targeted chains.
### triggerJob
[Section titled “triggerJob”](#triggerjob)
```typescript
const job = await client.triggerJob({
id: jobId,
transactionHooks,
tx,
});
```
Returns `Job`.
Triggers a pending job immediately by setting its `scheduledAt` to now. Throws `JobNotFoundError` if the job does not exist, `JobNotTriggerableError` if the job is not pending.
### triggerJobs
[Section titled “triggerJobs”](#triggerjobs)
```typescript
const jobs = await client.triggerJobs({
ids: [jobId1, jobId2],
transactionHooks,
tx,
});
```
Returns `Job[]` in input order.
Triggers multiple pending jobs in one call. Validation is atomic — if any job is missing or not pending, the entire call fails with `JobNotFoundError` or `JobNotTriggerableError` before any job is triggered. Empty `ids` returns `[]`.
### completeChain
[Section titled “completeChain”](#completechain)
```typescript
const chain = await client.completeChain({
typeName: "send-email",
id: chainId,
transactionHooks,
tx,
complete: async ({ job, complete }) => {
return complete(job, async ({ continueWith }) => {
return { sent: true };
});
},
});
```
Returns `CompletedChain` when the chain is completed, or `Chain` when continued via `continueWith`.
The **complete** callback receives the current (latest) job in the chain. Call `complete(job, callback)` to finalize the job. Inside the callback, return an output value to finish the chain, or call `continueWith({ typeName, input })` to schedule the next job in the chain.
Throws `ChainNotFoundError`, `JobTypeMismatchError`, or `JobAlreadyCompletedError`.
## Client — Read-Only Methods
[Section titled “Client — Read-Only Methods”](#client--read-only-methods)
Read-only methods accept an optional transaction context. When omitted, the adapter acquires its own connection.
### getChain
[Section titled “getChain”](#getchain)
```typescript
const chain = await client.getChain({
id: chainId,
typeName?: "send-email",
});
```
Returns `Chain | undefined`.
When **typeName** is provided, the return type is narrowed to that job type. Throws `JobTypeMismatchError` if the chain exists but has a different type.
### getJob
[Section titled “getJob”](#getjob)
```typescript
const job = await client.getJob({
id: jobId,
typeName?: "send-email",
});
```
Returns `Job | undefined`.
When **typeName** is provided, the return type is narrowed to that job type.
### awaitChain
[Section titled “awaitChain”](#awaitchain)
```typescript
const completed = await client.awaitChain(
{ id: chainId, typeName?: "send-email" },
{
timeoutMs: 30_000,
pollIntervalMs?: 15_000,
signal?: AbortSignal,
},
);
```
Returns `CompletedChain`.
Waits for the specified chain to complete.
* **timeoutMs** — required, maximum wait time
* **pollIntervalMs** — polling fallback interval (default: `15_000`)
* **signal** — optional `AbortSignal` for external cancellation
Throws `WaitChainTimeoutError` on timeout or abort, `ChainNotFoundError`, or `JobTypeMismatchError`.
### listChains
[Section titled “listChains”](#listchains)
```typescript
const page = await client.listChains({
filter?: {
typeName?: string[],
status?: JobStatus[],
chainId?: string[],
jobId?: string[],
root?: boolean,
from?: Date,
to?: Date,
},
orderDirection?: "asc" | "desc",
cursor?: string,
limit?: number,
});
```
Returns `Page`.
Paginated listing of chains. **root** filters to only root chains (not blockers). Default **orderDirection** is `"desc"`. Default **limit** is `50`.
### listJobs
[Section titled “listJobs”](#listjobs)
```typescript
const page = await client.listJobs({
filter?: {
typeName?: string[],
status?: JobStatus[],
jobId?: string[],
chainTypeName?: string[],
chainId?: string[],
from?: Date,
to?: Date,
},
orderDirection?: "asc" | "desc",
cursor?: string,
limit?: number,
});
```
Returns `Page`.
Paginated listing of jobs. **chainTypeName** filters to jobs belonging to chains started by the given entry type names. Default **orderDirection** is `"desc"`. Default **limit** is `50`.
### listChainJobs
[Section titled “listChainJobs”](#listchainjobs)
```typescript
const page = await client.listChainJobs({
chainId: chainId,
typeName?: "send-email",
orderDirection?: "asc" | "desc",
cursor?: string,
limit?: number,
});
```
Returns `Page`.
Lists all jobs within a specific chain. Default **orderDirection** is `"asc"`. Default **limit** is `50`.
### getJobBlockers
[Section titled “getJobBlockers”](#getjobblockers)
```typescript
const blockers = await client.getJobBlockers({
jobId: jobId,
typeName?: "send-email",
});
```
Returns `Chain[]`.
Returns the blocker chains for a given job. The result is not paginated because blockers are bounded by design.
### listBlockedJobs
[Section titled “listBlockedJobs”](#listblockedjobs)
```typescript
const page = await client.listBlockedJobs({
chainId: chainId,
typeName?: "send-email",
orderDirection?: "asc" | "desc",
cursor?: string,
limit?: number,
});
```
Returns `Page`.
Lists jobs that are blocked by the specified chain. Default **orderDirection** is `"desc"`. Default **limit** is `50`.
## Types
[Section titled “Types”](#types)
### DeduplicationOptions
[Section titled “DeduplicationOptions”](#deduplicationoptions)
```typescript
type DeduplicationOptions = {
key: string;
scope?: "incomplete" | "any"; // default: "incomplete"
windowMs?: number; // required when scope is "any"
excludeChainIds?: TJobId[];
};
```
Chain deduplication configuration passed to `startChain`.
* **key** — identifies the logical operation
* **scope** — match incomplete chains only (`"incomplete"`, the default) or all chains within the time window (`"any"`)
* **windowMs** — required when scope is `"any"`
* **excludeChainIds** — chain IDs to exclude from deduplication matching; useful for recurring jobs that self-schedule within a completion callback where the current chain is still incomplete
### ScheduleOptions
[Section titled “ScheduleOptions”](#scheduleoptions)
```typescript
type ScheduleOptions = { at: Date; afterMs?: never } | { at?: never; afterMs: number };
```
Deferred job scheduling. The two fields are mutually exclusive.
* **at** — schedules for an absolute timestamp
* **afterMs** — schedules relative to the current time
### Page
[Section titled “Page”](#page)
```typescript
type Page = {
items: T[];
nextCursor: string | null; // null when no more pages
};
```
Cursor-based pagination wrapper returned by all list methods. Pass **nextCursor** back as the `cursor` parameter to fetch the next page.
### OrderDirection
[Section titled “OrderDirection”](#orderdirection)
```typescript
type OrderDirection = "asc" | "desc";
```
Controls sort order in list queries. Most list methods default to `"desc"`.
## See Also
[Section titled “See Also”](#see-also)
* [Worker](/queuert/reference/queuert/worker/) — Worker configuration and job processing
* [Entities](/queuert/reference/queuert/entities/) — `Job`, `Chain`, and resolved variants
* [Utilities](/queuert/reference/queuert/utilities/) — Composition helpers and utility functions
* [Transaction Hooks](/queuert/reference/queuert/transaction-hooks/) — Transaction hooks API reference
* [Errors](/queuert/reference/queuert/errors/) — Error classes reference
* [Transaction Hooks Guide](/queuert/guides/transaction-hooks/) — Usage guide
# Conformance
> Test-framework-agnostic runner for validating custom state, notify, and validation adapters against Queuert's conformance suites.
Queuert’s conformance test suites are available as a test-framework-agnostic runner so you can validate a custom state, notify, or validation adapter from inside any `test()` block (vitest, bun test, `node:test`, etc.). The runner has zero external dependencies — assertions are backed by `node:assert`.
Import from the `queuert/conformance` subpath:
```typescript
import {
runNotifyAdapterConformance,
runStateAdapterConformance,
runValidationAdapterConformance,
ConformanceError,
type ConformanceReport,
} from "queuert/conformance";
```
## runNotifyAdapterConformance
[Section titled “runNotifyAdapterConformance”](#runnotifyadapterconformance)
Runs the notify adapter conformance suite against a user-supplied `NotifyAdapter`. Accepts a factory function that sets up the adapter and returns a fixture:
```typescript
await runNotifyAdapterConformance(async () => ({
notifyAdapter,
dispose: async () => {
/* close clients */
},
}));
```
Returns `Promise`. Throws `ConformanceError` (with an aggregated report) if any case fails.
The factory is called once. The returned `dispose` runs after all cases regardless of outcome.
## runStateAdapterConformance
[Section titled “runStateAdapterConformance”](#runstateadapterconformance)
Runs the state adapter conformance suite against a user-supplied `StateAdapter`. Accepts a factory function that sets up the adapter and returns a fixture:
```typescript
await runStateAdapterConformance(async () => ({
stateAdapter: adapter,
poisonTransaction: async (txCtx) => {
/* force a transaction abort */
},
reset: async () => {
/* truncate tables between cases */
},
dispose: async () => {
/* close connections, stop containers */
},
}));
```
* **poisonTransaction** — optional. Forces the active transaction into an aborted state (e.g., PostgreSQL `SELECT 1 FROM nonexistent_table`). Required for backends that support mid-transaction poisoning (PostgreSQL). Cases that need it are reported with `status: "skip"` when the hook is omitted. SQLite does not support mid-transaction poisoning — omit this field.
The factory is called once. `reset` runs before each case to restore a clean slate (e.g., truncate tables). `dispose` runs after all cases regardless of outcome.
## runValidationAdapterConformance
[Section titled “runValidationAdapterConformance”](#runvalidationadapterconformance)
Runs the validation adapter conformance suite against a user-supplied validation adapter (a thin wrapper around a schema library like Zod, Valibot, ArkType, or TypeBox). Accepts a factory function that returns a fixture of typed builders:
```typescript
await runValidationAdapterConformance(async () => ({
basic: { buildEntry, buildNonEntry, buildContinuationOnly },
continuations: { buildNominal, buildStructural },
blockers: { buildNominal, buildStructural },
external: { buildWithExternalSlice, buildWithExternalSlices },
}));
```
Unlike state and notify conformance — which test a fixed runtime interface — validation adapters are wrappers whose primary value is **type inference** (`z.infer`, `Static<>`, etc.). Each builder’s return type is precisely specified, so the adapter’s schema-to-shape mapper must thread inference correctly to satisfy the fixture type at the runner call site. This makes the suite a combined runtime AND type-level conformance check.
Returns `Promise`. Throws `ConformanceError` on any case failure.
The factory is called once. The optional `dispose` runs after all cases regardless of outcome.
## ValidationConformanceFixture
[Section titled “ValidationConformanceFixture”](#validationconformancefixture)
```typescript
type ValidationConformanceFixture = {
dispose?: () => Promise;
basic: {
buildEntry: () => JobTypes;
buildNonEntry: () => JobTypes;
buildContinuationOnly: () => JobTypes;
};
continuations: {
buildNominal: () => JobTypes;
buildStructural: () => JobTypes;
};
blockers: {
buildNominal: () => JobTypes;
buildStructural: () => JobTypes;
};
external: {
buildWithExternalSlice: () => JobTypes<
/* orders.* slice */,
/* notifications.* external slice */
>;
buildWithExternalSlices: () => JobTypes<
/* orders.* slice */,
/* notifications.* & payments.* external slices passed as a readonly array */
>;
};
};
```
Each builder constructs a registry of a precise shape using the adapter under test. The exact phantom defs each builder must produce are encoded in the return types — see [`ValidationConformanceFixture`](https://github.com/kvet/queuert/blob/main/packages/core/src/conformance/validation-adapter-cases.ts) for the full annotated definitions.
Conformance verifies the wrapper layer only — the six runtime methods (`getTypeNames`, `validateEntry`, `parseInput`, `parseOutput`, `validateContinueWith`, `validateBlockers`) and how core’s `createJobTypes` wraps thrown errors into `JobTypeValidationError`. Compile-time validation rules (like rejecting blockers that reference continuation-only types) live in core’s `ValidatedJobTypeDefinitions` and are tested there — the positive type checks above are sufficient to prove the adapter feeds them correctly.
## StateConformanceFixture
[Section titled “StateConformanceFixture”](#stateconformancefixture)
```typescript
type StateConformanceFixture = {
stateAdapter: StateAdapter;
generateId?: () => string;
generateInvalidId?: () => string;
poisonTransaction?: (txCtx: any) => Promise;
reset?: () => Promise;
dispose?: () => Promise;
};
```
## NotifyConformanceFixture
[Section titled “NotifyConformanceFixture”](#notifyconformancefixture)
```typescript
type NotifyConformanceFixture = {
notifyAdapter: NotifyAdapter;
reset?: () => Promise;
dispose?: () => Promise;
};
```
## Options
[Section titled “Options”](#options)
All three runners accept an optional second argument with the same shape:
```typescript
type StateConformanceOptions = {
caseTimeoutMs?: number;
onResult?: (result: ConformanceResult) => void;
};
```
* **caseTimeoutMs** — optional per-case timeout on the case body. When exceeded, the case is marked failed with a timeout error.
* **onResult** — fires after each case completes. Useful for streaming progress to the user’s test reporter.
## ConformanceReport
[Section titled “ConformanceReport”](#conformancereport)
```typescript
type ConformanceReport = {
total: number;
passed: number;
failed: number;
skipped: number;
results: ConformanceResult[];
};
type ConformanceResult = {
name: string;
status: "pass" | "fail" | "skip";
error?: Error;
cleanupError?: Error;
skipReason?: string;
durationMs: number;
};
```
Returned on a fully successful run. On any failure, `ConformanceError` is thrown instead — the full report is accessible via `err.report`.
A case is marked `"skip"` when it declines to run — for example, when a state adapter omits `poisonTransaction` for a backend that cannot support mid-transaction poisoning (SQLite). `skipReason` carries the explanation; `error` is left unset.
`cleanupError` is populated when the `cleanup` callback throws. For cases where the body passed, a cleanup failure flips the result to `"fail"` and is reported in `error`. For cases where the body already failed, the cleanup failure is preserved in `cleanupError` alongside the original `error` so neither is lost.
## ConformanceError
[Section titled “ConformanceError”](#conformanceerror)
```typescript
class ConformanceError extends Error {
readonly report: ConformanceReport;
}
```
Thrown when one or more cases fail. `error.message` is a human-readable summary with failed case names and their assertion messages, plus any cleanup failures from passing or failing cases. `error.cause` is an `AggregateError` preserving the original thrown errors (and their stack traces) so IDEs and CI tools can still render them.
## Expect
[Section titled “Expect”](#expect)
The runner passes a minimal `Expect` shim to each case’s `run` callback. It covers the matchers used by the conformance suites and is backed by `node:assert/strict`:
* `.toBe`, `.toEqual`, `.toBeDefined`, `.toBeUndefined`, `.toBeNull`
* `.toBeGreaterThan`, `.toBeGreaterThanOrEqual`, `.toBeLessThan`, `.toBeLessThanOrEqual`
* `.toBeInstanceOf`, `.toContain`, `.toHaveLength`
* `.toThrow`
* `.not.` negation of all the above
* `.rejects.toThrow`
* `expect.poll(fn, { timeout, interval }).toBe(value)` / `.toEqual(value)`
* `expect.fail(message)`
This shim is internal to case execution — you don’t need to import it to use `runNotifyAdapterConformance` / `runStateAdapterConformance`.
## See Also
[Section titled “See Also”](#see-also)
* [Custom Adapters](/queuert/advanced/custom-adapters/) — writing and testing custom adapters with vitest, bun test, and `node:test` examples
* [State Adapters](/queuert/integrations/state-adapters/) — building a custom state provider
* [Notify Adapters](/queuert/integrations/notify-adapters/) — building a custom notify provider
# Entities
> Core entity types — Job, Chain, and resolved variants — for the queuert core package.
## Job
[Section titled “Job”](#job)
```typescript
type Job = {
id: TJobId;
chainId: TJobId;
typeName: TJobTypeName;
chainTypeName: TChainTypeName;
chainIndex: number;
input: TInput;
createdAt: Date;
scheduledAt: Date;
attempt: number;
lastAttemptAt: Date | null;
lastAttemptError: string | null;
} & (
| { status: "blocked" }
| { status: "pending" }
| { status: "running"; leasedBy?: string; leasedUntil?: Date }
| { status: "completed"; completedAt: Date; completedBy: string | null; output: TOutput }
);
```
A discriminated union on **status**. All jobs carry their chain identity via **chainId** and **chainTypeName**, and their position via **chainIndex**. The **running** variant includes lease metadata. The **completed** variant includes completion timestamps, the worker identity, and the job’s **output**.
## JobStatus
[Section titled “JobStatus”](#jobstatus)
```typescript
type JobStatus = "blocked" | "pending" | "running" | "completed";
```
The four possible job states. Used in list filters and discriminated union narrowing.
## ResolvedJob
[Section titled “ResolvedJob”](#resolvedjob)
```typescript
type ResolvedJob;
```
A `Job` whose generic parameters have been resolved against job type definitions — typed input, output, and chain type name derived from the declared job types. Returned by client read methods like `getJob` and `listJobs` when narrowed by `typeName`.
## ResolvedJobWithBlockers
[Section titled “ResolvedJobWithBlockers”](#resolvedjobwithblockers)
```typescript
type ResolvedJobWithBlockers<
TJobId,
TJobTypeDefinitions,
TJobTypeName extends string,
TChainTypeName extends string = JobTypeReachingEntry,
> = ResolvedJob & {
blockers: CompletedBlockerChains;
};
```
A `ResolvedJob` extended with resolved blocker chains. **blockers** contains the completed blocker chain data, available inside worker handlers when the job type declares blockers.
## Chain
[Section titled “Chain”](#chain)
```typescript
type Chain = {
id: TJobId;
typeName: TChainTypeName;
input: TInput;
createdAt: Date;
} & (
| { status: "blocked" }
| { status: "pending" }
| { status: "running" }
| { status: "completed"; output: TOutput; completedAt: Date }
);
```
A discriminated union on **status**. Represents the full lifecycle of a chain from creation to completion. The **completed** variant includes the chain output and completion timestamp.
## ChainStatus
[Section titled “ChainStatus”](#chainstatus)
```typescript
type ChainStatus = "blocked" | "pending" | "running" | "completed";
```
The four possible chain states. Used in list filters and discriminated union narrowing.
## CompletedChain
[Section titled “CompletedChain”](#completedchain)
```typescript
type CompletedChain> = TChain & {
status: "completed";
};
```
`Chain` narrowed to `status: "completed"`. Guarantees the presence of **output** and **completedAt** fields.
## ResolvedChain
[Section titled “ResolvedChain”](#resolvedchain)
```typescript
type ResolvedChain;
```
A `Chain` whose generic parameters have been resolved against job type definitions — typed input, output, and type name derived from the declared job types. Returned by client read methods like `getChain` and `listChains` when narrowed by `typeName`.
## See Also
[Section titled “See Also”](#see-also)
* [Client](/queuert/reference/queuert/client/) — Client API reference
* [Worker](/queuert/reference/queuert/worker/) — Worker and job processing reference
* [Utilities](/queuert/reference/queuert/utilities/) — Composition helpers and job-type-system types
* [Errors](/queuert/reference/queuert/errors/) — Error classes reference
* [Core Concepts](/queuert/getting-started/core-concepts/) — Chain model introduction
* [Chain Patterns](/queuert/guides/chain-patterns/) — Continuation references and patterns
# Errors
> Error classes for the queuert core package.
All error classes extend `Error`. Properties listed are `readonly`.
## JobNotFoundError
[Section titled “JobNotFoundError”](#jobnotfounderror)
```typescript
class JobNotFoundError extends Error {
readonly jobId: string | undefined;
}
```
Thrown when a job cannot be found by ID.
## ChainNotFoundError
[Section titled “ChainNotFoundError”](#chainnotfounderror)
```typescript
class ChainNotFoundError extends Error {
readonly chainId: string | undefined;
}
```
Thrown when a chain cannot be found by ID. Raised by `awaitChain` and `completeChain`. Deletion APIs do not throw this: `deleteChain` returns `undefined` for missing chains, and `deleteChains` silently skips missing IDs.
## JobAlreadyCompletedError
[Section titled “JobAlreadyCompletedError”](#jobalreadycompletederror)
```typescript
class JobAlreadyCompletedError extends Error {
readonly jobId: string | undefined;
}
```
Thrown when attempting to complete a job that is already completed.
## JobNotTriggerableError
[Section titled “JobNotTriggerableError”](#jobnottriggerableerror)
```typescript
class JobNotTriggerableError extends Error {
readonly jobId: string | undefined;
readonly status: string | undefined;
}
```
Thrown by `triggerJob` and `triggerJobs` when a job is not in a triggerable state. Only `pending` jobs can be triggered. `triggerJobs` validates atomically — it throws on the first invalid job before triggering any.
## JobTakenByAnotherWorkerError
[Section titled “JobTakenByAnotherWorkerError”](#jobtakenbyanotherworkererror)
```typescript
class JobTakenByAnotherWorkerError extends Error {
readonly jobId: string | undefined;
readonly workerId: string | undefined;
readonly leasedBy: string | null | undefined;
}
```
Thrown during job processing when another worker has acquired the job’s lease.
## JobTypeMismatchError
[Section titled “JobTypeMismatchError”](#jobtypemismatcherror)
```typescript
class JobTypeMismatchError extends Error {
readonly expectedTypeName: string;
readonly actualTypeName: string;
}
```
Thrown when a **typeName** parameter doesn’t match the actual type of a job or chain.
## JobTypeValidationError
[Section titled “JobTypeValidationError”](#jobtypevalidationerror)
```typescript
class JobTypeValidationError extends Error {
readonly code: JobTypeValidationErrorCode;
readonly typeName: string;
readonly details: Record;
}
type JobTypeValidationErrorCode =
| "not_entry_point"
| "invalid_continuation"
| "invalid_blockers"
| "invalid_input"
| "invalid_output";
```
Thrown by `createJobTypes` when runtime validation fails.
* **code** — identifies the specific validation failure
* **typeName** — the job type that failed validation
* **details** — additional context about the failure
## WaitChainTimeoutError
[Section titled “WaitChainTimeoutError”](#waitchaintimeouterror)
```typescript
class WaitChainTimeoutError extends Error {
readonly chainId: string | undefined;
readonly timeoutMs: number | undefined;
}
```
Thrown by `awaitChain` when the timeout expires or the signal is aborted.
## RescheduleJobError
[Section titled “RescheduleJobError”](#reschedulejoberror)
```typescript
class RescheduleJobError extends Error {
readonly schedule: ScheduleOptions;
}
```
Thrown by the `rescheduleJob` helper to reschedule a job from within an attempt handler. The worker catches this and reschedules the job automatically.
## BlockerReferenceError
[Section titled “BlockerReferenceError”](#blockerreferenceerror)
```typescript
class BlockerReferenceError extends Error {
readonly references: readonly BlockerReference[];
}
type BlockerReference = {
chainId: string;
referencedByJobId: string;
};
```
Thrown by `deleteChains` when external chains depend on the deletion targets as blockers. **references** lists each dependency, pairing the blocker **chainId** with the **referencedByJobId** that depends on it.
## DuplicateJobTypeError
[Section titled “DuplicateJobTypeError”](#duplicatejobtypeerror)
```typescript
class DuplicateJobTypeError extends Error {
readonly duplicateTypeNames: readonly string[];
}
```
Thrown by `createClient` (when merging an array of `JobTypes` slices) and `createInProcessWorker` (when merging an array of `Processors` slices) if slices have overlapping type names. **duplicateTypeNames** lists the conflicting keys.
## UnknownJobTypeError
[Section titled “UnknownJobTypeError”](#unknownjobtypeerror)
```typescript
class UnknownJobTypeError extends Error {
readonly typeName: string;
readonly registeredTypeNames: readonly string[];
}
```
Thrown by a merged `JobTypes` (built from an array of slices passed to `createClient`) when an operation references a type name that no slice owns. Only raised when every slice in the merge was built with `createJobTypes` — mixed merges that include a `defineJobTypes` slice keep no-op pass-through semantics for unknown types.
* **typeName** — the type that no slice claimed
* **registeredTypeNames** — the type names registered across the merged slices, useful for diagnosing typos
## HookNotRegisteredError
[Section titled “HookNotRegisteredError”](#hooknotregisterederror)
```typescript
class HookNotRegisteredError extends Error {
readonly key: symbol;
}
```
Thrown when a transaction hook is accessed before being registered.
## TransactionContextRequiredError
[Section titled “TransactionContextRequiredError”](#transactioncontextrequirederror)
```typescript
class TransactionContextRequiredError extends Error {}
```
Thrown when a mutating client method (e.g. `startChain`, `triggerJob`, `triggerJobs`, `deleteChain`, `deleteChains`) is called without a transaction context provided by `withTransaction`. Mutations must run inside a transaction so the transactional outbox pattern holds.
## InvalidJobIdError
[Section titled “InvalidJobIdError”](#invalidjobiderror)
```typescript
class InvalidJobIdError extends Error {
readonly id: string;
readonly source: "generator" | "caller";
}
```
Thrown when a job ID fails the state adapter’s `validateId` predicate. `source` is `"generator"` when the adapter’s `generateId` produced the invalid value and `"caller"` when the caller supplied it (via `startChain({ id })`, `continueWith({ id })`, etc.).
## See Also
[Section titled “See Also”](#see-also)
* [Client](/queuert/reference/queuert/client/) — Client API reference
* [Worker](/queuert/reference/queuert/worker/) — Worker and job processing reference
* [Entities](/queuert/reference/queuert/entities/) — `Job`, `Chain`, and resolved variants
* [Utilities](/queuert/reference/queuert/utilities/) — Composition helpers and utility functions
* [Error Handling](/queuert/guides/error-handling/) — Error handling patterns guide
# Transaction Hooks
> Transaction hooks API for buffering side effects during database transactions.
## withTransactionHooks
[Section titled “withTransactionHooks”](#withtransactionhooks)
```typescript
await withTransactionHooks(async (transactionHooks) => {
await db.transaction(async (tx) => {
await client.startChain({ tx, transactionHooks, ... });
});
});
```
The recommended approach. Automatically flushes buffered side effects on success and discards them on error.
## createTransactionHooks
[Section titled “createTransactionHooks”](#createtransactionhooks)
```typescript
const { transactionHooks, flush, discard } = createTransactionHooks();
try {
await db.transaction(async (tx) => {
await client.startChain({ tx, transactionHooks, ... });
});
await flush();
} catch {
await discard();
}
```
Manual lifecycle for advanced use cases. Call `flush()` after the transaction commits to emit buffered side effects. Call `discard()` on error to drop them.
## TransactionHooks
[Section titled “TransactionHooks”](#transactionhooks)
```typescript
type TransactionHooks = {
set(key: symbol, hook: HookDefinition): void;
getOrInsert(key: symbol, factory: () => HookDefinition): T;
get(key: symbol): T;
has(key: symbol): boolean;
delete(key: symbol): void;
withSavepoint(fn: (transactionHooks: TransactionHooks) => T | Promise): Promise;
createSavepoint(): TransactionHooksSavepoint;
};
```
The hooks container passed to all mutating client methods. Manages keyed hook definitions that buffer side effects during a transaction.
* **withSavepoint** — runs `fn` inside a savepoint. Automatically rolls back buffered hook state on error and releases on success.
* **createSavepoint** — creates a manual savepoint for fine-grained control. Returns a `TransactionHooksSavepoint` handle.
## TransactionHooksSavepoint
[Section titled “TransactionHooksSavepoint”](#transactionhookssavepoint)
```typescript
type TransactionHooksSavepoint = {
transactionHooks: TransactionHooks;
rollback(): void;
release(): void;
};
```
A savepoint handle returned by `createSavepoint()`. Call `rollback()` to restore hook state to the point when the savepoint was created, or `release()` to keep the current state.
## HookDefinition
[Section titled “HookDefinition”](#hookdefinition)
```typescript
type HookDefinition = {
state: T;
flush: (state: T) => void | Promise;
discard?: (state: T) => void | Promise;
checkpoint?: (state: T) => () => void;
};
```
Defines a single hook’s state and lifecycle callbacks.
* **state** — mutable state accumulated during the transaction
* **flush** — called with the accumulated state after the transaction commits. Hooks flush concurrently across keys, so order across distinct hooks is not guaranteed; serialize inside `flush` if you need ordering.
* **discard** — called on rollback to clean up without executing side effects. Same concurrency rules as `flush`.
* **checkpoint** — called when a savepoint is created. Returns a rollback function that restores the state to the checkpoint. Used by `withSavepoint` and `createSavepoint` to support partial rollback of hook state.
## TransactionHooksHandle
[Section titled “TransactionHooksHandle”](#transactionhookshandle)
```typescript
type TransactionHooksHandle = {
transactionHooks: TransactionHooks;
flush: () => Promise;
discard: () => Promise;
};
```
Returned by `createTransactionHooks()`. Provides the `transactionHooks` instance along with explicit `flush` and `discard` controls.
## See Also
[Section titled “See Also”](#see-also)
* [Client](/queuert/reference/queuert/client/) — Client API reference
* [Transaction Hooks Guide](/queuert/guides/transaction-hooks/) — Usage guide
# Utilities
> Composition helpers, factory functions, and job-type-system types for the queuert core package.
## defineJobTypes
[Section titled “defineJobTypes”](#definejobtypes)
```typescript
const jobTypes = defineJobTypes<{
"send-email": {
entry: true;
input: { to: string; subject: string };
output: { sent: true };
};
"process-attachment": {
input: { fileUrl: string };
output: { processedUrl: string };
continueWith: { typeName: "send-email" };
};
}>();
```
Creates a compile-time-only type registry. No runtime validation is performed. The returned object carries type information used by `createClient` and `createInProcessWorker` to infer input, output, and chain-flow types.
An optional second type parameter `TExternal` allows `blockers` to reference job types from other slices without owning them:
```typescript
const orderJobTypes = defineJobTypes<
{
"orders.confirm": {
input: { orderId: string };
output: { confirmed: boolean };
blockers: [{ typeName: "notifications.send" }];
};
},
// External types — available for blocker reference validation, not owned
JobTypeDefinitions
>();
```
* `T` = owned definitions (become the registry’s phantom type via `JobTypeDefinitions`)
* `TExternal` = read-only reference context (defaults to `Record`)
* `blockers` and `continueWith` references validate against `T` plus `TExternal` (distributively when `TExternal` is a union of slices, so a reference matching any one slice is accepted)
* The registry’s phantom type remains `T` only
## createJobTypes
[Section titled “createJobTypes”](#createjobtypes)
```typescript
const registry = createJobTypes({
getTypeNames: () => Object.keys(schemas),
validateEntry: (typeName) => { ... },
parseInput: (typeName, input) => { ... },
parseOutput: (typeName, output) => { ... },
validateContinueWith: (typeName, target) => { ... },
validateBlockers: (typeName, blockers) => { ... },
});
```
Creates a registry with runtime validation for input/output parsing. Each callback is invoked at the appropriate lifecycle point. Use this when you need schema validation (e.g. with Zod) beyond compile-time checks. Accepts an optional `TExternal` type parameter for cross-slice blocker reference validation (compile-time only, same as `defineJobTypes`).
* **getTypeNames** — returns the known job type names; used by `createClient` for runtime duplicate detection and deterministic routing when merging slices
## createProcessors
[Section titled “createProcessors”](#createprocessors)
```typescript
const orderProcessors = createProcessors({
client,
jobTypes,
processors: {
"orders.create": {
attemptHandler: async ({ job, complete }) => complete(async () => ({ orderId: "123" })),
},
},
});
```
Defines a processor registry. Handlers are type-checked against the client’s full job type definitions — the returned registry may implement any subset of those types. Cross-slice `continueWith` / blocker references resolve against the client’s merged defs, so no slice-level wiring is needed.
* **client** — a `Client` instance; its type parameters drive handler inference (state adapter + job types)
* **processors** — the processor map, typed against the client’s definitions
* **attemptMiddleware** — optional middleware tuple applied to every handler in this registry. Ctx injected via `next(ctx)` is typed into each `attemptHandler`, `prepareCallback`, and `completeCallback` option bag. Runs in onion order (first middleware outermost).
* **backoffConfig** — default backoff for every processor in this registry. Overridden by the per-processor value. Falls back to the library default when absent (10s initial, 2× multiplier, 5min max).
* **leaseConfig** — default lease for every processor in this registry. Overridden by the per-processor value. Falls back to the library default when absent (60s lease, 30s renewal).
* **Return type** — a `Processors` carrying the client’s definitions via phantom symbols
## createInProcessStateAdapter
[Section titled “createInProcessStateAdapter”](#createinprocessstateadapter)
```typescript
import { createInProcessStateAdapter } from "queuert";
const stateAdapter = await createInProcessStateAdapter();
```
Creates a state adapter that holds all jobs and chains in memory. Suitable for:
* Single-process production apps that don’t need state persistence across restarts
* Testing and examples
* Development and prototyping
Transactions are serializable (one-at-a-time) via an internal async lock — the same isolation model as SQLite’s single-writer mode. Operations use per-`typeName` ordered sets and per-`chainId` maps, so acquisition, scheduling, and chain lookups work against small type/chain-scoped collections rather than scanning all jobs.
For multi-process deployments or state that must survive restarts, use a database-backed adapter (`@queuert/postgres`, `@queuert/sqlite`).
## createInProcessNotifyAdapter
[Section titled “createInProcessNotifyAdapter”](#createinprocessnotifyadapter)
```typescript
import { createInProcessNotifyAdapter } from "queuert";
const notifyAdapter = await createInProcessNotifyAdapter();
```
Creates a notify adapter that delivers job-arrival signals via in-process subscriptions. Useful whenever publisher and subscriber run in the same process — single-process apps, tests, and examples. For multi-process deployments, use `@queuert/postgres` (LISTEN/NOTIFY), `@queuert/redis` (pub/sub), or `@queuert/nats`.
## createConsoleLog
[Section titled “createConsoleLog”](#createconsolelog)
```typescript
const log = createConsoleLog();
```
Creates a simple console logger suitable for development. For production, implement a custom `Log` function that integrates with your logging library.
## rescheduleJob
[Section titled “rescheduleJob”](#reschedulejob)
Helper that throws `RescheduleJobError` from within an attempt handler to reschedule the job.
```typescript
function rescheduleJob(schedule: ScheduleOptions, cause?: unknown): never;
```
```typescript
attemptHandler: async ({ job, complete }) => {
if (!isReady()) {
rescheduleJob({ afterMs: 30_000 });
}
return complete(async () => ({ done: true }));
},
```
## Types
[Section titled “Types”](#types)
### JobTypes
[Section titled “JobTypes”](#jobtypes)
```typescript
type JobTypes> = {
readonly getTypeNames: () => readonly string[];
validateEntry: (typeName: string) => void;
parseInput: (typeName: string, input: unknown) => unknown;
parseOutput: (typeName: string, output: unknown) => unknown;
validateContinueWith: (typeName: string, target: ResolvedJobTypeReference) => void;
validateBlockers: (typeName: string, blockers: readonly ResolvedJobTypeReference[]) => void;
readonly [definitionsSymbol]: TJobTypeDefinitions;
readonly [externalDefinitionsSymbol]: TExternalJobTypeDefinitions;
};
```
The registry object accepted by `createClient` and `createInProcessWorker`.
* **getTypeNames** — returns the known type names; noop registries return `[]`, validated registries delegate to the config
* **validateEntry** — throws if the type name is not marked as an entry point
* **parseInput** / **parseOutput** — parse and return validated data, throwing on invalid shapes
* **validateContinueWith** / **validateBlockers** — verify chain-flow references at runtime
### BaseJobTypeDefinition
[Section titled “BaseJobTypeDefinition”](#basejobtypedefinition)
```typescript
type BaseJobTypeDefinition = {
entry?: boolean; // true for chain entry points
input: unknown; // Job input data type
output?: unknown; // Job output data type (terminal jobs)
continueWith?: JobTypeReference; // Next job in the chain
blockers?: readonly JobTypeReference[]; // External chain dependencies
};
```
The shape of each job type in the type map passed to `defineJobTypes` or `createJobTypes`.
### JobTypeDefinitions
[Section titled “JobTypeDefinitions”](#jobtypedefinitions)
```typescript
type JobTypeDefinitions> = T[typeof definitionsSymbol];
```
Utility type that extracts the phantom job type definitions from a single `JobTypes` slice. Constrains its argument to `JobTypes`, so passing a non-slice is a compile error at the call site — use this when you know you have a slice and want that type-level assertion. For the slice-or-array form (e.g. an adapter parameter that may accept either), use [`JobTypesDefinitions`](#jobtypesdefinitions) instead.
```typescript
const jobTypes = defineJobTypes<{
"send-email": { entry: true; input: { to: string }; output: { sent: true } };
}>();
type MyDefs = JobTypeDefinitions;
// { "send-email": { entry: true; input: { to: string }; output: { sent: true } } }
```
### JobTypesDefinitions
[Section titled “JobTypesDefinitions”](#jobtypesdefinitions)
```typescript
type JobTypesDefinitions<
T extends JobTypes | readonly JobTypes[],
>;
```
Resolves a value that may be either a single `JobTypes` slice or a `readonly` array of slices into its definitions. Validation-adapter authors thread this through the optional `externalDefinitions` parameter so callers can compose multiple external slices the same way `createClient` accepts `jobTypes`. When you know you have a single slice and want a compile-time assertion to that effect, use [`JobTypeDefinitions`](#jobtypedefinitions) instead.
```typescript
export const createMyJobTypes = <
const T extends Record,
const TExternal extends
| JobTypes
| readonly JobTypes[] = readonly [],
>(
schemas: [Infer] extends [
ValidatedJobTypeDefinitions, JobTypesDefinitions>,
]
? T
: JobTypeDefinitionErrors, JobTypesDefinitions>,
_externalDefinitions?: TExternal,
) =>
createJobTypes, JobTypesDefinitions>({
/* ... */
});
```
Empty default (`readonly []`) maps to `Record` so callers can omit the param entirely.
### Processors
[Section titled “Processors”](#processors)
Processor registry returned by `createProcessors`. Carries the client’s job type definitions and per-entry attempt middleware via phantom symbols. Pass one or an array of them to `createInProcessWorker`.
### ProcessorDefinitions
[Section titled “ProcessorDefinitions”](#processordefinitions)
```typescript
type ProcessorDefinitions;
```
Utility type that extracts the job type definitions carried on a `Processors` registry via its phantom symbol.
### Log
[Section titled “Log”](#log)
```typescript
type Log = (options: TypedLogEntry) => void;
```
Logger function type accepted by `createClient` and `createInProcessWorker`. Receives structured log entries with level, message, and contextual metadata. Implement a custom `Log` function to integrate with your logging library, or use `createConsoleLog()` for development.
## Adapter Interfaces
[Section titled “Adapter Interfaces”](#adapter-interfaces)
These interfaces are exported for adapter authors. Most users interact with adapters through factory functions from adapter packages.
**StateAdapter** abstracts database operations for job persistence. Generic over `TTxContext` (transaction context) and `TJobId` (ID type).
**NotifyAdapter** abstracts pub/sub notifications for worker coordination.
**ObservabilityAdapter** abstracts metrics and distributed tracing.
See [Adapter Architecture](/queuert/advanced/adapters/) for full interface definitions and design rationale.
## See Also
[Section titled “See Also”](#see-also)
* [Client](/queuert/reference/queuert/client/) — Client API reference
* [Worker](/queuert/reference/queuert/worker/) — Worker and job processing reference
* [Entities](/queuert/reference/queuert/entities/) — `Job`, `Chain`, and resolved variants
* [Errors](/queuert/reference/queuert/errors/) — Error classes reference
* [Adapter Architecture](/queuert/advanced/adapters/) — Full adapter interface definitions
# Worker
> Worker configuration, job processing, and worker-related types for the queuert core package.
## createInProcessWorker
[Section titled “createInProcessWorker”](#createinprocessworker)
```typescript
const worker = await createInProcessWorker({
client: Client,
workerName?: string,
concurrency?: number,
pollIntervalMs?: number,
recoveryBackoffConfig?: BackoffConfig,
defaults?: InProcessWorkerDefaults,
requiredAttemptMiddleware?: readonly AttemptMiddleware[],
processors: Processors,
});
```
Returns `Promise`.
* **client** — the Queuert client to process jobs for
* **workerName** — optional human-readable label included in the worker id. Must match `/^[A-Za-z0-9._-]+$/` when provided (letters, digits, `.`, `_`, `-`). The id is always suffixed with a random UUID (`${workerName}-${uuid}` or just `${uuid}` when omitted), so two replicas with the same name still get distinct ids and cannot collide on lease ownership
* **concurrency** — maximum number of jobs to process in parallel (default: 1)
* **pollIntervalMs** — how often the worker polls for new jobs when no notify adapter wakes it (default: 60s)
* **recoveryBackoffConfig** — recovery backoff for the worker loop itself (not job retries)
* **defaults** — fallback `backoffConfig` / `leaseConfig` for processors that don’t set their own. Resolution order is: processor → registry → worker `defaults` → library default
* **requiredAttemptMiddleware** — middleware instances that every dispatched processor’s slice must include as an in-order subsequence (additional middleware may appear before, between, or after them). Enforced at compile time against the slice middleware tuple inferred by `createProcessors`, and at runtime by reference identity (`===`). The worker does not execute this middleware itself — slices keep running their own chains; this option only enforces presence. Useful for guaranteeing cross-cutting concerns like auth, tracing, or logging are wired into every slice merged into the worker
* **processors** — a single `Processors` from `createProcessors`, or an array of slices to merge. See [Slices guide](/queuert/guides/slices/). Middleware is declared on the registry; see [Middleware guide](/queuert/guides/middleware/)
### InProcessWorkerDefaults
[Section titled “InProcessWorkerDefaults”](#inprocessworkerdefaults)
```typescript
type InProcessWorkerDefaults = {
backoffConfig?: BackoffConfig;
leaseConfig?: LeaseConfig;
};
```
Worker-level fallbacks applied to every processor that doesn’t declare its own `backoffConfig` / `leaseConfig` (whether directly on the processor or via the registry default in `createProcessors`).
## InProcessWorker — Methods
[Section titled “InProcessWorker — Methods”](#inprocessworker--methods)
### start
[Section titled “start”](#start)
```typescript
const stop = await worker.start();
await stop();
```
Begins polling for and processing jobs. Returns a `stop` function for graceful shutdown — `stop()` signals the worker to stop spawning new jobs, waits for in-flight jobs to finish, then resolves.
## Types
[Section titled “Types”](#types)
### InProcessWorker
[Section titled “InProcessWorker”](#inprocessworker)
```typescript
type InProcessWorker = {
start: () => Promise<() => Promise>;
};
```
The handle returned by `createInProcessWorker`.
### InProcessWorkerProcessor
[Section titled “InProcessWorkerProcessor”](#inprocessworkerprocessor)
```typescript
type InProcessWorkerProcessor = {
attemptHandler: AttemptHandler;
backoffConfig?: BackoffConfig;
leaseConfig?: LeaseConfig;
};
```
Configuration for processing a single job type. `backoffConfig` and `leaseConfig` override the registry-level defaults — resolution order is: processor → registry → library default.
### AttemptHandler
[Section titled “AttemptHandler”](#attempthandler)
```typescript
type AttemptHandler = (options: {
signal: TypedAbortSignal;
job: ResolvedJobWithBlockers & { status: "running" };
prepare: AttemptPrepare;
complete: AttemptComplete;
}) => Promise<(ResolvedJobWithBlockers & { status: "completed" }) | ContinuationJobs>;
```
The core function called for each job attempt.
* **signal** — typed `AbortSignal` whose `reason` is a `JobAbortReason`
* **job** — the running job with its typed input and resolved blockers
* **prepare** — controls the processing mode (atomic or staged). See the [Processing Modes guide](/queuert/guides/processing-modes/)
* **complete** — finalizes the job. Return the output to complete the chain, or call `continueWith` to extend it
### AttemptComplete
[Section titled “AttemptComplete”](#attemptcomplete)
The typed `complete` function provided to the attempt handler. Call it to finalize the job — either return the output to complete the chain, or call `continueWith` to extend it.
### AttemptCompleteCallback
[Section titled “AttemptCompleteCallback”](#attemptcompletecallback)
The callback passed to `complete()`. Receives `AttemptCompleteOptions` and returns the result.
### AttemptCompleteOptions
[Section titled “AttemptCompleteOptions”](#attemptcompleteoptions)
Options received by the complete callback: `continueWith` (to extend the chain), `transactionHooks`, and the transaction context.
### AttemptPrepare
[Section titled “AttemptPrepare”](#attemptprepare)
The typed `prepare` function provided to the attempt handler. Controls the processing mode and optionally runs a callback within the prepare transaction.
### AttemptPrepareCallback
[Section titled “AttemptPrepareCallback”](#attemptpreparecallback)
The callback passed to `prepare(options, callback)`. Receives the transaction context.
### AttemptPrepareOptions
[Section titled “AttemptPrepareOptions”](#attemptprepareoptions)
```typescript
type AttemptPrepareOptions = { mode: "atomic" | "staged" };
```
`"atomic"` runs prepare and complete in the same transaction. `"staged"` commits prepare first, then runs complete in a new transaction with lease renewal.
### AttemptMiddleware
[Section titled “AttemptMiddleware”](#attemptmiddleware)
```typescript
type AttemptMiddleware<
TStateAdapter,
THandlerCtx extends Record = {},
TPrepareCtx extends Record = {},
TCompleteCtx extends Record = {},
> = {
wrapHandler?: (opts: {
job: ResolvedJobWithBlockers & { status: "running" };
workerId: string;
next: (ctx: THandlerCtx) => Promise;
}) => Promise;
wrapPrepare?: (opts: {
job: ResolvedJobWithBlockers & { status: "running" };
next: (ctx: TPrepareCtx) => Promise;
// plus state-adapter-specific transaction context fields
}) => Promise;
wrapComplete?: (opts: {
job: ResolvedJobWithBlockers & { status: "running" };
transactionHooks: TransactionHooks;
next: (ctx: TCompleteCtx) => Promise;
// plus state-adapter-specific transaction context fields
}) => Promise;
};
```
Wraps job processing with cross-cutting logic. Each hook is optional — implement only the phases you need. The `next(ctx)` callback injects typed context that becomes available to the inner handler.
* **wrapHandler** — wraps the entire attempt handler. Injected ctx merges into `attemptHandler`’s options
* **wrapPrepare** — wraps the user-supplied `prepare` callback. Injected ctx merges into the callback’s options alongside the transaction context
* **wrapComplete** — wraps the user-supplied `complete` callback. Injected ctx merges into the callback’s options alongside `continueWith`, `transactionHooks`, and the transaction context
Multiple middleware compose as an onion — the first middleware’s “before” runs outermost. See the [Middleware guide](/queuert/guides/middleware/) for usage patterns.
### BackoffConfig
[Section titled “BackoffConfig”](#backoffconfig)
```typescript
type BackoffConfig = {
initialDelayMs: number;
maxDelayMs: number;
multiplier?: number; // Default: 2
};
```
Exponential backoff parameters.
* **initialDelayMs** — delay after the first failure
* **maxDelayMs** — caps the delay
* **multiplier** — controls exponential growth
### RetryConfig
[Section titled “RetryConfig”](#retryconfig)
```typescript
type RetryConfig = BackoffConfig & {
maxAttempts?: number;
};
```
Extends `BackoffConfig` with **maxAttempts**, the maximum number of retry attempts before the operation is abandoned.
### LeaseConfig
[Section titled “LeaseConfig”](#leaseconfig)
```typescript
type LeaseConfig = {
leaseMs: number;
renewIntervalMs: number;
};
```
Controls job lease duration and renewal.
* **leaseMs** — total lease time granted to a worker
* **renewIntervalMs** — how often the worker renews the lease before it expires
### TypedAbortSignal
[Section titled “TypedAbortSignal”](#typedabortsignal)
```typescript
type TypedAbortSignal = Omit & {
readonly reason: T | undefined;
};
```
An `AbortSignal` with a typed **reason**. Used in worker handlers to communicate why a job was aborted.
### JobAbortReason
[Section titled “JobAbortReason”](#jobabortreason)
```typescript
type JobAbortReason = "taken_by_another_worker" | "error" | "not_found" | "already_completed";
```
The possible abort reasons passed through `TypedAbortSignal` in worker job handlers.
* **taken\_by\_another\_worker** — the lease was lost to another worker
* **error** — an internal failure occurred
* **not\_found** — the job no longer exists
* **already\_completed** — the job was already completed
## See Also
[Section titled “See Also”](#see-also)
* [Client](/queuert/reference/queuert/client/) — Client API reference
* [Utilities](/queuert/reference/queuert/utilities/) — `createProcessors`, `defineJobTypes`, `createJobTypes`
* [Entities](/queuert/reference/queuert/entities/) — `Job`, `Chain`, and resolved variants
* [Errors](/queuert/reference/queuert/errors/) — error reference
* [In-Process Worker](/queuert/advanced/in-process-worker/) — Worker lifecycle and concurrency model
* [Job Processing](/queuert/advanced/job-processing/) — Transactional design and prepare/complete pattern
* [Processing Modes](/queuert/guides/processing-modes/) — Atomic vs staged processing guide
* [Middleware](/queuert/guides/middleware/) — Writing and composing attempt middleware
# @queuert/redis
> Redis notify adapter.
## createRedisNotifyAdapter
[Section titled “createRedisNotifyAdapter”](#createredisnotifyadapter)
```typescript
const notifyAdapter = await createRedisNotifyAdapter({
notifyProvider: RedisNotifyProvider, // You implement this
channelPrefix?: string, // Channel prefix (default: "queuert")
});
```
Returns `Promise`.
## RedisNotifyProvider
[Section titled “RedisNotifyProvider”](#redisnotifyprovider)
**RedisNotifyProvider** — you implement this. Note the `eval` method for Lua scripts (thundering herd optimization):
```typescript
type RedisNotifyProvider = {
publish: (channel: string, message: string) => Promise;
subscribe: (
channel: string,
onMessage: (message: string) => void,
) => Promise<() => Promise>;
eval: (script: string, keys: string[], args: string[]) => Promise;
close?: () => Promise; // Optional. Pass-through providers can omit it; when defined, must be idempotent.
};
```
Redis requires two separate connections because clients in subscribe mode cannot run other commands.
## See Also
[Section titled “See Also”](#see-also)
* [Notify Adapters](/queuert/integrations/notify-adapters/) — Integration guide for notify adapters
* [Adapter Architecture](/queuert/advanced/adapters/) — Design philosophy and context management
# @queuert/sqlite
> SQLite state adapter.
Caution
This package is experimental and may change without notice.
## createSqliteStateAdapter
[Section titled “createSqliteStateAdapter”](#createsqlitestateadapter)
```typescript
const stateAdapter = await createSqliteStateAdapter({
stateProvider: SqliteStateProvider, // You implement this
tablePrefix?: string, // Table name prefix (default: "queuert_")
idType?: string, // SQL type for job IDs (default: "TEXT")
generateId?: () => string, // ID generator (default: crypto.randomUUID())
validateId?: (id: string) => boolean, // Optional predicate; runs on generated and caller-supplied IDs
checkForeignKeys?: boolean, // Enable PRAGMA foreign_keys (default: true)
});
```
Returns `Promise`.
## SqliteStateAdapter
[Section titled “SqliteStateAdapter”](#sqlitestateadapter)
**SqliteStateAdapter** — `StateAdapter` extended with migration support, following the same pattern as `PgStateAdapter`:
```typescript
type SqliteStateAdapter = StateAdapter & {
migrateToLatest: () => Promise;
};
```
## SqliteStateProvider
[Section titled “SqliteStateProvider”](#sqlitestateprovider)
**SqliteStateProvider** — you implement this to bridge your SQLite client (`node:sqlite`, `bun:sqlite`, `better-sqlite3`, ORMs, etc.). Note the extra `columnTypes` parameter compared to `PgStateProvider`:
```typescript
type SqliteStateProvider = {
withTransaction: (fn: (txCtx: TTxContext) => Promise) => Promise;
withSavepoint?: (txCtx: TTxContext, fn: (txCtx: TTxContext) => Promise) => Promise;
executeSql: (options: {
txCtx?: TTxContext;
id?: string; // Stable cache key for `db.prepare(sql)` handles; unique per resolved SQL (omitted for one-off SQL)
sql: string;
params: unknown[];
paramTypes: Record; // Positional param runtime types
columnTypes: Record; // Non-empty when the query returns rows
readOnly: boolean; // true for pure SELECTs (no FOR UPDATE)
}) => Promise;
close?: () => Promise; // Optional. Pass-through providers can omit it; when defined, must be idempotent.
};
```
The adapter pre-serializes non-primitive values, so the built-in `better-sqlite3` and `node:sqlite` providers ignore `paramTypes`. It exists for custom providers backed by drivers that need explicit type hints (e.g. remote SQLite bridges).
## RuntimeType
[Section titled “RuntimeType”](#runtimetype)
Runtime tag describing each parameter or column type. Providers use it to drive serialization (for parameters) and parsing (for columns). Optional variants (`string?`, `uuid?`, etc.) accept `null`:
```typescript
type RuntimeType =
| "string"
| "number"
| "boolean"
| "uuid"
| "json"
| "array"
| "jsonArray"
| "string?"
| "number?"
| "boolean?"
| "uuid?"
| "json?"
| "date?";
```
## createAsyncRwLock / AsyncRwLock / LockHandle
[Section titled “createAsyncRwLock / AsyncRwLock / LockHandle”](#createasyncrwlock--asyncrwlock--lockhandle)
Re-exported from `queuert/internal`. SQLite requires serialized write access but permits concurrent reads. If your application performs writes outside of Queuert (e.g., in your state provider), use `createAsyncRwLock` to coordinate access so that your writes and Queuert’s writes don’t conflict:
```typescript
import { createAsyncRwLock } from "@queuert/sqlite";
const lock = createAsyncRwLock();
// Exclusive (writer) — blocks readers and other writers
{
using _h = await lock.acquireWrite();
// Serialized write access
}
// Shared (reader) — concurrent with other readers, blocks writers
{
using _h = await lock.acquireRead();
// Concurrent read access
}
```
Handles implement `Symbol.dispose`, so `using` releases at scope exit. You can also call `handle.release()` manually. Release is idempotent.
## MigrationResult
[Section titled “MigrationResult”](#migrationresult)
Same type as `@queuert/postgres`:
```typescript
type MigrationResult = {
applied: string[]; // Migrations applied in this run
skipped: string[]; // Already-applied migrations
unrecognized: string[]; // Unknown migrations found in the database
};
```
## See Also
[Section titled “See Also”](#see-also)
* [State Adapters](/queuert/integrations/state-adapters/) — Integration guide for state adapters
* [Adapter Architecture](/queuert/advanced/adapters/) — Design philosophy and context management